我来说一下我创建第一个spider小demo的过程,以及过程中出现的问题,供大家参考,希望大家少走弯路!
我的是windows系统,在pycharm上编码的。下面是创建运行爬虫的步骤:
一、创建一个scrapy项目
进入打算存储代码的目录中,在控制台中输入以下命令:
scrapy startproject 项目名
例如:scrapy startproject tutorial
该命令将会创建包含下列内容的tutorial目录:
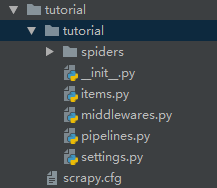
这些文件分别是:
- scrapy.cfg : 项目的配置文件
- tutorial/ : 该项目的python模块。
- tutorial/items.py : 项目中的item文件。
- tutorial/pipelines.py : 项目中的pipelines文件。
- tutorial/settings.py : 项目的设置文件。
- tutorial/spiders/ : 放置spider代码的目录。
二、定义Item
Item是保存爬取到的数据的容器;其使用方法和python字典类似, 并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。
编辑 tutorial 目录中的 items.py 文件:

三、编写爬取网站的 spider 并提取 Item
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。
其包含了一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成item的方法。
以下为我们的第一个Spider代码,保存在 tutorial/spiders 目录下的 dmoz_spider.py 文件中:
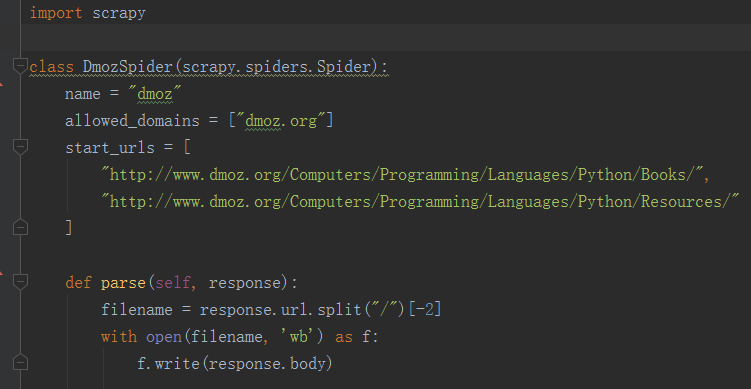
为了创建一个Spider,您必须继承 scrapy.Spider 类, 且定义以下三个属性:
-
- name : 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。
- start_urls :包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
- parse() :是spider的一个方法。 被调用时,每个初始URL完成下载后生成的Response对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的Request对象。
四、爬取
进入项目的根目录,执行下列命令启动spider:
scrapy crawl 爬虫名
例如:scrapy crawl dmoz ----这一步很多人容易把爬虫名跟项目名搞混,爬虫名就是你自己定义的那个name
运行这一步很多人容易出错,

可能有以下3种解决办法:
1.看看你在命令行输入的scrapy crawl dmoz中爬虫名,是不是跟程序中name字段定义的一样,谨防拼错!
2.scrapy crawl dmoz 这个命令一定要在项目目录下运行,比如我的,就必须在跟scrapy.cfg同级那个tutorial目录下运行
3.再有就是看scrapy.cfg文件是否在项目目录下,一定放在项目目录下!
然后,你以为可以顺利运行了?我的又出现一个错误

解决办法:
pip install pypiwin32
安装过程还会出错!!!!
解决办法用:
步骤 (1): pip --default-timeout=100 install -U pip
步骤 (2): pip --default-timeout=100 install -U (这里加上你要下载的库的名字),如:
pip --default-timeout=100 install -U selenium
至此,再运行scrapy crawl dmoz就成功啦!