一 KNN算法
1. KNN算法简介
KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类对应的关系。输入没有标签的数据后,将新数据中的每个特征与样本集中数据对应的特征进行比较,提取出样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k近邻算法中k的出处,通常k是不大于20的整数。最后选择k个最相似数据中出现次数最多的分类作为新数据的分类。
说明:KNN没有显示的训练过程,它是“懒惰学习”的代表,它在训练阶段只是把数据保存下来,训练时间开销为0,等收到测试样本后进行处理。
举个栗子:以电影分类作为例子,电影题材可分为爱情片,动作片等,那么爱情片有哪些特征?动作片有哪些特征呢?也就是说给定一部电影,怎么进行分类?这里假定将电影分为爱情片和动作片两类,如果一部电影中接吻镜头很多,打斗镜头较少,显然是属于爱情片,反之为动作片。有人曾根据电影中打斗动作和接吻动作数量进行评估,数据如下:
|
电影名称 |
打斗镜头 |
接吻镜头 |
电影类别 |
|
Califoria Man |
3 |
104 |
爱情片 |
|
Beautigul Woman |
1 |
81 |
爱情片 |
|
Kevin Longblade |
101 |
10 |
动作片 |
|
Amped II |
98 |
2 |
动作片 |
给定一部电影数据(18,90)打斗镜头18个,接吻镜头90个,如何知道它是什么类型的呢?KNN是这样做的,首先计算未知电影与样本集中其他电影的距离(这里使用欧式距离),数据如下:
|
电影名称 |
与未知分类电影的距离 |
|
Califoria Man |
20.5 |
|
Beautigul Woman |
19.2 |
|
Kevin Longblade |
115.3 |
|
Amped II |
118.9 |
现在我们按照距离的递增顺序排序,可以找到k个距离最近的电影,加入k=3,那么来看排序的前3个电影的类别,爱情片,爱情片,动作片,下面来进行投票,这部未知的电影爱情片2票,动作片1票,那么我们就认为这部电影属于爱情片。
2. KNN算法优缺点
优点:精度高,对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
3. KNN算法python代码实现
实现步骤:
(1)计算距离
(2)选择距离最小的k个点
(3)排序
代码实现:
import numpy as np
import operator
def classfy(int_x, data_set, labels, k=3):
"""
kNN(k=3) 分类器
:param int_x: 目标特征向量
:param data_set: 数据集
:param labels: 分类向量
:param k: k 值
:return: 距离
"""
data = np.array(data_set)
doint = np.array(int_x)
# 计算距离(欧氏距离公式)
distance = np.sum((data - doint) ** 2, axis=1) ** 0.5
# 距离排序
# distance = np.sort(distance)
distances = distance.argsort() # 排序后显示在原列表的下标
class_count = {}
# 选择距离最小的N个点
for i in range(k):
# 获取labels里前K个元素([1,0,3,2],取前三个)
vote_i_label = labels[distances[i]]
# 统计各元素个数
class_count[vote_i_label] = class_count.get(vote_i_label, 0) + 1
# dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。
# 按个数排序
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
# key=operator.itemgetter(1)根据字典的值进行排序
# key=operator.itemgetter(0)根据字典的键进行排序
# reverse降序排序字典
return sorted_class_count[0][0]
二 KNN算法实例
1. 鸢尾花品种预测
普通实现:
# 导入相应的包
import random
import operator
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def classify(int_x, data_set, labels, k=3):
"""
kNN(k=3) 分类器
:param int_x: 目标特征向量
:param data_set: 数据集
:param labels: 分类向量
:param k: k 值
:return: 距离
"""
data = np.array(data_set)
doint = np.array(int_x)
# 计算距离(欧氏距离公式)
distance = np.sum((data - doint) ** 2, axis=1) ** 0.5
# 距离排序
# distance = np.sort(distance)
distances = distance.argsort() # 排序后显示在原列表的下标
class_count = {}
# 选择距离最小的N个点
for i in range(k):
# 获取labels里前K个元素([1,0,3,2],取前三个)
vote_i_label = labels[distances[i]]
# 统计各元素个数
class_count[vote_i_label] = class_count.get(vote_i_label, 0) + 1
# dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。
# 按个数排序
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
# key=operator.itemgetter(1)根据字典的值进行排序
# key=operator.itemgetter(0)根据字典的键进行排序
# reverse降序排序字典
return sorted_class_count[0][0]
def get_data_set(file):
"""
获得训练集数据
:param filename:
:return:
"""
df = pd.read_csv(file, sep=',', names=['sepal_length', 'sepal_wide', 'petal_length', 'petal_wide','species'])
data_set = df.ix[:, :-1]
labels = df.ix[:, -1]
return data_set, labels
def draw_image(file):
"""
画图
:param file:
:return:
"""
df = pd.read_csv(file, delimiter=',', names=['sepal_length', 'sepal_wide', 'petal_length', 'petal_wide','species'])
