论文地址:https://arxiv.org/pdf/1810.04805.pdf
简介
bert是google2018年提出的一种两阶段语言模型,全称Bidirectional Encoder Representations from Transformers,它本质上是基于Denoising AutoEncoding模型,即bert是AE语言模型,好处是能够双向编码获取上下文信息,缺点是它会在输入侧引入噪声——[MASK]标记符号,造成预训练-微调两个阶段的数据不一致,引起误差。虽然如此,bert依然有不可小觑的优势,它在发布之初,横扫nlp领域,在11项自然语言处理的任务中都拿到了第一的好成绩,接下来我会详细介绍一下bert。
BERT的总体思路
bert分为两个阶段:预训练阶段和fine-tunning阶段。预训练阶段利用Transformer结构进行训练,输入文本是大量的无监督文本,通过对无监督数据的训练获取一个泛化能力较强的预训练模型;fine-tuning阶段即微调阶段,在这一阶段会使用跟任务相关的有监督数据,基于上一步训练出的预训练模型进行针对性训练(只增加一个输出层即可),最终获取一个跟任务相关的模型。
bert的整体结构如下图所示:
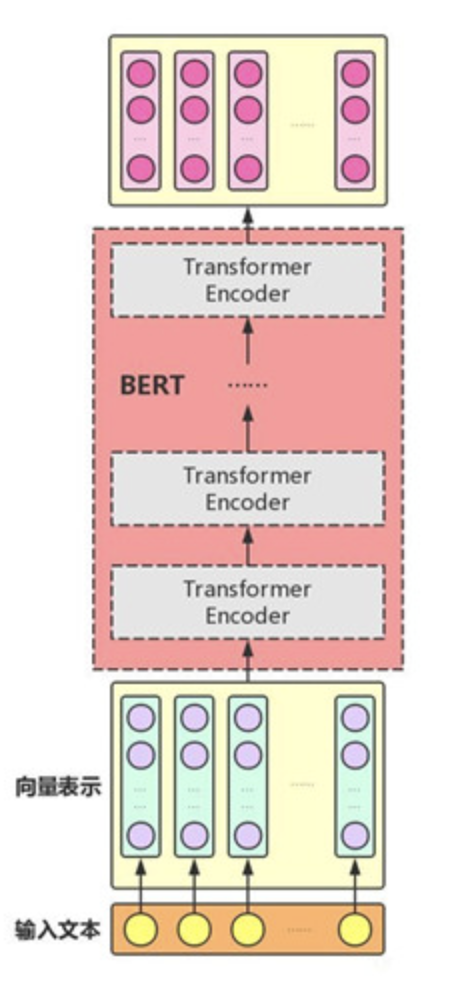
bert主要用了Transformer的encoder,而没有使用其decoder,主要是因为BERT是一个预训练模型,只要学到其中语义关系即可,不需要去解码完成具体的任务。多个Transformer encoder一层一层的堆叠起来,就组装成了bert.
