1. 场景说明:
最近一个客户进行应用切换演练,通过关闭Exadata的计算节点来模拟数据库节点出现故障,业务可能会出现的影响。
2. 遭遇故障
(1).切换演练的当晚,客户在计算节点执行init 0来关闭其中的一台计算节点。等待了10分钟左右,该主机还没有完全关闭,该主机的硬盘灯还在频繁闪烁。我感觉不太对劲,一般情况下不会这么久呀,于是回到办公区,通过命令行登录到该主机的ILOM,查看控制台信息,发现命令行的ILOM当前的日志输出为:
INFO: task rmmod:8113 blocked for more than 120 seconds.
"echo 0 > /proc/sys/kenel/hung_task_timeout_secs" disables this messag.
Call Trace:
rds_ib_remove_one=0xf0/0x110 [rds_rdma]
? autoremove_wake_funcion
ib_unregister_device
mlx4_ib_remove
mlx4_remove_device
.......
(2).因为有时命令行的ILOM日志输出和Java控制台图形界面日志输出不一致,所以我必须同时打开ILOM的Java控制台,看看图形界面的ILOM当前是什么日志输出。ILOM的Java控制台日志输出如图所示:
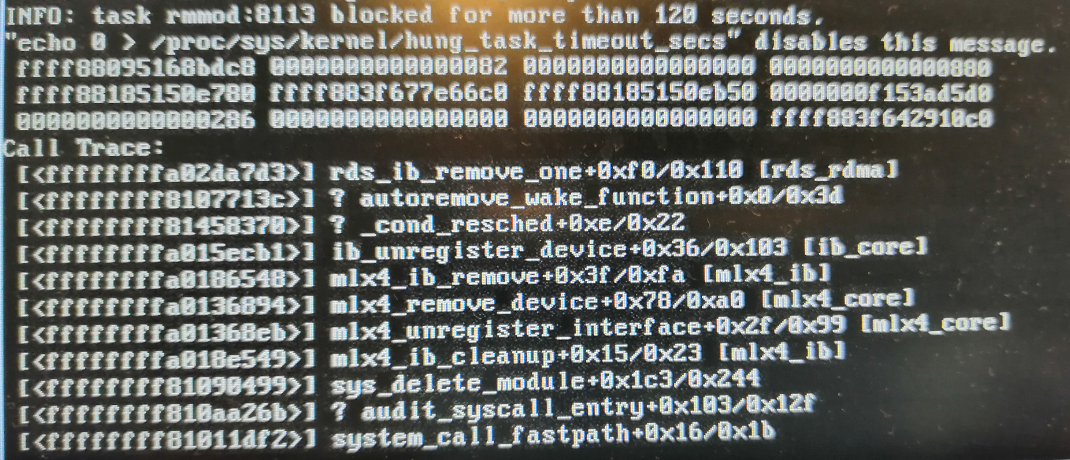
(3). 可以看出,当前系统已经出现问题,操作系统无法关闭,在关机时,系统hang住。
3. 故障分析
只能根据 Call Trace信息搜索MOS网站,找到一篇文章:Reboot Hangs Running dbnodeupdate.sh While Upgrading Exadata Db Server (Doc ID 1620826.1)
这篇文章是在Exadata进行image升级的过程中系统重启时遭遇BUG而hang住,这个BUG与升级无关,任何的重启主机操作,都有可能遭遇这个BUG。
看样子,我现在遇到的故障与这个案例完全一致。
4. 故障解决方案
永久的解决办法是:升级image版本,这个BUG是操作系统内核相关的BUG,升级image版本,也会升级操作系统的内核。
临时的解决办法是:reset /sys, 也即强制关机重启。
当天晚上,临时升级image版本是不可能的事情,手动reset /sys后,恢复正常。
什么情况会触发这个BUG,官方没有说明,但感觉与该系统长时间运行有关。(该节点连续运行了1100多天,第一次关机hang住后,手动reset /sys,恢复正常,接着再次init 0关机,而第二次关机时没有出现hang的故障)
从这个案例可以看出,以后如果有image升级之类的工作,强烈建议升级之前先重启一遍所有节点,防止在升级的过程中出现这种故障。