# setosa花瓣花萼长宽
setosa_sepal_length, setosa_sepal_width, setosa_petal_length, setosa_petal_width = [], [], [], []
# versicolor花瓣花萼长宽
versicolor_sepal_length, versicolor_sepal_width, versicolor_petal_length, versicolor_petal_width = [], [], [], []
# virginica花瓣花萼长宽
virginica_sepal_length, virginica_sepal_width, virginica_petal_length, virginica_petal_width = [], [], [], []
# 分组
for i in range(len(df)):
if df.ix[i, -1] == 'Iris-setosa':
setosa_sepal_length.append(df.ix[i][0])
setosa_sepal_width.append(df.ix[i][1])
setosa_petal_length.append(df.ix[i][2])
setosa_petal_width.append(df.ix[i][3])
elif df.ix[i, -1] == 'Iris-versicolor':
versicolor_sepal_length.append(df.ix[i][0])
versicolor_sepal_width.append(df.ix[i][1])
versicolor_petal_length.append(df.ix[i][2])
versicolor_petal_width.append(df.ix[i][3])
else:
virginica_sepal_length.append(df.ix[i][0])
virginica_sepal_width.append(df.ix[i][1])
virginica_petal_length.append(df.ix[i][2])
virginica_petal_width.append(df.ix[i][3])
plt.figure(figsize=(9, 4))
# petal 长宽散点图
plt.subplot(1, 2, 1)
plt.scatter(setosa_petal_width, setosa_petal_length, marker='.', alpha=0.5, label='setosa')
plt.scatter(versicolor_petal_width, versicolor_petal_length, marker='+', alpha=0.5, label='versicolor')
plt.scatter(virginica_petal_width, virginica_petal_length, marker='<', alpha=0.5, label='virginica')
plt.xlabel('花瓣宽度')
plt.ylabel('花瓣长度')
plt.title('petal of iris')
plt.legend()
# sepal 长宽散点图
plt.subplot(1, 2, 2)
plt.scatter(setosa_sepal_width, setosa_sepal_length, marker='.', alpha=0.5, label='setosa')
plt.scatter(versicolor_sepal_width, versicolor_sepal_length, marker='+', alpha=0.5, label='versicolor')
plt.scatter(virginica_sepal_width, virginica_sepal_length, marker='<', alpha=0.5, label='virginica')
plt.xlabel('花萼宽度')
plt.ylabel('花萼长度')
plt.title('sepal of iris')
plt.legend()
plt.show()
def data_class_test(data_set, labels):
"""
测试算法
:param data_set: 测试集
:param labels: 目标变量
:return:
"""
test_data_length = int(len(data_set) * 0.1) # 拿出作为测试集的数据大小
index_list = random.sample(range(len(data_set)), test_data_length)
test_group = pd.DataFrame(np.zeros((test_data_length, 4)),
columns=['sepal_length', 'sepal_wide', 'petal_length', 'petal_wide'])
test_label = []
error_count = 0.0 # 错误统计
# 获取测试集
for i in range(test_data_length):
index = index_list[i]
test_group.ix[i] = data_set.ix[index]
test_label.append(labels[index])
# 去除测试集的训练集和目标变量
train_data_set = data_set.drop(index_list)
train_label = labels.drop(index_list)
train_data_set = train_data_set.reset_index(drop=True)
train_label = train_label.reset_index(drop=True)
for i in range(test_data_length):
iris_type = classify(test_group.ix[i], train_data_set, train_label)
if iris_type != test_label[i]:
print('错误分类结果:%s, 实际答案:%s' % (iris_type, test_label[i]))
error_count += 1.0
print('错误总数:%d' % error_count)
print('分类器错误率为: %0.2f%%' % (error_count / float(test_data_length) * 100))
def classify_flower(data_set, labels):
"""
对给定的数据进行花品种预测
:param data_set:
:param labels:
:return:
"""
# 输入判断数据
sepal_length= float(input('请输入花萼长度:'))
sepal_wide = float(input('请输入花萼宽度:'))
petal_length = float(input('请输入花瓣长度:'))
petal_wide = float(input('请输入花瓣宽度:'))
