十岁的小男孩
本文为终端移植的一个小章节。
目录
引言
论文
A. MobileNets
B. ShuffleNet
C. Squeezenet
D. Xception
E. ResNeXt
引言
在保证模型性能的前提下尽可能的降低模型的复杂度以及运算量。除此之外,还有很多工作将注意力放在更小、更高效、更精细的网络模块设计上,使用特定结构,如 ShuffleNet, MobileNet, Xception, SqueezeNet,它们基本都是由很小的卷积(1*1和3*3)组成,不仅参数运算量小,同时还具备了很好的性能效果。
A. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
论文地址 GitHub源码 MobilenetV1 MobilenetV2 论文解读
这篇论文是Google针对手机等嵌入式设备提出的一种轻量级的深层神经网络,取名为MobileNets。核心思想就是卷积核的巧妙分解,可以有效减少网络参数。所谓的卷积核分解,实际上就是将a × a × c分解成一个a × a × 1的卷积和一个1 ×1 × c的卷积,,其中a是卷积核大小,c是卷积核的通道数。其中第一个a × a × 1的卷积称为Depthwise Separable Convolutions,它对前一层输出的feature map的每一个channel单独进行a × a 的卷积来提取空间特征,然后再使用1 ×1 的卷积将多个通道的信息线性组合起来,称为Pointwise Convolutions,如下图:
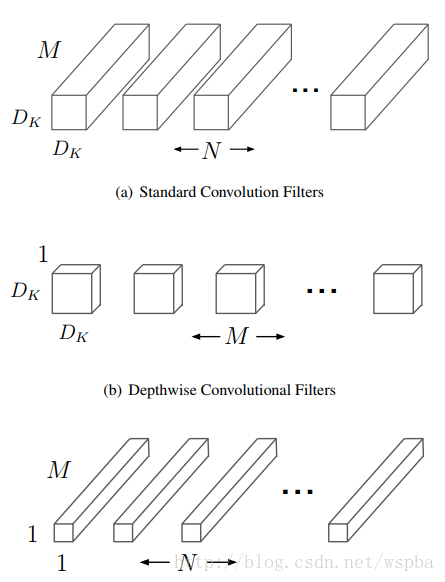
这样可以很大程度的压缩计算量:
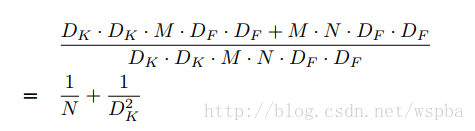
其中DK为原始卷积核的大小,DF为输入feature map的尺寸, 这样相当于将运算量降低DK^2倍左右。
MobileNet中Depthwise实际上是通过卷积中的group来实现的,其实在后面也会发现,这些精细模型的设计都是和group有关。
文章在residual net和MobileNet V1的基础上,提出MobileNet V2模型,一方面保证准确性,另一方面大幅的减少multiply-adds(MAdd)的计算量,从而减少模型的参数量,降低内存占用,又提高模型的计算速度,以适应移动端应用。
Block 基本结构
文章的主要贡献:提出一种颠倒的、bottleneck为线性变换的resdual 结构。这中结构的一个block如下:
输入:一个低维 k(通道)的、经压缩的数据
然后经过:
step 1, point wise卷积扩展维度(通道),扩展因子为t;
step 2, depthwise separable 卷积,stride为 s;
step 3, linear conv把特征再映射的低维,输出维度为 k’;
输出作为下一个block的输入,堆叠block。
