LinkedHashSet是Set集合的一个实现,具有set集合不重复的特点,同时具有可预测的迭代顺序,也就是我们插入的顺序。
并且linkedHashSet是一个非线程安全的集合。如果有多个线程同时访问当前linkedhashset集合容器,并且有一个线程对当前容器中的元素做了修改,那么必须要在外部实现同步保证数据的冥等性。
下面我们new一个新的LinkedHashSet容器看一下具体的源码实现。并分析师如何保证数据的插入顺序:
Set<String> set = new LinkedHashSet<>();
跟进LinkedHashSet可以得到super一个父类初始化为一个容器为16大小,加载因子为0.75的Map容器。
构造一个空连接散列集合
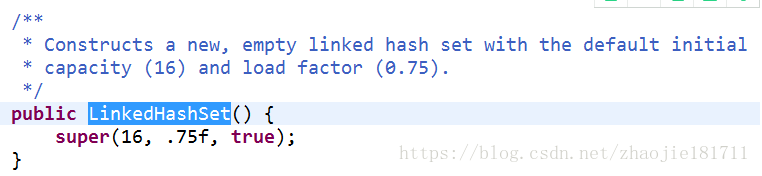

实际创建的是一个LinkedHashMap带有制定大小和加载因子的容器。
在前面讲过一次,map的容器的大小必须是2的冥,那么在讲一次如何保证必须是2的冥,通过我们传入的参数在构建map集合的是通过位运算实现:

其中initialCapacity为我们传入的具体按容器的大小。
上面是我们描述的LinkedHashSet的具体构建过程,以及构建的具体内容。
由于LinkedHashSet是一个哈希表和链表的结合,且是一个双向链表,那么我们来看一下什么是双向连边?
双向链表是链表的一种,他的每个数据节点都有两个指针分别指向直接后继和直接前驱,所以从双向链表的任意一个节点开始都可以很方便的访问它的前驱节点和后继节点。这是双向链表的优点,那么有优点就有缺点,缺点是每个节点都需要保存当前节点的next和prev两个属性,这样才能保证优点。所以需要更多的内存开销,并且删除和添加也会比较费时间。
下面我们图示一个双向两表的节点:

多个节点相互连接,保证了数据录入的顺序。
那么我们源码分析一下具体的录入详情:
我们定义一个LinkedHashSet---LinkedHashSet<String> set = new LinkedHashSet<>();
然后set.add();跟一下这个add是走的那个方法:

跟进来走的是put的方法:LinkedHashSet.class下的,这个是重写了超类中put的具体add方法。他会在新分配的元素在链表的末尾插入一条。
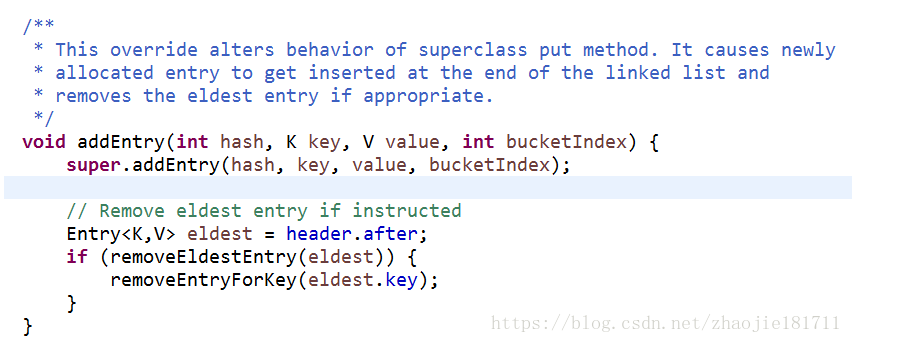

进来走的还是HashMap的put添加方法,在上面的判断和计算hash确定位置之后,由于LinkedHashSet重写了addEntry

在元素的后面添加新的元素。
整个过程就是LinkedHashSet在容器插入数据的过程。此过程主要由LinkedHashSet.class中重写超类的两个addEntry和createEntry 实现双向链表的结构。保证数据已我们录入的顺序遍历输出。
————————————————
版权声明:本文为CSDN博主「X-TIE」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zhaojie181711/article/details/80510129