十岁的小男孩
本文为终端移植的一个小章节。
目录
背景
结构剪枝
非结构剪枝
背景
网络剪枝和共享用于降低网络复杂度和解决过拟合问题。有一种早期应用的剪枝方法称为偏差权重衰减(Biased Weight Decay),其中最优脑损伤(Optimal Brain Damage)和最优脑手术(Optimal Brain Surgeon)方法基于损失函数的 Hessian 矩阵减少连接的数量,他们的研究表明这种剪枝方法的精确度比基于重要性的剪枝方法(比如 weight dDecay 方法)更高。
缺陷:剪枝和共享方法存在一些潜在的问题。首先,若使用了 L1 或 L2 正则化,则剪枝方法需要更多的迭代次数才能收敛,此外,所有的剪枝方法都需要手动设置层的敏感度,即需要精调超参数,在某些应用中会显得很冗长繁重。
目前稀疏化的方法有主流的:group lasso; 控制网络结构收缩constrain the structure scale;对网络结构正则化处理regularizing multiple DNN structures。本文主要侧重于channel prune 乃至group/block等结构上稀疏化的方法。这里主要是基于图森的文章: Data-Driven Sparse Structure Selection for Deep Neural Networks。此外,如题,模型压缩是很实用的一个方向,言外之意就是工程意义很大。但是论文往往不会提及如何实际上将“繁枝”剪掉。提醒一句,就算乘以0也算FLOPs。
前图是初始网络结构,后图为预期网络结构。
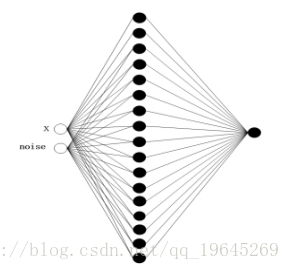
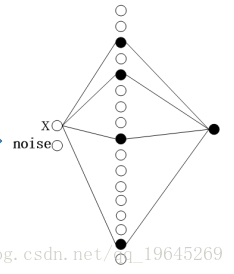
结构剪枝
深度学习模型因其稀疏性,可以被裁剪为结构精简的网络模型,具体包括结构性剪枝与非结构性剪枝。
理论
结构剪枝:是filter级或layer级、粗粒度的剪枝方法,精度相对较低,但剪枝策略更为有效,不需要特定算法库或硬件平台的支持,能够直接在成熟深度学习框架上运行。如局部方式的、通过layer by layer方式的、最小化输出FM重建误差的Channel pruning [7];全局方式的、通过训练期间对BN层Gamma系数施加L1正则约束的Network Slimming [8];全局方式的、按Taylor准则对Filter作重要性排序的Neuron Pruning [9];全局方式的、可动态重新更新pruned filters参数的剪枝方法 [10];
结构性剪枝的规整操作如下图所示:
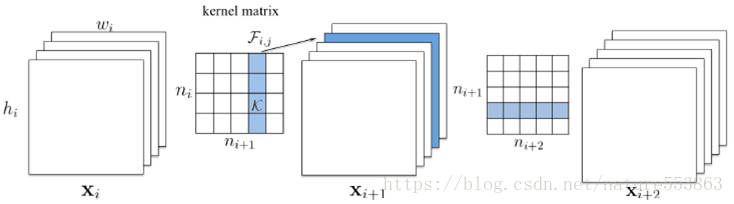
论文:
Networks Slimming
Networks Slimming-Learning Efficient Convolutional Networks through Network Slimming
思路归纳为两点:
1. 利用BN中的缩放因子gamma 作为评价上层输出贡献大小(下层输入)的因子,即gamma越小,所对应的神经元越不重要,就可以裁剪掉;
2. 利用L1正则化gamma,使其稀疏化,这样就可以在训练过程中自动评价神经元贡献大小,为0的因子可以安全剪掉。
这个思路还是很巧妙的。但是,这个方法工程上会有一个需要注意的地方。根据BN原理,需要训练的因子有两种,scale 和shift。gamma是相乘因子,之后还要加上一个shift,beta.那么,gamma很小的时候,beta是不是很大?一定要保留beta.
