参考博客:点击这里
一、scrapy安装配置
Linux
pip3 install scrapy
Windows
a. pip3 install wheel
b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
c. 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl
d. pip3 install scrapy
e. 下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/
二、创建并运行scrapy
1. scrapy startproject 项目名称
- 在当前目录中创建中创建一个项目文件(类似于Django)
2. scrapy genspider [-t template] <name> <domain>
- 创建爬虫应用
如:
scrapy gensipider -t basic oldboy oldboy.com
scrapy gensipider -t xmlfeed autohome autohome.com.cn
PS:
查看所有命令:scrapy gensipider -l
查看模板命令:scrapy gensipider -d 模板名称
3. scrapy list
- 展示爬虫应用列表
4. scrapy crawl 爬虫应用名称
- 运行单独爬虫应用
注意:
解决办法:由于本地缺少lxml文件或是lxml文件不符
pip3 uninstall lxml 先卸载已经安装的lxml
官网下载新的lxml:
下载然后 pip3 install 文件路径 安装 lxml
6.运行流程
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
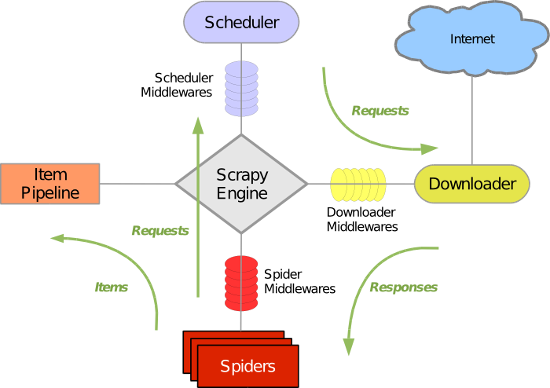
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
三、实例:
1.


1 # -*- coding: utf-8 -*- 2 import scrapy 3 from scrapy.http import Request 4 from scrapy.selector import Selector 5 from scrapy.http.cookies import CookieJar 6 7 class ChoutiSpider(scrapy.Spider): 8 #爬虫名称,必须 9 name = 'chouti' 10 #允许的url范围 11 allowed_domains = ['chouti.com'] 12 #起始url 13 start_urls = ['http://dig.chouti.com/'] 14 #维护请求cookies 15 cookie_dict = {} 16 17 def start_requests(self): 18 """ 19 根据继承的类源码,自定制自己的起始函数,如没有此函数则用 20 继承类默认的函数,本质就是生成一个生成器,next生成器做操作 21 :return:Request() 22 """ 23 for url in self.start_urls: 24 yield Request(url,dont_filter=True,callback=self.login) 25 26 def login(self, response): 27 """ 28 获取响应页面发来的cookies,分析登录请求,获取所需数据进行登录 29 :param response: 首页内容 30 :return: 31 """ 32 33 #获取cookie 34 cookie_jar = CookieJar() 35 cookie_jar.extract_cookies(response,response.request) 36 for k,v in cookie_jar._cookies.items(): 37 for i,j in v.items(): 38 for m,n in j.items(): 39 self.cookie_dict[m] = n.value 40 41 #登录需要的post数据 42 post_data = { 43 'phone':'861767712xxxx', 44 'password':'xxxx', 45 'oneMonth':1, 46 } 47 import urllib.parse 48 49 yield Request( 50 url="http://dig.chouti.com/login", 51 method='POST', 52 cookies=self.cookie_dict, 53 #将字典转化成k1=v1&k2=v2的格式,放在请求头中 54 body=urllib.parse.urlencode(post_data), 55 headers={'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8'}, 56 callback=self.show 57 ) 58 59 def show(self,response): 60 """ 61 登录成功,获取新闻列表 62 :return: 63 """ 64 yield Request(url='http://dig.chouti.com/',cookies=self.cookie_dict,callback=self.find_tag) 65 66 def find_tag(self,response): 67 """ 68 分析每一个页面取到点赞id,发送POST请求对每一个页面的文章进行点赞 69 :return: 70 """ 71 hxs = Selector(response=response) 72 link_id_list = hxs.xpath('//div[@class="part2"]/@share-linkid').extract() 73 print(link_id_list) 74 for link_id in link_id_list: 75 #获取首页所有文章ID点赞 76 link_url = 'http://dig.chouti.com/link/vote?linksId=%s' % link_id 77 yield Request(url=link_url,method="POST",cookies=self.cookie_dict,callback=self.show_res) 78 79 #获取其它分页的文章点赞 80 page_list = hxs.xpath('//div[@id="dig_lcpage"]//a/@href').extract() 81 print(1) 82 for page in page_list: 83 page_url = "http://dig.chouti.com%s" % (page,) 84 #将每一页结果重新交给这个函数,递归的执行每一页的点赞 85 yield Request(url=page_url,method='GET',callback=self.find_tag) 86 87 def show_res(self,response): 88 """ 89 显示点赞结果 90 :param response: 91 :return: 92 """ 93 print(response.text)
四、高级
1.持久化:
爬虫数据爬取后的结果经过xpath取到需要的值,可以交给爬虫主目录下的items.py的类进行规则化封装,
yield这个item,交给pipelines进行持久化处理
爬虫.py:
from ..items import Sp1Item
yield Sp1Item(url=url,text=text)
items.py:
class Sp1Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = scrapy.Field()
text = scrapy.Field()
pipeline:
1持久化: item,pipeline
pipeline执行的前提:
- spider中yield Item对象
- settings中注册
ITEM_PIPELINES = {
#权重,越小优先级越高
'sp2.pipelines.Sp2Pipeline': 300,
'sp2.pipelines.Sp2Pipeline': 100,
}
编写pipeline
class Sp2Pipeline(object):
def __init__(self):
self.f = None
def process_item(self, item, spider):
"""
:param item: 爬虫中yield回来的对象
:param spider: 爬虫对象 obj = JanDanSpider()
:return:
"""
print(item)
self.f.write('....')
return item
# from scrapy.exceptions import DropItem
# raise DropItem() 下一个pipeline的process_item方法不在执行
@classmethod
def from_crawler(cls, crawler):
"""
初始化时候,用于创建pipeline对象
:param crawler:
:return:
"""
#crawler包含爬虫相关的所有东西,.settings可读取配置文件
# val = crawler.settings.get('MMMM')
print('执行pipeline的from_crawler,进行实例化对象')
#return cls(val)
return cls()
def open_spider(self,spider):
"""
爬虫开始执行时,调用
:param spider:
:return:
"""
print('打开爬虫')
self.f = open('a.log','a+')
def close_spider(self,spider):
"""
爬虫关闭时,被调用
:param spider:
:return:
"""
self.f.close()
PipeLine是全局生效,所有爬虫都会执行,个别做特殊操作: spider.name
运行顺序:
1.首先检测 CustomPipeline类中是否有 from_crawler方法。
如果有, obj = 类.from_crawler() 此方法的本质也是实例化对象,但可以预留一些钩子,比如读取配置文件,将参数写入
如果没有,obj = 类()
2.执行obj.open_spider()方法 (1次)
3.while True:
爬虫运行,并且执行parse各种方法,如果在爬虫代码中yield了Item,则会执行obj.process_item()
4.执行完爬虫代码,执行obj.close_spider() (1次)
在2、4步骤时,整个代码运行只会进行一次,因此打开爬虫时可以打开文件或者连接数据库,close_spider时,可以关闭文件或数据库,而在爬虫运行过程中的process_item中可以进行写入操作,
如此可以避免重复打开文件或数据库,减小资源的消耗。
多个pipeline
当有多个pipeline时,默认的执行数序为p1.__init__--p2.__init__,
p1.open_spider()--p2.o...--p1.proce...--p2.pro..--p1.close_spider--p2.clo..
这样的好处是同一爬虫可以定制2个pipeline处理持久化,如一个连接数据库,
另一个写入文件中
即,在p1.process_item()中 return item,就是将item传入p2来进行处理,
如果p1的process方法执行完后,不想执行p2的process方法,则需要导入
DropItem模块,不再return item ,通过raise DropItem()即可终止p2.process方法
pipeline是全局生效,如果想对特殊爬虫特殊操作,则通过process_item中的spider
参数,通过spider.name进行单个爬虫的判断。
"""
from scrapy.exceptions import DropItem
"""
2.去重规则
scrapy默认使用的去重:settings配置文件(内部,settings文件没有)
DUPEFILTER_CLASS = 'scrapy.dupefilter.RFPDupeFilter'
DUPEFILTER_DEBUG = False
JOBDIR = "保存范文记录的日志路径,如:/root/" # 最终路径为 /root/requests.seen
实例化时from_settings读取配置文件,如配置文件没有设置,则使用默认的
去重规则,主要函数为request_seen(),用来查看url是否访问过。
需要自定义时,只需要在settings配置py文件的路径即可生效 DUPEFILTER_CLASS = 'scrapyXXX.XXX.XXX'
class RepeatUrl:
def __init__(self):
self.visited_url = set() # 放在当前服务的内存,此处可以用redis等代替
@classmethod
def from_settings(cls, settings):
"""
初始化时,调用
:param settings:
:return:
"""
return cls()
def request_seen(self, request):
"""
检测当前请求是否已经被访问过
:param request:
:return: True表示已经访问过;False表示未访问过
"""
if request.url in self.visited_url:
return True
self.visited_url.add(request.url)
return False
def open(self):
"""
开始爬去请求时,调用
:return:
"""
print('open replication')
def close(self, reason):
"""
结束爬虫爬取时,调用
:param reason:
:return:
"""
print('close replication')
def log(self, request, spider):
"""每次请求都会运行,记录日志
:param request:
:param spider:
:return:
"""
print('repeat', request.url)
3.基于信号的自定义规则:
如Django中一样,scrapy也预留了很多可以扩展的钩子,只需要在settings里面注册一下并编写类即可
EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,(文件路径,权重)
}
from scrapy import signals
class MyExtension(object):
def __init__(self, value):
self.value = value
@classmethod
def from_crawler(cls, crawler):
val = crawler.settings.getint('MMMM')
ext = cls(val)
# 在scrapy中注册信号: spider_opened,signal=signals.spider_opened指的是,
#当spider开始运行时执行,第一个参数则是指定执行哪个函数。
crawler.signals.connect(ext.opened, signal=signals.spider_opened)
# 在scrapy中注册信号: spider_closed,同理这里为spider结束时执行
crawler.signals.connect(ext.closed, signal=signals.spider_closed)
return ext
def opened(self, spider):
print('open')
def closed(self, spider):
print('close')
4.中间件
1.爬虫中间件:
class SpiderMiddleware(object):
def process_spider_input(self,response, spider):
"""
下载完成,执行,然后交给parse处理
:param response:
:param spider:
:return:
"""
pass
def process_spider_output(self,response, result, spider):
"""
spider处理完成,返回时调用
:param response:
:param result:
:param spider:
:return: 必须返回包含 Request 或 Item 对象的可迭代对象(iterable)
"""
return result
def process_spider_exception(self,response, exception, spider):
"""
异常调用
:param response:
:param exception:
:param spider:
:return: None,继续交给后续中间件处理异常;含 Response 或 Item 的可迭代对象(iterable),交给调度器或pipeline
"""
return None
def process_start_requests(self,start_requests, spider):
"""
爬虫启动时调用
:param start_requests:
:param spider:
:return: 包含 Request 对象的可迭代对象
"""
return start_requests
2.下载中间件
每次下载之前会执行,可以用来设置代理等工作,下载之后执行,可用来对下载的Response内容进一步封装
class DownMiddleware1(object):
def process_request(self, request, spider):
"""
请求需要被下载时,经过所有下载器中间件的process_request调用
:param request:
:param spider:
:return:
None,继续后续中间件去下载;
Response对象,停止process_request的执行,开始执行process_response
Request对象,停止中间件的执行,将Request重新调度器
raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception
"""
pass
def process_response(self, request, response, spider):
"""
spider处理完成,返回时调用
:param response:
:param result:
:param spider:
:return:
Response 对象:转交给其他中间件process_response
Request 对象:停止中间件,request会被重新调度下载
raise IgnoreRequest 异常:调用Request.errback
"""
print('response1')
return response
def process_exception(self, request, exception, spider):
"""
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常
:param response:
:param exception:
:param spider:
:return:
None:继续交给后续中间件处理异常;
Response对象:停止后续process_exception方法
Request对象:停止中间件,request将会被重新调用下载
"""
return None
下载器中间件