环境:Centos7,jdk1.8 ,Hadoop2.7
1、网络设置
(1)[root@master ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens32
把这一行 ONBOOT=no,设置成: ONBOOT=yes(意思是,设置成开机就启动网络)

(2)[root@master ~]#systemctl restart network
(3)在终端输入如下命令:ping 物理主机ip,检查网络是否畅通
2、上传并安装jdk文件
[root@master ~]#mkdir /home/ab [root@master ~]# cd /home/ab [root@master ab]#mkdir hjw
把jdk-8u172-linux-x64.tar.gz和hadoop-2.7.2.tar.gz文件上传到 /home/ab/hjw路径下边
[root@master ~]#mkdir /opt/Java [root@master ~]#cd /opt/Java [root@master Java] tar xvf /home/ab/hjw/jdk-8u172-linux-x64.tar.gz
备注:解压路径随意

3、 JDK环境变量设置
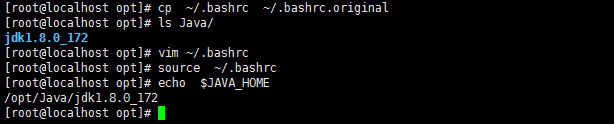
[root@master ~]# cp ~/.bashrc ~/.bashrc.original
[root@master ~]# vi ~/.bashrc(内容如下:)
export JAVA_HOME=/opt/Java/jdk1.8.0_172 export PATH=$PATH:$JAVA_HOME/bin
使配置生效
[root@master ~]#source ~/.bashrc [root@master ~]#echo $JAVA_HOME ###查看JAVA环境变量
4. Hostname and Security Settings
(1)hostname
先备份要修改的文件:
[root@master ~]# cp /etc/hostname /etc/hostname.original
修改域名解析文件:
[root@master ~]#vi /etc/hostname
内容修改成:master
[root@master ~]# source /etc/hostname(使修改生效)

(2) hosts
设置 hosts 文件:
[root@master ~]# vim /etc/hosts
最后一行添加:127.0.0.1 master
[root@master ~]# source /etc/hosts(使修改生效)
测试一下是否设置成功:
[root@master ~]# ping master

(3) Firewall
查看防火墙的运行状态:
[root@master ~]# firewall-cmd --state
停止防火墙服务:
[root@master ~]# systemctl stop firewalld.service
备注:但是关闭防火墙只能是临时的, 重启之后, 防火墙依然可能启动。
所以需要把关闭指令写到 /etc/profile 里:
[root@master ~]# vim /etc/profile
在文件最后一行添加,以后在保存退出。
systemctl stop firewalld.service

