栈的基本概念
1.栈的定义
- 栈(Stack):只允许在一端进行插入或删除的线性表。
- 栈顶(Top):线性表允许进行插入和删除的那一端。
- 栈底(Bottom):固定的,不允许进行插入和删除的另一端。
- 空栈:不含任何元素的空表。
- 栈的操作特性为后进先出(LIFO)
- 栈的数学性质:n个不同元素进栈,出栈元素不同排列的个数为(frac{1}{n+1}C^n_{2n})
2.栈的基本操作
- InitStack(&S): 初始化一个空栈S。
- StackEmpty(S): 判断一个栈是否为空。
- Push(&S, x): 进栈,若S未满,则将x加入使之成为新栈顶。
- Pop(&S, &x): 出栈,若S非空,则弹出栈顶元素,并用x返回。
- GetTop(&S, &x): 读栈顶元素,若S非空,则用x返回栈顶元素。
- DestoryStack(&S): 销毁栈,并释放S占用的存储空间。
栈的顺序存储结构
1.顺序栈
-
顺序栈利用一组地址连续的存储单元存放自栈底到栈顶的数据元素,同时附设一个指针(top)指示当前栈顶元素的位置。
-
顺序栈的存储类型描述:
#define MaxSize 50 typedef struct { Elemtype data[MaxSize]; int top; } SqStack; -
栈顶指针:S.top,初始时设置S.top=-1
-
栈顶元素:S.data[S.top]
-
进栈操作:栈未满时,栈顶指针先加1,再赋值给栈顶元素
bool Push(SqStack &S, ElemType x) { if (S.top == MaxSize - 1) return false; S.data[++S.top] = x; return true; -
出栈操作:栈非空时,先取栈顶元素值,再将栈顶指针减1
-
栈空条件:S.top==-1
-
栈满条件:S.top==MaxSize-1
-
栈长:S.top+1
2.共享栈
- 利用栈底位置相对不变的特性,可让两个顺序栈共享一个一维数组空间,将两个栈的栈底分别设置在共享空间的两端,两个栈顶向共享空间的中间延伸。
- top0=-1时,0号栈为空,top1=MaxSize时1号栈为空
- 仅当两个栈顶指针相邻(top1-top0=1)时,判断为栈满。
- 当0号栈进栈时top0先加1再赋值,1号栈进栈时top1先减1再赋值;出栈时则刚好相反。
栈的链式存储
-
链栈的优点是便于多个栈共享存储空间和提高其效率,且不存在栈满上溢的情况。
-
通常采用单链表实现,并规定所有操作都是在单链表的表头进行的。这里规定链栈没有头结点,头指针指向栈顶元素。

-
链栈的类型描述:
typedef struct Linknode {
ELemType data;
struct Linknode *next;
} *LiStack;
队列的基本概念
1. 队列的定义
- 队列也是一种操作受限的线性表,只允许在表的一端进行插入,而在表的另一端进行删除
- 队列的操作特性是先进先出(FIFO)
- 队头(Front):允许删除的一端,又称队首
- 队尾(Rear):允许插入的一端
- 空队列:不含任何元素的空表
2. 队列常见的基本操作
- InitQueue(&Q):
- QueueEmpty(Q):