网络结构
BERT使用的网络结构是标准的Transformer,即《Attention is all you need》论文中提出的多层Transformer结构,它不再使用传统的RNN(RNN的缺陷是不能很好的处理长文本,且不能并行处理数据),而是使用attention机制来解决长距离依赖问题。关于Transformer的详细内容可查看我之前的博客。
论文中分别画出了bert,GPT,ELMO的三个结构,如下图所示:
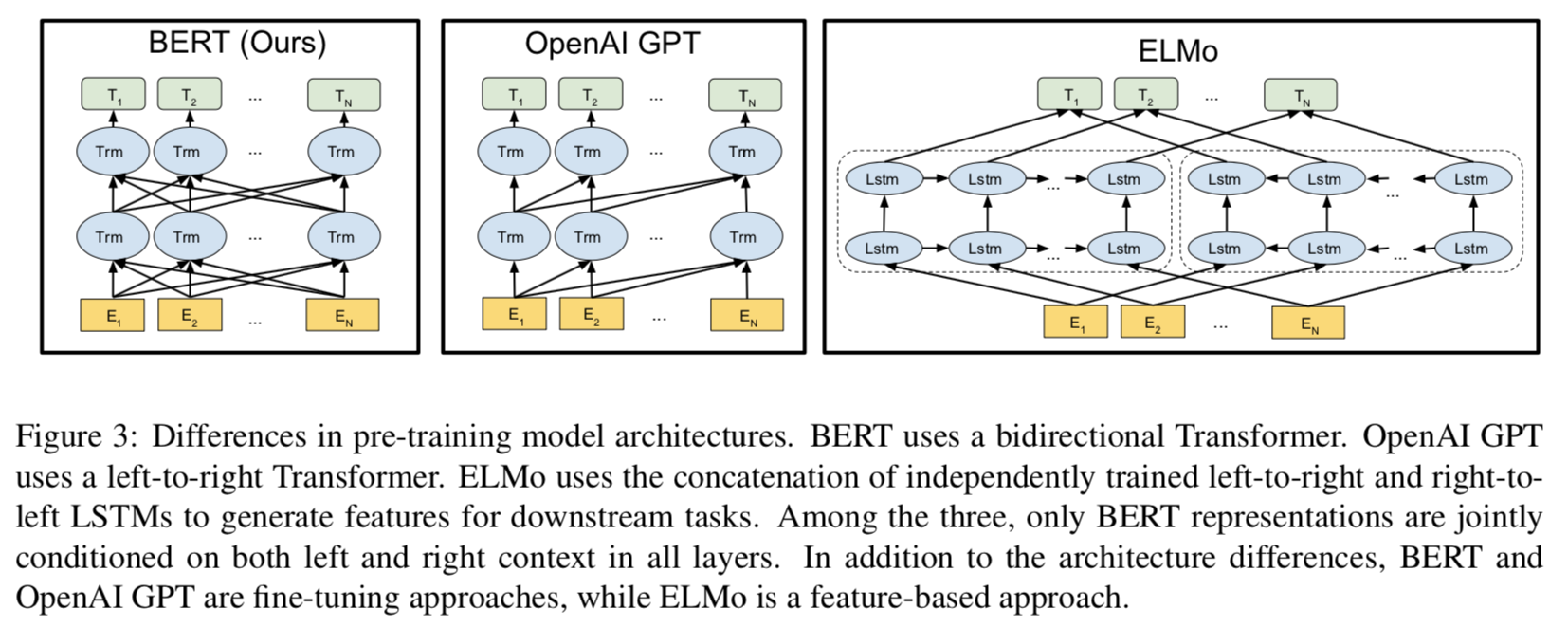
由上述结构对比图可知,BERT每一层都是用双向信息,gpt使用的是单向信息,即只能利用上文,却不能利用下文进行特征提取,elmo是使用了两个lstm获取信息,一个lstm获取上文信息,一个lstm获取下文信息,再将两个lstm计算的结果进行简单的拼接,看起来虽然也是获取了双向信息,但是其本质还是考虑单向信息,这从他们的目标函数上可以看出来,目标函数如下所述:
- Elmo: lstm1-> P(ωi | ω1,ω2,…,ωi-1) -> 获取上文信息
lstm2-> P(ωi | ωi+1,ωi+2,…,ωn) -> 获取下文信息
- Bert:P(ωi | ω1,ω2,…,ωi-1,ωi+1,ωi+2,…,ωn) -> 获取双向信息
Embedding
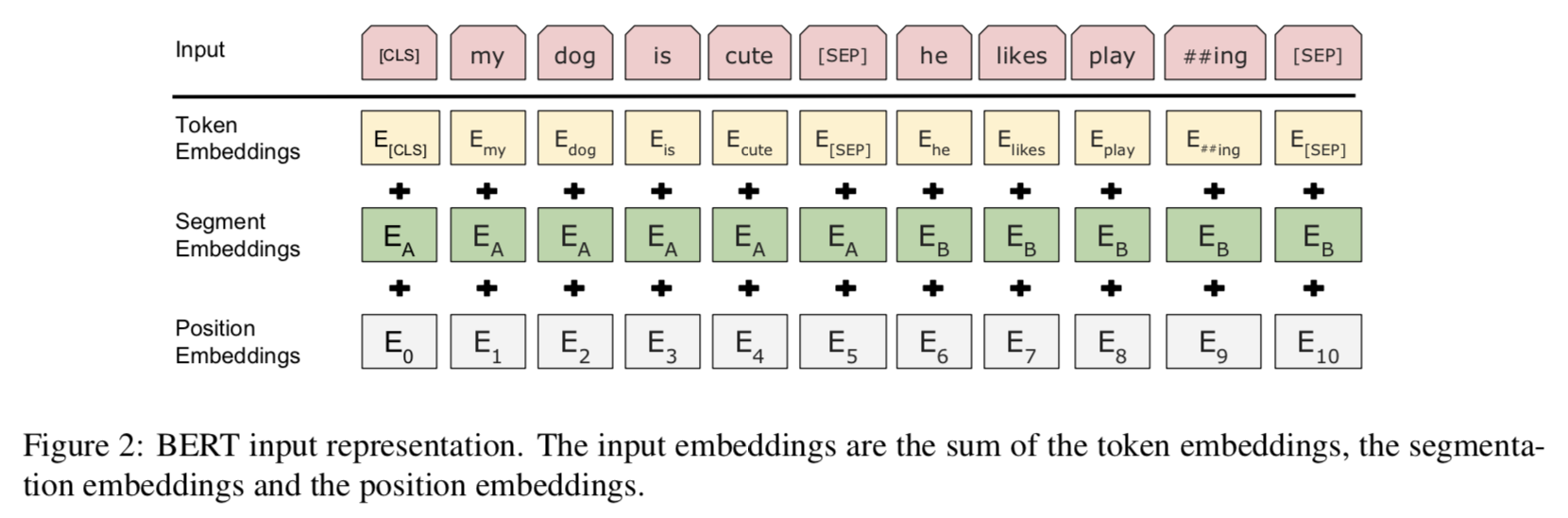
如上图所示,BERT的输入表征由三部分组成,具体内容如下所述:
- Token Embeddings:是指输入单词的词向量第一个单词是[CLS]标志,可用于之后的分类任务,输入如果是由两句话组成,则在第一句话与第二句话之间使用[SEP]符号分隔开。
- Segment Embeddings:用来判断输入的是否是两句话,不同的语句要用不同的向量特征来表示,如上图所示,用EA表示第一个语句,用EB表示第二个语句。
- Position Embeddings:用来表征单词在语句中的绝对位置。
最终的输入表征是将上述三个向量表征进行相加即可。
预训练过程
BERT的预训练阶段包括两个任务:Masked Language Model,Next Sentence Prediction,以下分别介绍这两个任务。
1、Masked Language Model:可以将其理解为完形填空,作者会随机mask掉一个句子中15%的单词,并用其上下文来做预测。对语句进行mask的方法有三种,假设原句是:My dog is hairy. 具体的方法如下所述:
- 80%是使用mask符号来代替语句中的词:My [MASK] is hairy.
- 10%是随机选择一个单词代替需mask掉的词:My dirty is hairy.
- 10%是使用原词:My dog is hairy.
作者之所以这样设计,是因为如果输入语句中的某个token100%被mask掉的话,那么在微调阶段模型就会遇到一些没有遇见过的单词,并且不知道这些单词可能存在于哪些上下文中。加入随机token是因为需要Transformer保持对每个token的分布式特征,否则模型就会记住某个mask对应的token。