x = np.array([sepal_length, sepal_wide, petal_length, petal_wide])
iris_type = classify(x, data_set, labels)
print('该花的品种为:%s' % iris_type)
if __name__ == '__main__':
file = 'datairis.csv'
data_set, labels = get_data_set(file)
# 画图
#draw_image(file)
# 预测品种
#classify_flower(data_set, labels)
# 算法测试
data_class_test(data_set, labels)
sklearn实现:
from sklearn.datasets import load_iris # 导入IRIS数据集
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import random
from sklearn import neighbors, preprocessing
import sklearn
def classify(data_set, labels, k=3):
"""
分类器
:param data_set: 数据集
:param labels: 分类向量
:param k: k值
:return:
"""
# 生成sk-learn的最近k邻分类功能
clf = neighbors.KNeighborsClassifier(algorithm='kd_tree', n_neighbors=k)
# 拟合(训练)数据
clf.fit(data_set, labels)
return clf
def auto_norm(data_set):
"""
归一化数据:将任意取值范围内的特征转化为0-1区间的值
:param data_set:
:return:
"""
min_max_scaler = preprocessing.MinMaxScaler()
data_set = min_max_scaler.fit_transform(data_set) # 将数据特征缩放至0-1范围
return data_set
def get_data_set():
"""
获得数据
:return:
"""
iris = load_iris() # 特征矩阵
data_set, labels = iris.data, iris.target
print(type(data_set))
return data_set, labels
def draw_image(data_set, labels):
# setosa花瓣花萼长宽
setosa_sepal_length, setosa_sepal_width, setosa_petal_length, setosa_petal_width = [], [], [], []
# versicolor花瓣花萼长宽
versicolor_sepal_length, versicolor_sepal_width, versicolor_petal_length, versicolor_petal_width = [], [], [], []
# virginica花瓣花萼长宽
virginica_sepal_length, virginica_sepal_width, virginica_petal_length, virginica_petal_width = [], [], [], []
# 分组
for i in range(len(data_set)):
if labels[i] == 0:
setosa_sepal_length.append(data_set[i][0])
setosa_sepal_width.append(data_set[i][1])
setosa_petal_length.append(data_set[i][2])
setosa_petal_width.append(data_set[i][3])
elif labels[i] == 1:
versicolor_sepal_length.append(data_set[i][0])
versicolor_sepal_width.append(data_set[i][1])
versicolor_petal_length.append(data_set[i][2])
versicolor_petal_width.append(data_set[i][3])
else:
virginica_sepal_length.append(data_set[i][0])
virginica_sepal_width.append(data_set[i][1])
virginica_petal_length.append(data_set[i][2])
virginica_petal_width.append(data_set[i][3])
plt.figure(figsize=(9, 4))
# petal 长宽散点图
plt.subplot(1, 2, 1)
plt.scatter(setosa_petal_width, setosa_petal_length, marker='.', alpha=0.5, label='setosa')
plt.scatter(versicolor_petal_width, versicolor_petal_length, marker='+', alpha=0.5, label='versicolor')
plt.scatter(virginica_petal_width, virginica_petal_length, marker='<', alpha=0.5, label='virginica')
plt.xlabel('花瓣宽度')
plt.ylabel('花瓣长度')
plt.title('petal of iris')
plt.legend()
# sepal 长宽散点图
plt.subplot(1, 2, 2)
plt.scatter(setosa_sepal_width, setosa_sepal_length, marker='.', alpha=0.5, label='setosa')
plt.scatter(versicolor_sepal_width, versicolor_sepal_length, marker='+', alpha=0.5, label='versicolor')
plt.scatter(virginica_sepal_width, virginica_sepal_length, marker='<', alpha=0.5, label='virginica')
plt.xlabel('花萼宽度')
plt.ylabel('花萼长度')
plt.title('sepal of iris')
plt.legend()
plt.show()
def data_class_test(data_set, labels):
"""
测试算法
:param data_set: 测试集
:param labels: 目标变量
:return:
"""
test_data_length = int(len(data_set) * 0.1) # 拿出作为测试集的数据大小