具体结构如表:

1. Depthwise separable conv
这种卷积方式早已被广泛使用,实现方法是把常规卷积层分为两个独立的层。第一层称为depthwise convolution,对输入的每个通道做单独的卷积,第二层称为pointwise convolution,使用1x1的卷积核做常规卷积。
如果使用的是kxk的卷积核,这种卷积几乎能减少k2的计算量。
2. Linear bottlenecks
用线性变换层替换channel数较少的层中的ReLU,这样做的理由是ReLU会对channel数低的张量造成较大的信息损耗。ReLU会使负值置零,channel数较低时会有相对高的概率使某一维度的张量值全为0,即张量的维度减小了,而且这一过程无法恢复。张量维度的减小即意味着特征描述容量的下降。因而,在需要使用ReLU的卷积层中,将channel数扩张到足够大,再进行激活,被认为可以降低激活层的信息损失。文中举了这样的例子: 
上图中,利用nxm的矩阵B将张量(2D,即m=2)变换到n维的空间中,通过ReLU后(y=ReLU(Bx)),再用此矩阵之逆恢复原来的张量。可以看到,当n较小时,恢复后的张量坍缩严重,n较大时则恢复较好。
3. inverted residual sturcture
原residual structure 出自Deep Residual Learning for Image Recognition. 这种结构解决了深度神经网络随着网络层数的加深带来的梯度消失/爆炸,模型不收敛的问题,使DNN可以有上百甚至更多的层,提高准确率。
从图中可以看出,这种结构使用一个快捷链接(shortcut)链接了block的输入与输出(实际做的是element wise add),block内部是常规conv,一般block内部数据的维度低于block边缘–即bottleneck的数据维度。
论文的题目,inverted residual,颠倒的正是block 内数据维度与bottleneck数据维度的大小,这从上图的中数据块的深度情况可以看出。
这种颠倒基于作者的直觉:bottleneck层包含了所有的必要信息,扩展的层做的仅仅是非线性变换的细节实现。
实际上,这中翻转能节省内存,分析见后。
MobileNet V2网络结构
网络机构如下: 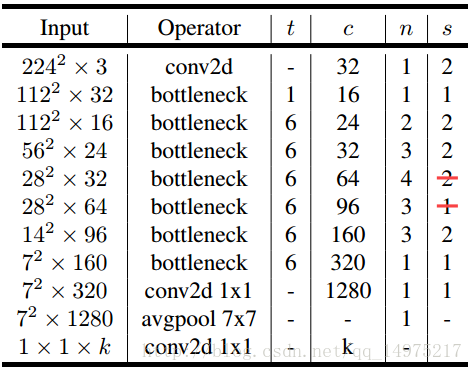
上图中,t代表单元的扩张系数,c代表channel数,n为单元重复个数,s为stride数。注意,shortcut只在s==1时才使用。
实验
文章从classification、detection、segmentation三个应用方面测试了该模型的效果。
1. classification
直接使用MobileNetV2的结构,输入图像size为224x224,在Imagenet上的分类表现
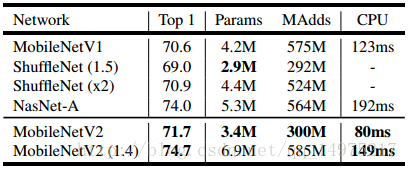