2、Next Sentence Prediction[1]:该任务的主要目的是为了判断语句B是否是语句A的下文。是的话会输出’IsNext’,否则输出’NotNext’。生成训练数据的方式是从语料库中随机抽取一批连续的两句话,其中50%会原样保留语句,作为’IsNext’的训练样本,另外50%的数据会将其第二句话替换成任意一句话(替换的新语句一定不是原来的第二句话),作为’NotNext’的训练样本。并将这个语句关系保存在[CLS]符号中。
微调过程
在无监督语料中训练完BERT后,便可将其应用到nlp的各个任务中。下图展示了BERT用于不同任务的模型微调过程的训练。
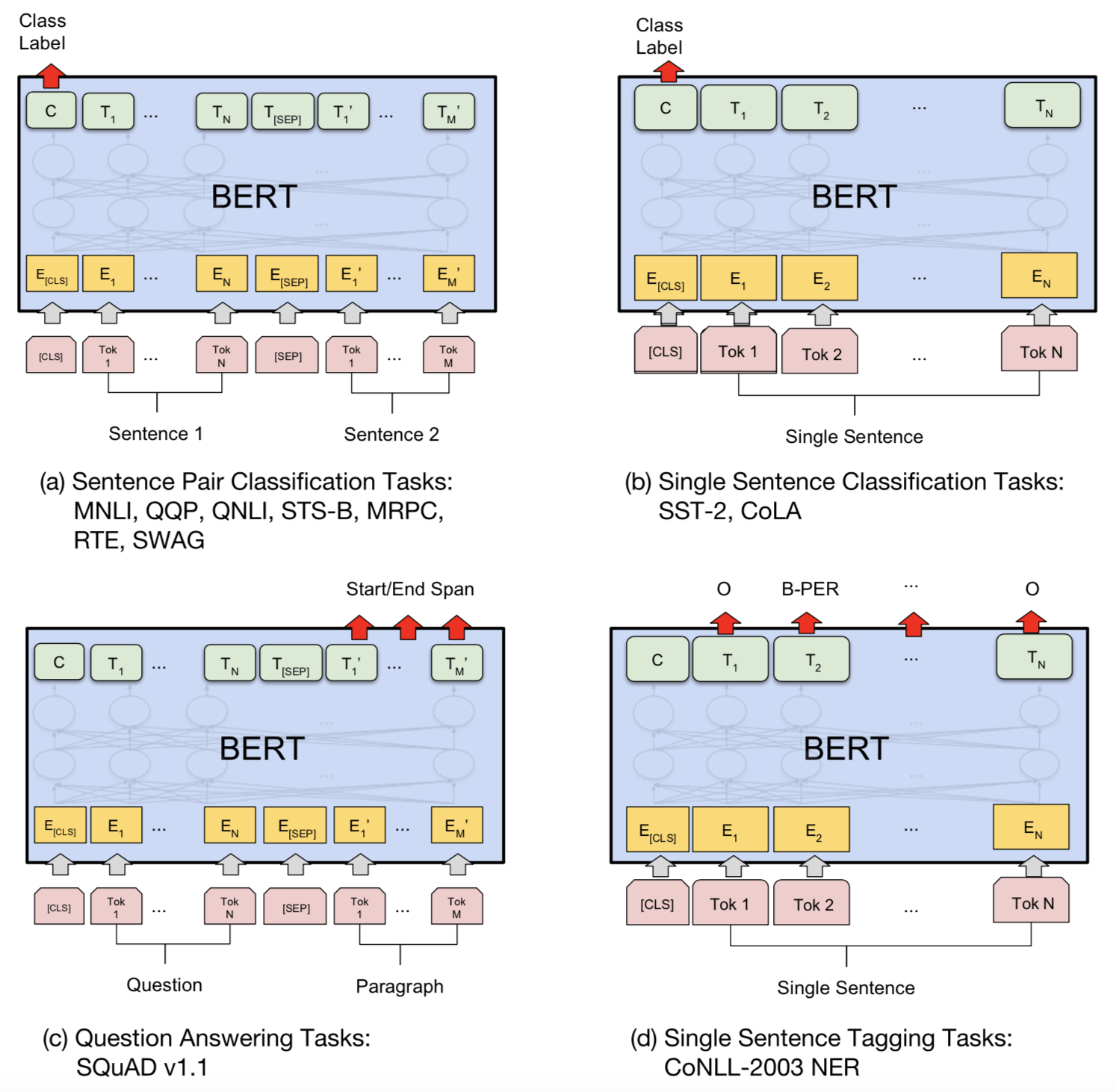
如上图所示,微调阶段只要在预训练阶段训练出的BERT模型上增加一个输出层即可完成对特定任务的微调。关于每一个数据集其具体的处理方法,可以看[1],这里有详细的描述。
总结
BERT的主要贡献如下[3]:
- 引入了Masked LM
- 预训练过程中增加了NSP的训练,可以学习两个语句间的关系
- 它验证了更大的模型效果更好:12->24层
- 做出了泛化能力较强的通用的预训练模型,并开源,方便其他研究者使用它做自己的任务
- 刷新了多项NLP任务的记录
参考资料
[1] https://zhuanlan.zhihu.com/p/48612853
[2] https://zhuanlan.zhihu.com/p/46652512
[3] https://blog.csdn.net/sunhua93/article/details/102764783