index_list = random.sample(range(len(data_set)), test_data_length)
test_data = np.array(range(test_data_length * 4)).reshape(test_data_length, 4)
test_label = []
error_count = 0.0 # 错误统计
# 获取测试集
for i in range(test_data_length):
index = index_list[i]
test_data[i, :] = data_set[index,:]
test_label.append(labels[index])
# 去除测试集的训练集和目标变量
train_data_set = np.delete(data_set, index_list, 0)
train_label = np.delete(labels, index_list)
clf = classify(train_data_set, train_label)
test_data_norm = auto_norm(test_data)
score = clf.score(test_data_norm, test_label)
print('正确率:%0.2f%%' % (float(score) * 100))
def classify_flower(data_set, labels):
"""
对给定的数据进行花分类判断
:param data_set:
:param labels:
:return:
"""
# 花的类别
flower_stype = ['Iris-setosa', 'Iris-versicolor', 'Iris-virginica']
# 输入判断数据
sepal_length= float(input('请输入花萼长度:'))
sepal_wide = float(input('请输入花萼宽度:'))
petal_length = float(input('请输入花瓣长度:'))
petal_wide = float(input('请输入花瓣宽度:'))
x = np.array([sepal_length, sepal_wide, petal_length, petal_wide])
iris_type = flower_stype[int(classify(data_set, labels).predict([x]))]
print('该花的品种为:%s' % iris_type)
if __name__ == '__main__':
file = 'datairis.csv'
data_set,labels = get_data_set()
# 画图
#draw_image(data_set, labels)
# 预测品种
classify_flower(data_set, labels)
# 测试算法
data_class_test(data_set,labels)
2. 改进约会网站匹配
这个例子简单说就是通过KNN找到你喜欢的人,首先数据样本包含三个特征,(a)每年获得的飞行常客里程数(b)玩游戏消耗的时间(c)每周消耗的冰激淋公升数,样本数据放在txt中,如下,前三列为三个特征值,最后一列为标签
普通实现:
# 导入相关工具包
import numpy as np
import operator
import matplotlib.pyplot as plt
def classify(int_x, data_set, labels, k=3):
"""
kNN(k=3) 分类器
:param int_x: 目标特征向量
:param data_set: 数据集
:param labels: 分类向量
:param k: k 值
:return: 距离
"""
data = np.array(data_set)
doint = np.array(int_x)
# 计算距离(欧氏距离公式)
distance = np.sum((data - doint) ** 2, axis=1) ** 0.5
# 距离排序
#distance = np.sort(distance)
distances = distance.argsort() # 排序后显示在原列表的下标
class_count = {}
# 选择距离最小的N个点
for i in range(k):
# 获取labels里前K个元素([1,0,3,2],取前三个)
vote_i_label = labels[distances[i]]
# 统计各元素个数
class_count[vote_i_label] = class_count.get(vote_i_label, 0) + 1
# 按个数排序
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
return sorted_class_count[0][0]
def auto_norm(data_set):
"""
归一化数据:将任意取值范围内的特征转化为0-1区间的值
公式:new_values = (current_val - min) / (max - min)
:param data_set:
:return:
"""
min_val = data_set.min(0) # 获取数组内最小值
max_val = data_set.max(0) # 获取数组内最大值
ranges = max_val - min_val
# data_set的行数
m = data_set.shape[0]
norm_data_set = data_set - np.tile(min_val, (m,1))
norm_data_set = norm_data_set/np.tile(ranges, (m, 1))
return norm_data_set, ranges, min_val
def file_to_martrix(filename):
"""
将文件记录转换到numpy-数组的解析程序
:param filename: 数据集文件名
:return return_mat:特征值矩阵
:return class_label_vector: 目标变量向量
"""
# 打开并加载文件
with open(filename) as df:
# 读取所有行
array_lines = df.readlines()
# 得到文件行数
number_of_lines = len(array_lines)
# 创建空矩阵
return_mat = np.zeros([number_of_lines, 3]) # 得到一个填充为0的矩阵
# 返回的分类标签
class_label_vector = []
# 行的索引
index = 0
for line in array_lines:
line = line.strip()
list_from_line = line.split(' ')
return_mat[index, :] = list_from_line[0:3]
class_label_vector.append(int(list_from_line[-1]))
index += 1
return return_mat, class_label_vector
def create_matplotlab_img(data_set, labels):