Sparse Structure Selection
下面介绍图森的SSS。这里没有使用BN带的gamma,而是新增加一个参数作为衡量神经元输出,每一group/block输出重要性的因子。原理很清晰,就是在每个神经元输出上,每个残差结构卷积分支上以及一些group卷积的非identity group上之输出乘上一个缩放因子。训练过程中对这些因子施加L1正则化使得其稀疏化。这样,为0的因子对应的神经元/group/block自然而然的认为对结果不重要,安全移除。
文章的思路是非常棒的,但是我认为解决L1正则化不可导的思路也很好。首先我们知道,对于不可导的L1 norm 一般使用Proximal Gradient来反传。
根据推导过程发现,我们要想使用该方法,显然要进行两次前传,代价太大。(原因就是要对重要性因子之差再进行一次然后根据牛顿动量优化器原理发现)唉,其实这个APG算法只不过比牛顿动量优化算法多出一个投影函数,而根据L1正则化Proximal Gradient原理,这个投影函数就是软阈值函数。所以,只需要在牛顿动量的优化器中对缩放因子施加软阈值函数即可,软阈值两个参数是学习率和对应缩放因子值。
该论文剪枝的实现
源码是MXNET写的。但是,这里我们发现一个问题。如开头说的,要想达到模型参数量减少目的,这只是一个开端。因为即使相乘参数为0,不把这一神经元/group/block从网络结构中拿掉,计算量不变。这是所有论文里不给说的部分,从工程上讲,这才是实际的剪枝。下面介绍一下Tensorflow如何实现剪枝。
1.前文加入缩放因子的网络已经训练完毕,稀疏化完毕。从ckpt中取出重要性因子的值,以及各神经元权重。
2.用numpy数组操作,记录小于设定阈值的元素位置,找到对应神经元数组位置,直接按channel整个切除。
3.参考以上切除之后的对应的权值数组搭建网络,以此设定张量大小。注意,block级别的稀疏,直接让输出跨过这一block即可。然而,channel级别的稀疏,由于残差结构的存在,相加位置张量channel要一致,是个坑。解决方案是不要对block最后一层的bottleneck稀疏即可。
4.应用指定变量初始化方法对重新定义的网络结构初始化,fineturn一下。
如何剪枝?
剪枝策略
-
逐层剪枝比一次性剪枝效果好
-
每层剪枝比例应根据敏感度分析去删减
-
移除滤波器时,计算L1移除值较小的比随机移除、其它计算方法效果好
-
剪枝后进行 finetune 比 train from scratch 效果好
-
剪枝后固定较为敏感的层的权值再训练的效果比较好
L_0正则化
论文:Learning Sparse Neural Networks through $L_0$ Regularization
将这篇文章总结为以下步骤,每个步骤逐步改变着模型优化问题:
1、首先从难以优化的损失函数开始:在常用的损失函数上加上L_0范数,两者线性组合。 L_0范数简单的计算了向量中的非零项,它是一个不可微分的常量函数。 所以这是一个非常困难的组合优化问题。
2、应用变分优化方法将不可微的函数转化为可微函数。这通常是通过在参数$ theta $上引入一个概率分布p_ { psi}( theta)。即使目标对于任何 theta 参数都是不可微的,但是在 p_ { psi} 下的平均损失可能是可微的w.r.t.$$ PSI。为了找到最优 psi ,通常可以使用一个增强(REINFORCE)梯度估计器,从而得到优化的策略。 但是这种方法通常具有高方差,因此我们会用步骤三的方法。
3、将重构造参数(reparametrization)技巧应用于pψ上,以此构造一个低方差梯度估计器。但是,这只适用于连续变量。为了处理离散性,我们转向步骤四。
4、使用concrete relaxation,通过连续近似逼近离散随机变量。现在我们有一个较低的方差(与REINFORCE相比)梯度估计器,可以通过反向传播和简单的蒙特卡罗采样来计算。 您可以在SGD(Adam)中使用这些梯度,也正是这篇论文做的工作。
有趣的是,步骤3并没有提到优化策略或变分优化之类的东西。取而代之的出发点是基于不同连接的spike-and-slab先验。我建议阅读这篇论文时,可以考虑到这一点。
作者表明这确实在减少参数数量方面起了作用,并且与其他方法相比更有优势。根据这些步骤,思考从一个问题转换到另一个问题,让您也可以概括或改进这个想法。例如,REBAR或RELAX梯度估计器相比其他的估计器,它能够达到无偏差和低方差的效果,而且这种方法在这个问题上也可以有很好的效果。
Fisher修剪法
论文:Faster gaze prediction with dense networks and Fisher pruning
这篇论文不是纯粹的方法,而是关注于具体应用,即如何构建一个快速神经网络来预测图像显着性。修剪网络的方法来源于在Twitter上裁剪照片的原理。
我们的目标也是为了降低网络的计算成本,特别是在迁移学习环境中:当使用预训练的神经网络开始构建时,您将继承解决原始任务所需的大量复杂性计算,而这对于解决你的目标任务可能是多余的。我们的高级(high-level)修剪方法有一个不同之处:与L0范数或组稀疏度不同,我们用一个稍微复杂的公式来直接估计方法的前向计算时间。这个公式是相邻层间相互作用的每层参数数量的二次函数。有趣的是,这样做的结果是网络结构是厚层和薄层间的交替运算,如下所示:
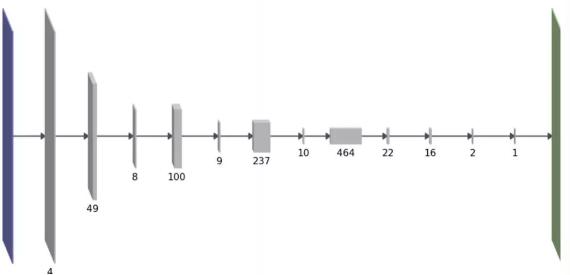
我们使用一次去掉一个卷积的特征图的方法,来修剪训练好的网络。选择下一个待修剪特征图的一个原则是尽量减少由此造成的训练损失增加。从这个原则出发,利用损失函数的二阶泰勒展开式,再做出更多的假设,我们能得到下面关于参数θi的修剪关系:
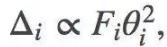
Fi表示Fisher信息矩阵的第i个对角线值。虽然上面的公式去除了单个参数,但是我们可以延伸到如何去除整个特征图。而修剪是通过去除每个迭代中具有最小Δ的参数或特征映射,并且在迭代间再重新训练网络来实现的。欲了解更多详情,请参阅论文。
除了论文中提到的内容之外,我想指出一下Fisher修剪法与我之前在这个博客上讨论过的想法之间的一些联系。
Fisher-Rao范数
第一个联系是Fisher-Rao范数。假设某一分钟Fisher矩阵信息是对角的,在理论上这是一个大而且不合理的假设,但是在应用中简化了它,就得到了能用于实践的算法。有了这个假设,θ的Fisher-Rao范数变成:
用这种形式写下来,你就能看到FR范数与Fisher修剪法之间的联系了。根据所使用的Fisher信息矩阵的特定定义,您可以近似解释FR范数,如下:
当删除一个随机参数,训练日志可能(Fisher经验信息)会按预期下降
或者当删除一个参数,由模型(Fisher模型信息)定义的条件分布的近似变化
在现实世界中,Fisher信息矩阵并不是对角的,这实际上是理解泛化的一个重要方面。首先,只考虑对角线值使Fisher修剪与网络的某些参数(非对角线雅可比矩阵)之间有些联系。但是也许在Fisher-Rao范数和参数冗余之间有更深层次的联系。
弹性权重巩固(Elastic Weight Consolidation)
使用对角Fisher信息值来指导修剪也与(Kirkpatrick等,2017)提出的弹性权重巩固有相似之处。在EWC中,Fisher信息值用于确定哪些权重能够在解决以前的任务中更重要。而且,虽然算法是从贝叶斯在线学习中推导出来的,但是你也可以像Fisher修剪那样从泰勒展开的角度来决定。
我用来理解和解释EWC的一个比喻是共享硬盘。(提醒:与其他所有的比喻一样,这可能完全没有意义)。神经网络的参数就像是某类硬盘或存储卷。训练神经网络的任务过程包括压缩训练数据并将信息保存到硬盘上。如果你没有机制来保持数据不被复写,那么该硬盘就将被复写。在神经网络中,灾难性遗忘是以同样的方式发生。EWC就像是一份在多个用户之间共享硬盘的协议,而用户不需要复写其它用户的数据。 EWC中的Fisher信息值可以被看作软件层面的不复写标志。在对第一个任务进行训练之后,我们计算出Fisher信息值,该值表示该任务的关键信息是由哪些参数存储的。Fisher值较低的是冗余的参数,其可以被重复使用并用来存储新的信息。在这个比喻中, Fisher信息值的总和就是衡量了硬盘容量的大小,而修剪实际上就是丢弃了硬盘上不用于存储任何东西的部分。
上面这两种方法/论文本身都很有趣。 L0方法看起来像是一个更简单的优化算法,可能是Fisher修剪的迭代,一次删除一个特征方法更可取。然而,当你在迁移学习中,从一个大的预训练模式开始时,Fisher修剪则更适用。
这两种方法参考博文:神经网络“剪枝”的两个方法
移除滤波器
参考论文:Pruning Filters for Efficient Convnets
对所有滤波器(filters)计算L1范数,移除值较小的滤波器。
-
优点
模型变小,运行速度变快。
-
缺点
依然保留部分冗余的连接。
1.普通卷积
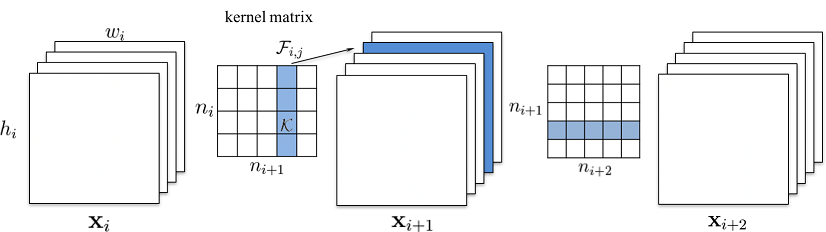
输入的特征图:xi∈Rni×hi×wixi∈Rni×hi×wi
输出的特征图:xi+1∈Rni+1×hi+1×wi+1xi+1∈Rni+1×hi+1×wi+1
不考虑 bias,参数维度:ni×ni+1×kh×kwni×ni+1×kh×kw,即有 ni+1ni+1 个 3D 滤波器 Fi,j∈Rni×kh×kwFi,j∈Rni×kh×kw
计算每个滤波器的 L1 值,取最小的若干个移除:ni+1ni+1 -> n′i+1ni+1′
这会影响后续层(卷积 / 全连接 / Batch Normalization 等)的输入:
如后续卷积层的参数维度为 n′i+1×ni+2×kh×kwni+1′×ni+2×kh×kw
2.Depthwise 卷积
Depthwise 卷积参数维度为 1×ni×kh×kw1×ni×kh×kw
后续的 Pointwise 卷积参数维度为 ni×ni+1×1×1ni×ni+1×1×1
应与后续的 Pointwise 卷积一起计算 L1:即使用 dw[0,:,:,:]⋅pw[:,i,:,:]
移除连接
移除权值小于一定阈值的连接。
参考论文:
Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding GitHub
Learning both Weights and Connections for Efficient Neural Networks
-
优点
模型变小,运行速度变快。
能尽可能去掉冗余的连接。
-
缺点
需要设计更稀疏的格式保存模型,否则模型不变小也不加速。
合并Batch Normalization
Batch Normalization 的参数可以合并到上一个卷积/全连接的参数中。如设卷积的参数为 WW, bb,则卷积可表示为 y=Wx+by=Wx+b;
Batch Normalization 的参数为 scale, bias, mean, variance
Batch Normalization 可表示为 y=scalevariance+ε√⋅x+(bias−scale⋅meanvariance+ε√)y=scalevariance+ε⋅x+(bias−scale⋅meanvariance+ε)
Batch Normalization 的参数合并后卷积的参数为
W′=W⋅scalevariance+ε√W′=W⋅scalevariance+ε
b′=(b−mean)⋅scalevariance+ε√+bias
非结构剪枝
通常是连接级、细粒度的剪枝方法,精度相对较高,但依赖于特定算法库或硬件平台的支持,如Deep Compression [5], Sparse-Winograd [6] 算法等;
知识应该是开源的,欢迎斧正,929994365@qq.com
参考文献:
https://blog.csdn.net/HongYuSuiXinLang/article/details/82592585
https://blog.csdn.net/LiJiancheng0614/article/details/79513085