2.detection
使用预训练的MobileNetV2卷积层特征+SSD的检测网络,输入图像size为320x320,在mscoco上的表现如下表:
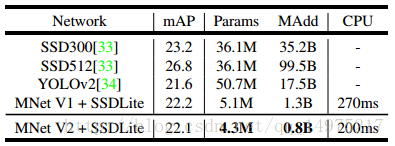
3.segementation
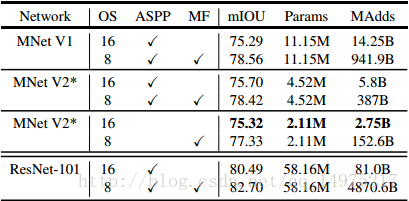
使用预训练的MobileNetV2卷积层特征+DeepLabv3分割网络
B. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
论文地址 GitHub源码 论文解读
作者提出,虽然MobileNet、ResNeXt等网络能够大大的降低模型的复杂度,并且也能保持不错的性能,但是1 ×1卷积的计算消耗还是比较大的,比如在ResNeXt中,一个模块中1 ×1卷积就占据了93%的运算量,而在MobileNet中更是占到了94.86%,因此作者希望在这个上面进一步降低计算量:即在1 ×1的卷积上也采用group的操作,但是本来1 ×1本来是为了整合所有通道的信息,如果使用group的操作就无法达到这个效果,因此作者就想出了一种channel shuffle的方法,如下图:
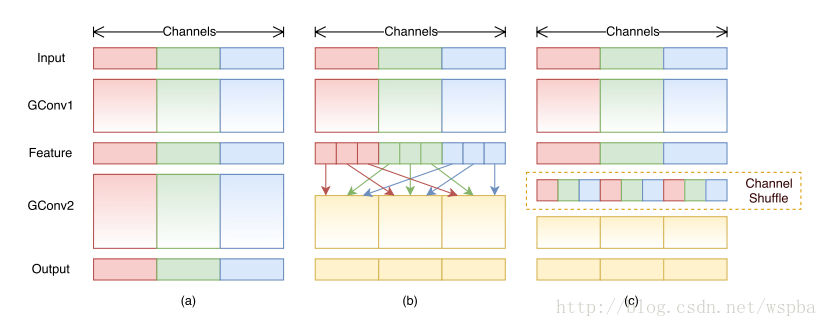
如上图b和c,虽然对1 ×1的卷积使用了group的操作,但是在中间的feature map增加了一个channel shuffle的操作,这样每个group都可以接受到上一层不同group的feature,这样就可以很好的解决之前提到的问题,同时还降低了模型的计算量,ShuffleNet的模块如下: 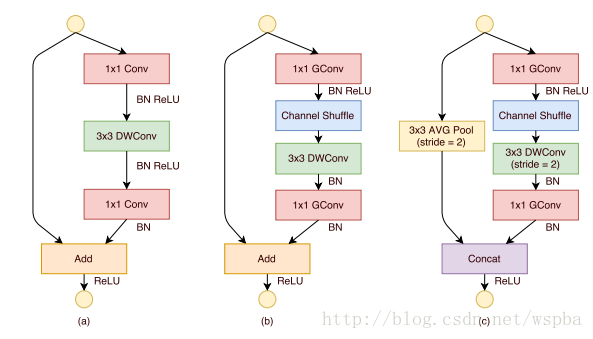
作者使用了不同的group数进行实验,发现越小的模型,group数量越多性能越好。这是因为在模型大小一样的情况下,group数量越多,feature map的channel数越多,对于小的模型,channel数量对于性能提升更加重要。
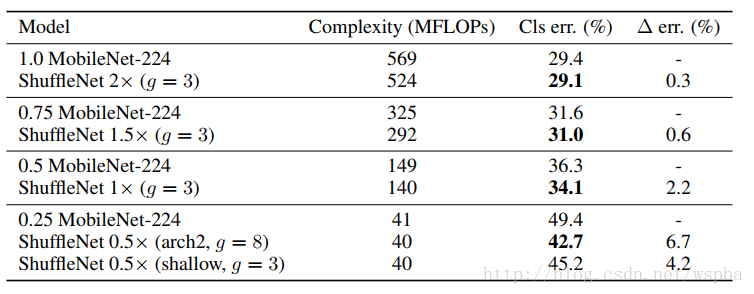
最后作者将shufflenet的方法和mobilenet的方法进行了比较,性能似乎更胜一筹:
C. Squeezenet: Alexnet-level Accuracy with 50x Fewer Parameters and <0.5MB Model Size
使用以下三个策略来减少SqueezeNet设计参数
(1)使用1∗11∗1卷积代替3∗33∗3 卷积:参数减少为原来的1/9
(2)减少输入通道数量:这一部分使用squeeze layers来实现
(3)将欠采样操作延后,可以给卷积层提供更大的激活图:更大的激活图保留了更多的信息,可以提供更高的分类准确率
其中,(1)和(2)可以显著减少参数数量,(3)可以在参数数量受限的情况下提高准确率。