"""
创建散点图展示数据分析
:param data_set: 特征数据集
:param labels: 分类向量
:return: None
"""
# 初始化数据
type_1_x = []
type_1_y = []
type_2_x = []
type_2_y = []
type_3_x = []
type_3_y = []
for i in range(len(labels)):
if labels[i] == 1:
type_1_x.append(data_set[i][0])
type_1_y.append(data_set[i][1])
if labels[i] == 2:
type_2_x.append(data_set[i][0])
type_2_y.append(data_set[i][1])
if labels[i] == 3:
type_3_x.append(data_set[i][0])
type_3_y.append(data_set[i][1])
fig = plt.figure()
ax = fig.add_subplot(111)
# 设置数据属性
type_1 = ax.scatter(type_1_x, type_1_y, s=20, c='g', alpha=0.8)
type_2 = ax.scatter(type_2_x, type_2_y, s=20, c='r', alpha=0.8)
type_3 = ax.scatter(type_3_x, type_3_y, s=20, c='m', alpha=0.8)
plt.title('约会对象分析')
plt.xlabel('每周消耗的冰激凌公升数')
plt.ylabel('玩游戏所消耗时间百分比')
ax.legend((type_1,type_2,type_3), ('不喜欢', '魅力一般', '极具魅力'))
plt.show()
def dating_class_test():
"""
测试算法
:return:
"""
hold_out_ratio = 0.10 # 拿出作为测试集的数据比例
data_set, labels = file_to_martrix('datadating_test_set_2.txt')
norm_data_set, ranges, min_vals = auto_norm(data_set) # 归一化数据
size = norm_data_set.shape[0] # 获取数据集行数
num_test_size = int(size * hold_out_ratio) # 保留行数
error_count = 0.0 # 错误统计
for i in range(num_test_size):
classifier_result = classify(norm_data_set[i, :],
norm_data_set[num_test_size:size],
labels[num_test_size:size], 5)
print('分类器返回:%d, 真是答案为:%d'% (classifier_result, labels[i]))
if classifier_result != labels[i]:
error_count += 1.0
print('分类器错误率为: %0.2f%%'% (error_count / float(num_test_size) * 100))
def classify_person():
"""
对给定的数据进行人群分类判断
:param data_set:
:param labels:
:return:
"""
class_list = ['没兴趣,不去约会', '有点意思,工作日约会', '极具魅力,周末约会']
print("请输入:
")
fly_miles = float(input("每年获得的飞行常客里程数:"))
ice_cream = float(input('每周消耗的冰激凌公升数:'))
game_time = float(input('玩视频游戏所消耗时间百分比:'))
data_set, labels = file_to_martrix('datadating_test_set_2.txt')
norm_data_set, ranges, min_vals = auto_norm(data_set)
int_x = [fly_miles, ice_cream, game_time] # 待验证的特征向量
norm_int_x = (int_x - min_vals) / ranges
res = classify(norm_int_x, norm_data_set, labels, k=5)
print(res)
print(class_list[res - 1])
if __name__ == '__main__':
filename = 'datadating_test_set_2.txt'
# 算法测试
#dating_class_test()
#data_set, labels = file_to_martrix(filename)
# 画图
#create_matplotlab_img(data_set, labels)
classify_person()
sklearn实现:
# 导入相应的包
import numpy as np
import matplotlib.pyplot as plt
from sklearn import neighbors, preprocessing
def file_to_martrix(filename):
"""
将文件记录转换到numpy-数组的解析程序
:param filename: 数据集文件名
:return return_mat:特征值矩阵
:return class_label_vector: 目标变量向量
"""
# 打开并加载文件
with open(filename) as df:
# 读取所有行
array_lines = df.readlines()
# 得到文件行数
number_of_lines = len(array_lines)
# 创建空矩阵
return_mat = np.zeros((number_of_lines, 3)) # 得到一个填充为0的矩阵
class_label_vector = []
index = 0
for line in array_lines:
line = line.strip()
list_from_line = line.split(' ')
return_mat[index, :] = list_from_line[0:3]
class_label_vector.append(int(list_from_line[-1]))
index += 1
return return_mat, class_label_vector
def create_matplotlab_img(data_set, labels):
"""
创建散点图展示数据分析
:param data_set: 特征数据集
:param labels: 分类向量
:return: None
"""
# 初始化数据
type_1_x = []
type_1_y = []
type_2_x = []
type_2_y = []
type_3_x = []
type_3_y = []
