目录
一,事件回顾
二,问题原因
三,发生问题时的日志
四,避免此问题
1,auto.offset.reset参数设置为largest。
2,尽量不要一次关闭所有broker。
五,相关知识点
1,zookeeper记录offset的节点
2,关于auto.offset.reset参数。
3,几个kafka的命令
一,事件回顾
1,由3台broker组成的kafka集群,分别标记为broker0,broker1,broker2,某topic有3个副本,分别保存在这三个broker上。
2,某日broker0挂了,broker1和broker2好像也有点问题,于是关闭consumer,把broker1和broker2也关闭,然后按照broker0,broker1,broker2的顺序依次启动,并启动consumer。
3,发现这个topic积压了大量消息,积压量几乎和broker队列中的所有消息一样多,也就是说,consumer将要把队列中之前消费过的所有消息又重新消费一遍,造成了重复消费。
二,问题原因
问题的关键在于consumer的auto.offset.reset这个参数,这个参数在zookeeper中记录的当前消费offset超出broker中记录的offset队列范围时生效(该参数生效的场景不止这一种),发生问题的系统中这个参数设置的是smallest,代表consumer在参数生效时会从队列最小offset重新开始消费。
然后就是复现当时的场景了,也就是为什么zookeeper中记录的offset会超过broker消息队列中的offset范围,大概是下面这样的:
1,当系统还正常时:

consumer消费到了offset=200的消息,3个副本间同步正常,zookeeper中的offset记录为200。
2,broker0挂掉,重新进行了leader选举,broker1成为新的leader,于是变成下面这样:

3,此时producer没停,又向队列中放了2条消息,于是变成下面这样:
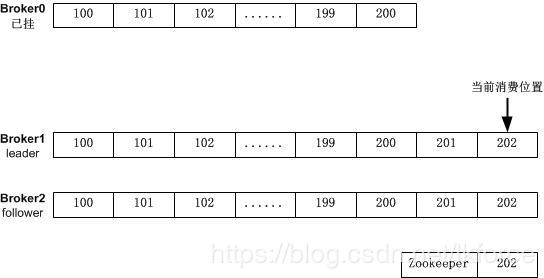
4,关闭consumer,关闭并重启了3个broker,先启动broker0:

注意,此时zookeeper中的offset记录为202,而broker0中只有offset=100到offset=200的消息。
5,此时consumer启动,发现zookeeper中offset是202,而broker0的队列中没有202,所以触发auto.offset.reset参数,配置为smallest,则从broker0的最小offset开始消费(也就是offset=100的位置)。
三,发生问题时的日志
发生这种问题,在几方面的日志中都有体现
在broker的sever.log中:
[2018-10-11 20:02:23,684] ERROR [Replica Manager on Broker 0]: Error when processing fetch request for partition [MY_TOPIC,12] offset 75927881 from consumer with correlation id 0. Possible cause: Request for offset 75927881 but we only have log segments in the range 75173010 to 75927856. (kafka.server.ReplicaManager)
这个日志只说超出了范围,没说offset重置到了哪个位置。
在consumer的日志中:
[ERROR] 2018-10-11 20:15:42,495 --ConsumerFetcherThread-mygroupid_localhost.localdomain-1538216932782-746319d8-0-0-- [kafka.consumer.ConsumerFetcherThread] [ConsumerFetcherThread-mygroupid_localhost.localdomain-1538216932782-746319d8-0-0], Current offset 75927881 for partition [MY_TOPIC,12] out of range; reset offset to 75173010 [ERROR] 2018-10-11 20:15:42,495 --ConsumerFetcherThread-mygroupid_localhost.localdomain-1538216937466-8aadae92-0-0-- [kafka.consumer.ConsumerFetcherThread] [ConsumerFetcherThread-mygroupid_localhost.localdomain-1538216937466-8aadae92-0-0], Current offset 75584110 for partition [MY_TOPIC,13] out of range; reset offset to 75010261
日志指出了出现的问题并且显示了offset初始化的值
在zookeeper中没有对此场景留下特别的日志记录。
四,避免此问题
1,auto.offset.reset参数设置为largest。
也就是从最大offset重新开始消费。
配置成largest的缺点:可能导致有的消息不会消费。如果队列中offset=202的消息后面还有offset=203和offset=204的消息,并且203和204未被consumer消费,配置为largest就会让consumer认为offset=204已经消费完成,然后从offset=205开始消费,203和204就不会被消费了。
配置成smallest的缺点:第一,可能导致重复消费。第二,也是最让人头疼的,是当broker中记录的消息很多的时候,从最小offset开始消费会导致大量的消息积压,导致新的消息在很长时间内无法被消费。
所以具体使用哪个配置得具体情况具体分析。这个参数默认是largest。
2,尽量不要一次关闭所有broker。
kafka有落后offset的同步机制,如果在其他broker存活时重启某个broker,比如本事件中在broker1和broker2存活时重启broker0,kafka会让broker0的offset补齐至topic的最大offset,然后将broker0加入ISR列表中。
五,相关知识点
1,zookeeper记录offset的节点
在zookeeper中有个节点记录了consumer消费完的offset,这个节点在zookeeper中的路径是:
/consumers/{group.id}/offsets/{topic}/{partition.id}
使用zookeeper的get命令可以看到这个节点中记录的offset数值。
使用zookeeper的set命令可以修改这个offset数值。
这个节点是持久节点。
当consumer消费完某条消息后,会向这个节点同步offset,因此,如果要修改这个节点的值,最好先关闭consumer。
当consumer启动时,会获得这个节点记录的offset,然后从下一个offset开始消费,如果获取的offset有问题(第2条中介绍),那么consumer会根据auto.offset.reset参数判断开始消费的offset位置。
2,关于auto.offset.reset参数。
这个参数是配置在consumer中的,参数值可以选择largest或者smallest,默认值是largest。
当consumer启动时,会从zookeeper的对应节点获取已经消费完成的offset,以便从下一个offset开始消费。如果获取失败, auto.offset.reset参数就会生效,失败的场景可能有以下两种:
1,zookeeper中的对应节点不存在。 从节点路径就可以看到,比如新建了groupID,新建了topic,新建(扩展)了partition,或者人工在zookeeper中删除该节点,都会导致节点不存在。另外这个节点是持久节点,不会因为
session超时等原因自己消失。 2,从节点中获取的offset超过了broker队列中的offset范围。 比如broker队列中的offset范围是从100至200,zookeeper节点中记录的offset是201。这种情况一般出现在broker主从同步异常的场景中。
当参数配置为largest,consumer会从队列中的最大offset+1的位置开始消费,当前队列中最大的offset不会被消费。
当参数配置为smallest,consumer会总队列中的最小offset位置开始消费,当前队列中最小的offset会被消费。
3,几个kafka的命令
查看分区情况
在kafka的bin目录下执行:
./kafka-topics.sh --describe –zookeeper {zookeeper地址和端口} --topic {topic}
这个命令会显示partition数,副本数,各partition的leader,Replicas列表,ISR列表。
查看offset情况
在kafka的bin目录下执行:
./kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --group {group.id} --topic {topic} --zookeeper {zookeeper地址和端口号}
这个命令会显示各partition的当前消费offset,最大offset,积压数,Owner。
查看最小offset
在kafka的bin目录下执行:
./kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list {broker地址和端口} –topic {topic} --time -2
查看最大offset
在kafka的bin目录下执行:
./kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list {broker地址和端口} -topic {topic} --time -1
————————————————
版权声明:本文为CSDN博主「lkforce」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lkforce/article/details/83384747