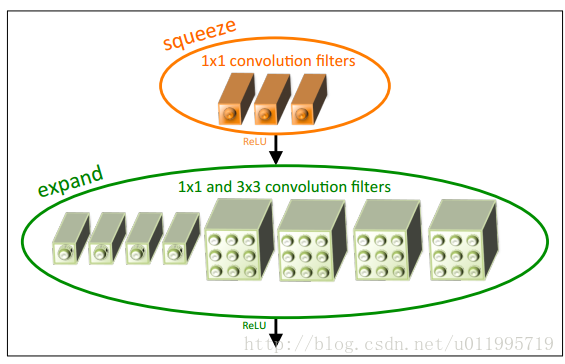
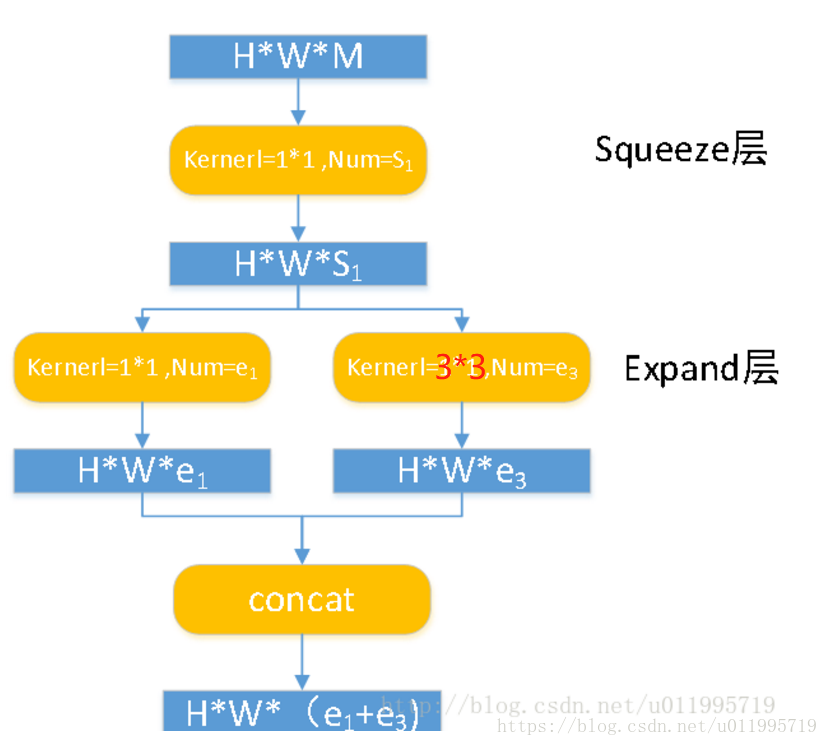
SqueezeNet的核心在于Fire module,Fire module 由两层构成,分别是squeeze层+expand层,如下图所示,squeeze层是一个1*1卷积核的卷积层,expand层是1*1 和3*3卷积核的卷积层,expand层中,把1*1 和3*3 得到的feature map 进行concat,具体操作如下图所示
D. Xception: Deep Learning with Depthwise Separable Convolutions
论文地址 GitHub源码 论文解读
极致的Inception(Extream Inception)”模块,这就是Xception的基本模块。事实上,调节每个3*3的卷积作用的特征图的通道数,即调节3*3的卷积的分支的数量与1*1的卷积的输出通道数的比例,可以实现一系列处于传统Inception模块和“极致的Inception”模块之间的状态。
运用“极致的Inception”模块,作者搭建了Xception网络,它由一系列SeparableConv(即“极致的Inception”)、类似ResNet中的残差连接形式和一些其他常规的操作组成:

E. ResNeXt:Aggregated Residual Transformations for Deep Neural Networks
作者提出,在传统的ResNet的基础上,以往的方法只往两个方向进行研究,一个深度,一个宽度,但是深度加深,模型训练难度更大,宽度加宽,模型复杂度更高,计算量更大,都在不同的程度上增加了资源的损耗,因此作者从一个新的维度:Cardinality(本文中应该为path的数量)来对模型进行考量,作者在ResNet的基础上提出了一种新的结构,ResNeXt: 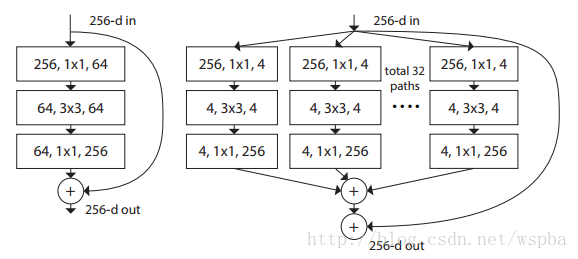
上图中两种结构计算量相近,但是右边结构的性能更胜一筹(Cardinality更大)。
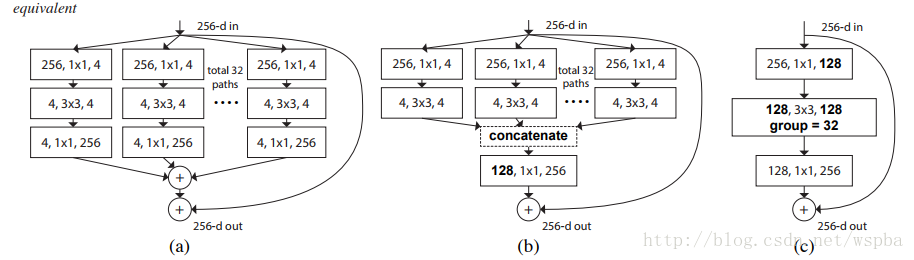
以上三种结构等价,因此可以通过group的形式来实现ResNeXt。其实ResNeXt和mobilenet等结构性质很相近,都是通过group的操作,在维度相同时降低复杂度,或者在复杂度相同时增加维度,然后再通过1*1的卷积将所有通道的信息再融合起来。因此全文看下来,作者的核心创新点就在于提出了 aggregrated transformations,用一种平行堆叠相同拓扑结构的blocks代替原来 ResNet 的三层卷积的block,在不明显增加参数量级的情况下提升了模型的准确率,同时由于拓扑结构相同,超参数也减少了,便于模型移植。
知识应该是开源的,欢迎斧正。929994365@qq.com