for i in range(len(labels)):
if labels[i] == 1:
type_1_x.append(data_set[i][0])
type_1_y.append(data_set[i][1])
if labels[i] == 2:
type_2_x.append(data_set[i][0])
type_2_y.append(data_set[i][1])
if labels[i] == 3:
type_3_x.append(data_set[i][0])
type_3_y.append(data_set[i][1])
fig = plt.figure()
ax = fig.add_subplot(111)
# 设置数据属性
type_1 = ax.scatter(type_1_x, type_1_y, s=20, c='g', alpha=0.8)
type_2 = ax.scatter(type_2_x, type_2_y, s=20, c='r', alpha=0.8)
type_3 = ax.scatter(type_3_x, type_3_y, s=20, c='m', alpha=0.8)
plt.title('约会对象分析')
plt.xlabel('每周消耗的冰激凌公升数')
plt.ylabel('玩游戏所消耗时间百分比')
ax.legend((type_1,type_2,type_3), ('不喜欢', '魅力一般', '极具魅力'))
plt.show()
def classify(data_set, labels, k=3):
"""
分类器
:param data_set: 数据集
:param labels: 分类向量
:param k: k值
:return:
"""
# 生成sk-learn的最近k邻分类功能
clf = neighbors.KNeighborsClassifier(algorithm='kd_tree', n_neighbors=k)
# 拟合(训练)数据
clf.fit(data_set, labels)
return clf
def auto_norm(data_set):
"""
归一化数据:将任意取值范围内的特征转化为0-1区间的值
:param data_set:
:return:
"""
min_max_scaler = preprocessing.MinMaxScaler()
data_set = min_max_scaler.fit_transform(data_set) # 将数据特征缩放至0-1范围
return data_set
def classify_person(clf_model):
"""
对给定的数据进行人群分类判断
:param clf_model:
:return:
"""
class_list = ['没兴趣,不去约会', '有点意思,工作日约会', '极具魅力,周末约会']
print("请输入:
")
fly_miles = float(input("每年获得的飞行常客里程数:"))
ice_cream = float(input('每周消耗的冰激凌公升数:'))
game_time = float(input('玩视频游戏所消耗时间百分比:'))
train_set = np.array([fly_miles, ice_cream, game_time]).reshape(1, 3)
# 归一化数据
train_set = auto_norm(train_set)
predic = int(clf_model.predict(train_set))
print(class_list[predic - 1])
if __name__ == '__main__':
filename = 'datadating_test_set_2.txt'
data_set, labels = file_to_martrix(filename)
clf = classify(data_set, labels)
classify_person(clf)
create_matplotlab_img(data_set, labels)
运行:

3. 手写数字识别
训练集、测试集形式:

首先我们要将图像数据处理为一个向量,将32*32的二进制图像信息转化为1*1024的向量,再使用分类器,代码如下:
普通实现:
# kNN算法: 手写图像识别
import numpy as np
import operator
import random
from os import listdir
def image_to_vector(filename):
"""
将图像转换成向量
:param filename:目标图像文件名
:return: 数据向量
"""
vect = np.zeros((1, 1024)) # 创建1 * (32 * 32)数据向量
with open(filename) as f:
for i in range(32):
line_str = f.readline() # 第 i 行
for j in range(32):
vect[0, 32 * i + j] = line_str[j]
return vect
def classify(int_x, data_set, labels, k=3):
"""
kNN(k=3) 分类器
:param int_x: 目标特征向量
:param data_set: 数据集
:param labels: 分类向量
:param k: k 值
:return: 距离
"""
data = np.array(data_set)
doint = np.array(int_x)
# 计算距离(欧氏距离公式)
distance = np.sum((data - doint) ** 2, axis=1) ** 0.5
# 距离排序
# distance = np.sort(distance)
distances = distance.argsort() # 排序后显示在原列表的下标
class_count = {}
# 选择距离最小的N个点
for i in range(k):
# 获取labels里前K个元素([1,0,3,2],取前三个)
vote_i_label = labels[distances[i]]
# 统计各元素个数
class_count[vote_i_label] = class_count.get(vote_i_label, 0) + 1
# dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。
# 按个数排序
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
# key=operator.itemgetter(1)根据字典的值进行排序
# key=operator.itemgetter(0)根据字典的键进行排序
# reverse降序排序字典
return sorted_class_count[0][0]
def load_training_file():
"""
获取训练集数据
:return:
"""
training_digit = listdir(r'training_digits') # 获取目录内容
file_count = int(len(training_digit) * 0.8)