- EnQueue(&Q, x):
- DeQueue(&Q, &x):
- GetHead(Q, &x):
队列的顺序存储结构
1. 顺序队列
- 队列的顺序实现是指分配一块连续的存储单元存放队列中的元素,并附设两个指针:
- 队头指针front指向队头元素
- 队尾指针rear指向队尾元素的下一个位置
- 顺序队列的类型描述:
#define MaxSize 50
typedef struct {
ElemType data[MaxSize];
int front, rear;
} SqQueue;
- 初始状态(队空条件):Q.front == Q.rear == 0
- 进队操作:队不满时,先送值到队尾元素,再将队尾指针加1
- 出队操作:队不为空时,先取队头元素值,再将队头指针加1
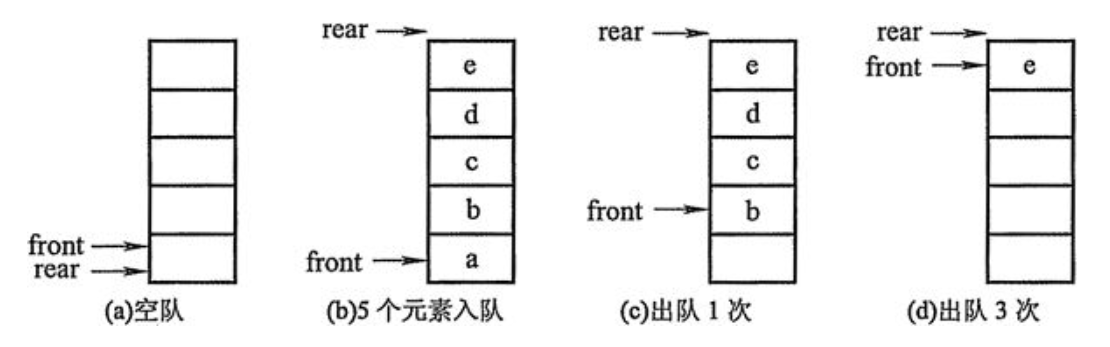
- d中仅有一个元素,此时入队出现“上溢出”,但这种一处并不是真正的溢出,在data数组中依然存在可以存放元素的空位,所以这是一种“假溢出”
2.循环队列
- 循环队列弥补了顺序队列“假溢出”的缺陷
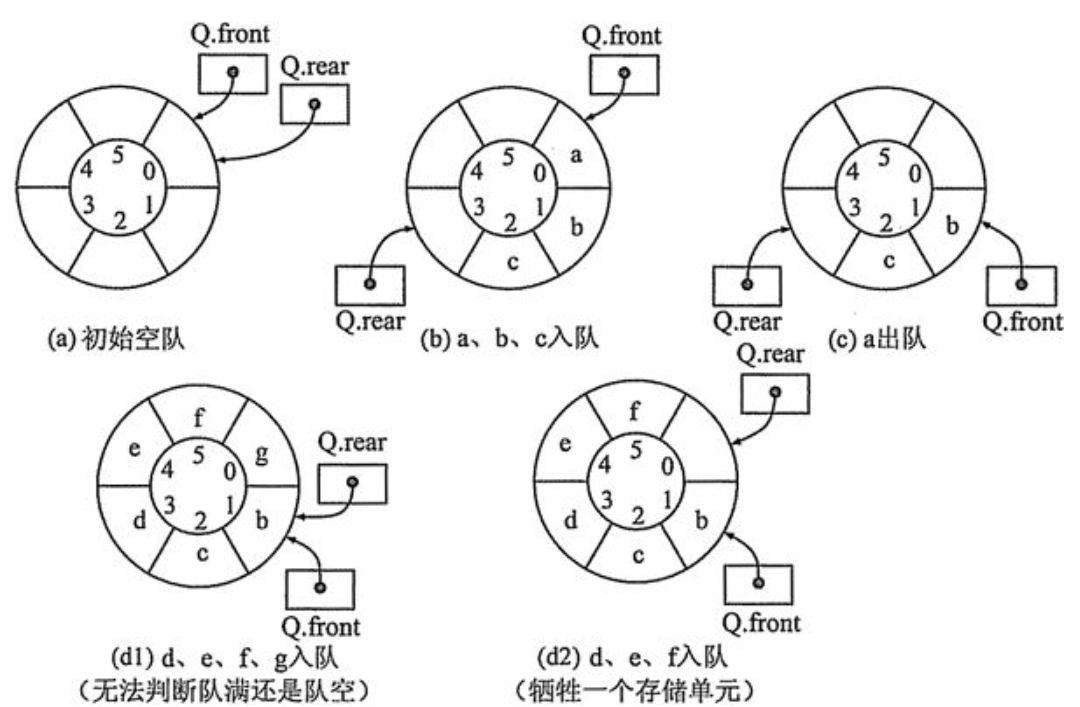
- 将顺序队列臆造为一个环状的空间,即把存储队列元素的表从逻辑上视为一个环,成为循环队列
- 当队首指针Q.front = MaxSize - 1后,在前进一个位置就自动到0,这可以利用取余运算(%)实现
- 初始时:Q.front = Q.rear = 0
- 队首指针进1:Q.front = (Q.front + 1) % MaxSize
- 队尾指针进1:Q.rear = (Q.rear + 1) % MaxSize
- 队列长度:(Q.rear + MaxSize - Q.front) % MaxSize
- 出入队时:指针都按顺时针方向进1
- 区分是队空还是队满
-
- 牺牲一个单元来区分,队头指针在队尾指针的下一位置作为队满标志,如图d2
- 队满条件:(Q.rear + 1) % MaxSize == Q.front
- 队空条件:Q.front == Q.rear
- 队列中元素个数:(Q.rear - Q.front + MaxSize) % MaxSize
-
- 类型中增设表示元素个数的数据成员。
- 队满条件:Q.size == MaxSize
- 队空条件:Q.size == 0
-
- 类型中增设tag数据成员
- 队满条件:tag == 1 && Q.front == Q.rear
- 队空条件:tag == 0 && Q.front == Q.rear
队列的链式存储结构
1. 链队列
-
实际上是一个同时带有队头指针和队尾指针的单链表
-
头指针指向队头结点,尾指针指向队尾结点(与顺序队列不同)

-
链队列的类型描述
typedef struct {
ElemType data;
struct LinkNode *next
} LinkNode;
typedef struct {
LinkNode *front, *rear
} LinkQueue;
-
队空条件:Q.front == NULL && Q.rear == NULL
-
出队时,首先判断队列是否为空,若不为空,则取出队头元素,将其从链表中摘除,并让Q.front指向下一个结点(若该节点为最后一个结点,则置Q.front和Q.rear都为NULL)
-
入队时,建立一个新结点,将新结点插入到链表的尾部,并让Q.rear指向这个新插入的结点(若原队列为空队,则令Q.front也指向该结点)
-
通常将链队列设计成一个带头结点的单链表,统一插入和删除

-
链队列适用于数据元素变动比较大的情形,而且不存在队满和溢出的问题
链栈的优点是便于多个栈共享存储空间和提高其效率,且不存在栈满上溢的情况。
通常采用单链表实现,并规定所有操作都是在单链表的表头进行的。这里规定链栈没有头结点,头指针指向栈顶元素。
链栈的类型描述:
typedef struct Linknode {
ELemType data;
struct Linknode *next;
} *LiStack;
- 队头指针front指向队头元素
- 队尾指针rear指向队尾元素的下一个位置
#define MaxSize 50
typedef struct {
ElemType data[MaxSize];
int front, rear;
} SqQueue;
- 初始时:Q.front = Q.rear = 0
- 队首指针进1:Q.front = (Q.front + 1) % MaxSize
- 队尾指针进1:Q.rear = (Q.rear + 1) % MaxSize
- 队列长度:(Q.rear + MaxSize - Q.front) % MaxSize
- 出入队时:指针都按顺时针方向进1
- 区分是队空还是队满
-
- 牺牲一个单元来区分,队头指针在队尾指针的下一位置作为队满标志,如图d2
- 队满条件:(Q.rear + 1) % MaxSize == Q.front
- 队空条件:Q.front == Q.rear
- 队列中元素个数:(Q.rear - Q.front + MaxSize) % MaxSize
-
- 类型中增设表示元素个数的数据成员。
- 队满条件:Q.size == MaxSize
- 队空条件:Q.size == 0
-
- 类型中增设tag数据成员
- 队满条件:tag == 1 && Q.front == Q.rear
- 队空条件:tag == 0 && Q.front == Q.rear
-
实际上是一个同时带有队头指针和队尾指针的单链表
头指针指向队头结点,尾指针指向队尾结点(与顺序队列不同)
链队列的类型描述
typedef struct {
ElemType data;
struct LinkNode *next
} LinkNode;
typedef struct {
LinkNode *front, *rear
} LinkQueue;
队空条件:Q.front == NULL && Q.rear == NULL
出队时,首先判断队列是否为空,若不为空,则取出队头元素,将其从链表中摘除,并让Q.front指向下一个结点(若该节点为最后一个结点,则置Q.front和Q.rear都为NULL)
入队时,建立一个新结点,将新结点插入到链表的尾部,并让Q.rear指向这个新插入的结点(若原队列为空队,则令Q.front也指向该结点)
通常将链队列设计成一个带头结点的单链表,统一插入和删除
链队列适用于数据元素变动比较大的情形,而且不存在队满和溢出的问题