5、hadoop文件安装与配置
(1)hadoop文件安装
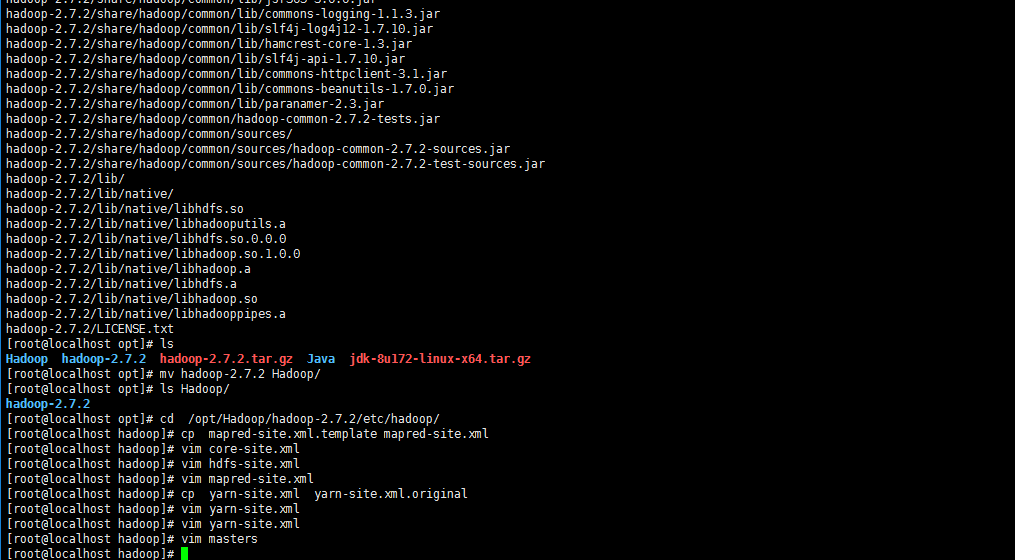
[root@master ~]#mkdir /opt/Hadoop [root@master ~]#cd /opt/Hadoop [root@master Hadoop]#tar xvf /home/ab/hjw/hadoop-2.7.2.tar.gz [root@master Hadoop]#cd /opt/Hadoop/hadoop-2.7.2/etc/hadoop/ [root@master hadoop]#cp mapred-site.xml.template mapred-site.xml
(2)core-site.xml配置
[root@master hadoop]#vim core-site.xml
在 <configuration> 之间添加如下内容:
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000/</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
(3)hdfs-site.xml配置
[root@master hadoop]# vim hdfs-site.xml
在 <configuration> 之间添加如下内容:
<property>
<name>dfs.data.dir</name>
<value>/home/ab/BigData/Hadoop/dfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/ab/BigData/Hadoop/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>master:50090</value>
</property>
(4) mapred-site.xml
[root@master hadoop]#vi mapred-site.xml
在 <configuration> 之间添加如下内容:
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
<description>MapReduce JobHistory Server IPC host:port</description>
</property>
(5)yarn-site.xml
[root@master hadoop]#cp yarn-site.xml yarn-site.xml.original
[root@master hadoop] #vi yarn-site.xml
在 <configuration> 之间添加如下内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<description>The hostname of the RM.</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
(6)添加一个 masters 文件
[root@master hadoop]#vim masters
内容为:master
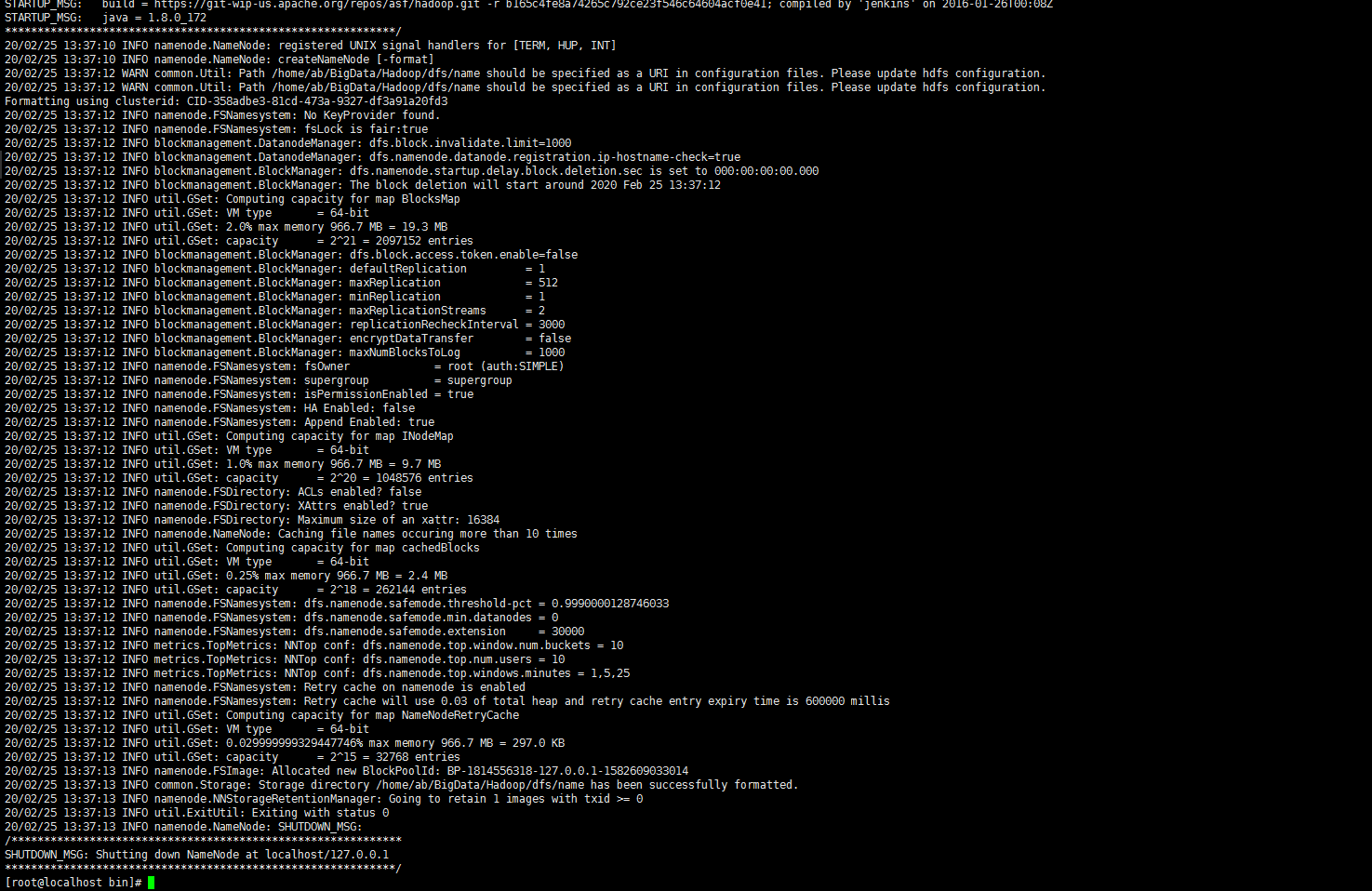
6、 Format hadoop 格式化数据文件 hdfs-site.xml 里面设置的目录。
[root@master hadoop]#cd /opt/Hadoop/hadoop-2.7.2/bin [root@master bin]# ./hadoop namenode -format
7、 Start hadoop
[root@master hadoop]# cd /opt/Hadoop/hadoop-2.7.2/sbin [root@master sbin]#./start-all.sh (默认必须以 root 启动,中间输入 4次 yes)

8、 Test Success
[root@master sbin]#jps
等待启动完毕,在本窗口里,查看 java 的进程:检查,必须有 namenode、datanode,否则就得去找问题。
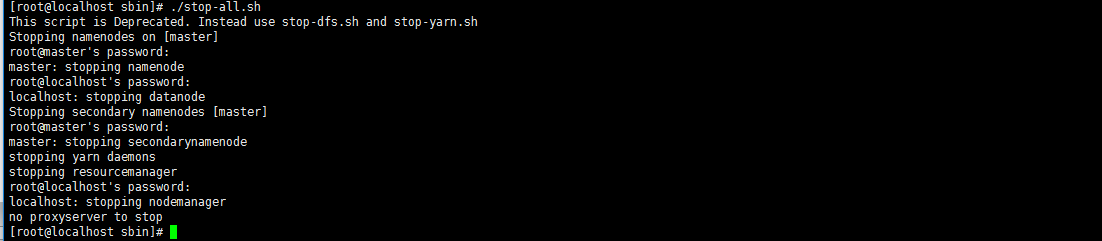
9、 Stop hadoop
[root@master hadoop]# cd /opt/Hadoop/hadoop-2.7.2/sbin [root@master sbin]#./stop-all.sh