training_digit = random.sample(training_digit, file_count)
# 第一步: 创建训练集数据
training_file_data = np.zeros((file_count, 1024)) # 利用行数创建训练集数据
labels = []
for i in range(file_count):
# 从文件名解析分类数字
filename_str = training_digit[i]
class_num_str = int(filename_str[0])
labels.append(class_num_str)
img_vector = image_to_vector('training_digits/%s'% filename_str)
training_file_data[i:] = img_vector
return training_file_data, labels
def hand_writing_class_test():
"""
测试识别手写数字分类正确率
:return:
"""
error_count = 0.0
# 第一步: 获取训练集数据
training_file_data, labels = load_training_file()
# 第二步:获取测试集数据
test_file_list = listdir(r'test_digits')
m = len(test_file_list)
for i in range(m):
filename_str = test_file_list[i]
class_num_str = int(filename_str[0]) # 获取分类
test_img_vector = image_to_vector('test_digits/%s' % filename_str)
# 创建一个5NN分类模型
classifier_result = classify(test_img_vector, training_file_data, labels, 5)
if classifier_result != class_num_str:
error_count += 1.0
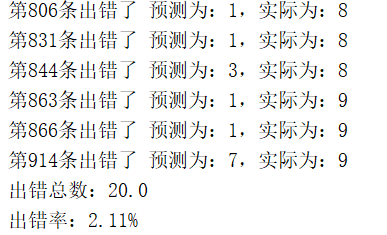
print('第{}条出错了 预测为:{},实际为:{}'.format(i, classifier_result, class_num_str))
print('出错总数:%s'% error_count)
print('出错率:%0.2f%%' % (error_count/float(m)*100))
if __name__ == '__main__':
hand_writing_class_test()
sklearn实现:
# kNN算法: 手写图像识别
import random
import numpy as np
from os import listdir
from sklearn import neighbors
def image_to_vector(filename):
"""
将图像转换成向量
:param filename:目标图像文件名
:return: vect - 返回的二进制图像的1*1024向量
"""
vect = np.zeros((1, 1024)) # 创建1 * (32 * 32)数据向量
with open(filename) as f:
for i in range(32):
line_str = f.readline() # 第 i 行
for j in range(32):
# 每一行的前32个数据依次添加到vect
vect[0, 32 * i + j] = line_str[j]
return vect
def load_training_file():
"""
获取训练集数据
:return:
"""
training_digit = listdir(r'training_digits') # 获取目录内容
file_count = int(len(training_digit) * 0.8)
training_digit = random.sample(training_digit, file_count) # 随机获取部分目录内容
training_file_data = np.zeros((file_count, 1024)) # 利用行数创建空的训练集数据
labels = []
for i in range(file_count):
# 从文件名解析分类数字
filename_str = training_digit[i]
class_num_str = int(filename_str[0]) # 获取分类
labels.append(class_num_str)
img_vector = image_to_vector('training_digits/%s' % filename_str)
training_file_data[i:] = img_vector
return training_file_data, labels
def classify(data_set, labels, k=3):
"""
分类器
:param data_set: 数据集
:param labels: 分类向量
:param k: k值
:return:
"""
# 生成sk-learn的最近k邻分类功能
clf = neighbors.KNeighborsClassifier(algorithm='kd_tree', n_neighbors=k)
# 拟合(训练)数据
clf.fit(data_set, labels)
return clf
def hand_writing_class_test():
"""
测试识别手写数字分类正确率
:return:
"""
error_count = 0.0
# 第一步: 创建训练集数据
training_file_data, labels = load_training_file()
# 第二步: 创建测试集数据
test_digit = listdir(r'test_digits')
test_file_count = len(test_digit)
for i in range(test_file_count):
# 文件名的第一个字符为真实数值
test_value = int(test_digit[i][0])
test_vect = image_to_vector('test_digits/%s' % test_digit[i])
# 创建一个5NN分类模型
clf = classify(training_file_data, labels, 5)
result = clf.predict(test_vect)
if result != test_value:
print('第{}条出错了 预测为:{},实际为:{}'.format(i, result, test_value))
error_count += 1.0
print('出错总数:%s' % error_count)
print('出错率:%0.2f%%' % (error_count/float(test_file_count) * 100))
if __name__ == '__main__':
hand_writing_class_test()
输出: