Pandas整体内容概要
本文整体介绍
- Pands的数据结构
- Pands的读取与保存
- 数据的基本操作:数据的查看、检查、选择、删减、填充
- 数据的处理:合并、聚合、分组、filter、sort、groupBy
- 函数应用与映射
- 数据的简单可视化
Pandas 是非常著名的开源数据处理库,其基于 NumPy 开发,该工具是 Scipy 生态中为了解决数据分析任务而设计。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的函数和方法。
我们可以通过它完成对数据集进行快速读取、转换、过滤、分析等一系列操作。除此之外,Pandas 拥有强大的缺失数据处理与数据透视功能,可谓是数据预处理中的必备利器。
1.Pandas的数据结构
特有的数据结构是 Pandas 的优势和核心。简单来讲,我们可以将任意格式的数据转换为 Pandas 的数据类型,并使用 Pandas 提供的一系列方法进行转换、操作,最终得到我们期望的结果。
Pandas 的数据类型主要有以下几种,它们分别是:
- Series(一维数组)
- DataFrame(二维数组) -- 是不是与sparkSQL等大数据框架中的DataFrame很类似,其实可以理解就是一个东西,一个二维表格 + 一个Schema = 一个DataFrame,或 Series + Series = DataFrame
- Panel(三维数组)
- Panel4D(四维数组)
- PanelND(更多维数组)
其中 Series 和 DataFrame 应用的最为广泛,本文仅对 Series 和 DataFrame 进行讨论
Series
Series 是 Pandas 中最基本的一维数组形式。其可以储存整数、浮点数、字符串等类型的数据。
其基本结构为:
pandas.Series(data=None, index=None)
data 可以是字典,或者NumPy 里的 ndarray 对象等
index 是数据索引
可以看出,其结构与Array或者List等数据结构也有相似型,每个数据都有个索引,可以根据索引快速定位数据。
Series的生成
通过传入一个iterable对象,比如列表、range对象、迭代器等都可以生成一个Series。pd.Series方法可以自动给生成一个0开始的索引,也可以指定索引

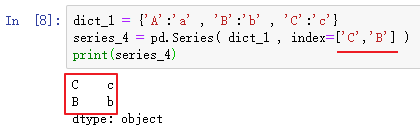
也可以传入Python的字典来创建Series,则key为索引,value为数据
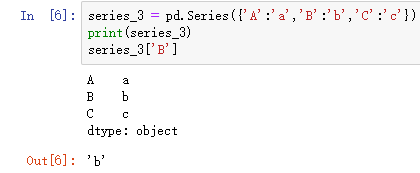
注意: 特别声明,在创建Series时指定的index的优先级要高于values,表现在生成的Series严格按照指定的index排序,执行下列语句体会一下
由于 Pandas 基于 NumPy 开发。那么 NumPy 的数据类型 ndarray 多维数组自然就可以转换为 Pandas 中的数据。而 Series 则可以基于 NumPy 中的一维数据转换。
s = pd.Series(np.random.randn(5))
其他访问方式
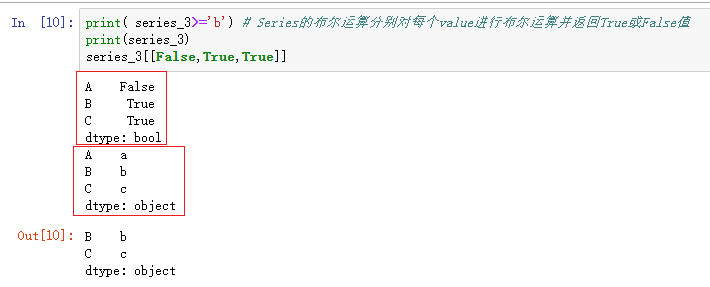
相比传统的数据结构,Series拥有更高层的访问索引方式,比如序列索引、布尔索引

因为布尔索引是非常常用的一种索引方式,所以这里再强调一下。布尔索引实质上就是传入布尔值组成的iterable对象比如[False,True,True] , 通过布尔运算 series_3 >= 'b 得到的结果其实就是[False,True,True]
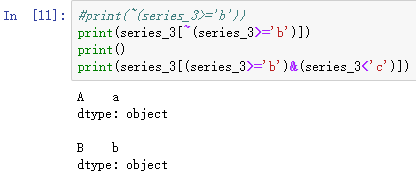
布尔运算可以通过'与'(&)、'或'(|)、'非'(~)进行组合运算 , (每一个计算项一定要加括号,注意运算符的优先级)
DataFrame

关于DataFrame在不同技术栈中的不同理解,其实本质是相同的,左图是pandas中的理解,右图为spark DataFrame的经典图示
其实可以理解就是一个东西,一个二维表格 + 一个Schema = 一个DataFrame,或 Series + Series = DataFrame
dataframe是在Series的基础上添加了一个轴,原来的行索引index称为0轴(axis=0),新增轴列索引columns称为1轴(axis=1) 1轴的优先级要高于0轴
由python对象可以快速创建DataFrame , 同Series一样,没有指定index会由pandas自动创建
dict_2 = {'A':[1,2,3],'B':['a','b','c']} # 1轴优先级高,指定key时表示的是1轴,如果想要类似Series一样指定index,需要用嵌套字典
dataframe_1 = pd.DataFrame(dict_2,index=range(1,4)) # 可以指定index
dataframe_1
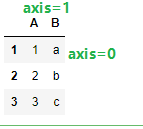
也可以指定列索引的顺序
dataframe_2 = pd.DataFrame(dict_2,index=range(1,4),columns=['B','A']) # 同上面演示的Series的index一样,可以指定列索引的顺序
dataframe_2
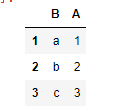
获取列索引

默认对dataframe进行索引是执行列索引,得到一个Series,指定的column退化为Series的name属性
# 两种访问方式都可以
print(dataframe_2.B )
print(dataframe_2['B'] )
#访问某个元素,先指定列再指定行
print(dataframe_2['A'][2]) #2不可以加引号,为索引号

添加或修改某一列的值
添加或修改某一列只需要类似赋值的操作,赋值一个iterable对象

指定 series或者dict会对index/key进行匹配,只赋值key与index匹配的value

删除columns:两种方法
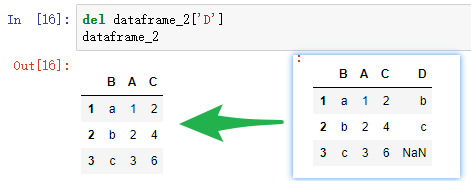

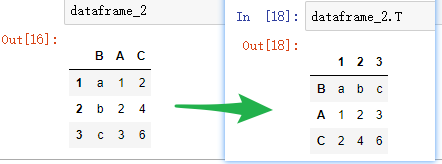
行列转置(0轴和1轴的转置)
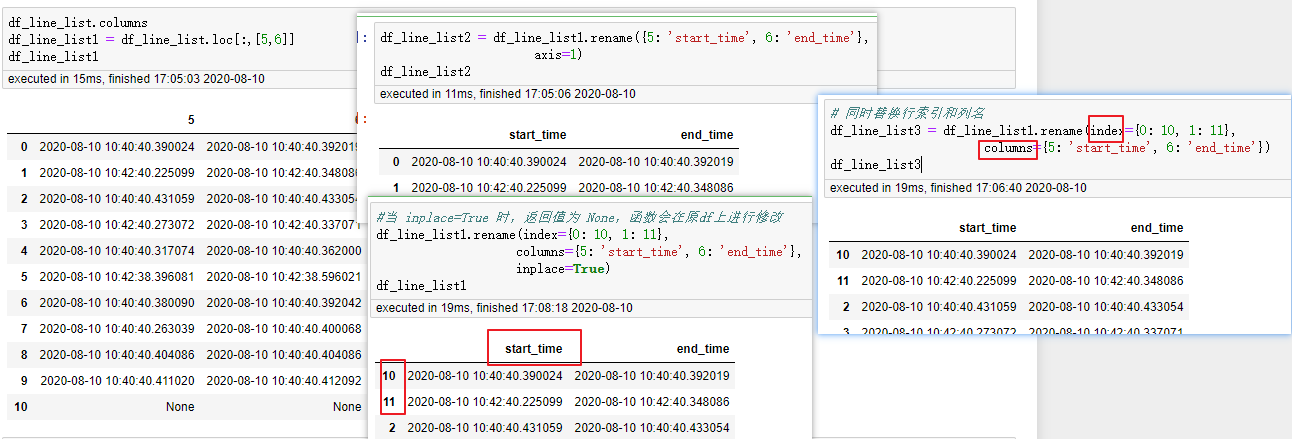
补充:对已存在的DataFrame修改其索引或列名
工作中遇到了相应对列名或行索引修改的情况,特补充如下:
当对行进行split后,转换为DataFrame时,其行索引回事int的1,2,3,这与列名不相符,故对需要的字段进行改名
# 方式一:
df_line_list2 = df_line_list1.rename({5: 'start_time', 6: 'end_time'},
axis=1) # 此处 axis='columns'也可以
df_line_list2
# 方式二: 同时替换行索引和列名
df_line_list3 = df_line_list1.rename(index={0: 10, 1: 11},
columns={5: 'start_time', 6: 'end_time'})
df_line_list3
#当 inplace=True 时,返回值为 None,函数会在原df上进行修改
df_line_list1.rename(index={0: 10, 1: 11},
columns={5: 'start_time', 6: 'end_time'},
inplace=True)
df_line_list1
2.数据的读取与保存
数据的读取
pandas的I/O API是一组read函数,比如pandas.read_csv()函数。这类函数可以返回pandas对象。相应的write函数是像DataFrame.to_csv()一样的对象方法。下面是一个方法列表,包含了这里面的所有readers函数和writer函数。
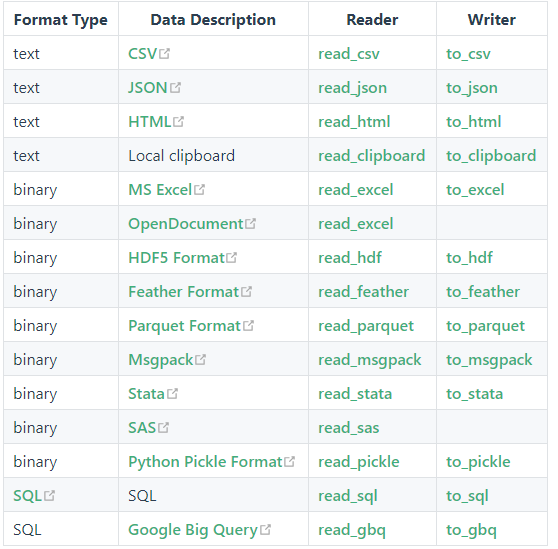
该部分可参见官方文档,或pandas中文网 https://www.pypandas.cn/docs/user_guide/io.html#csv-文本文件
- pd.read_csv(filename):从CSV文件导入数据
- pd.read_table(filename):从限定分隔符的文本文件导入数据
- pd.read_excel(filename):从Excel文件导入数据
- pd.read_sql(query, connection_object):从SQL表/库导入数据
- pd.read_json(json_string):从JSON格式的字符串导入数据
- pd.read_html(url):解析URL、字符串或者HTML文件,抽取其中的tables表格
- pd.read_clipboard():从你的粘贴板获取内容,并传给read_table()
- pd.DataFrame(dict):从字典对象导入数据,Key是列名,Value是数据
常用的方法的读取参数解释 - pd.read_csv(filename):从CSV文件导入数据
下列为常用的参数及解释
| 参数 | 解释 | 必填/非必填 |
|---|---|---|
| filepath_or_buffer | 文件路径 | 必填 |
| sep | 指定分隔符,默认逗号',' | 非必填 |
| header | 指定第几行作为表头。默认为0(即第1行作为表头),若没有表头,需设置header=None,可以是int或list。 | 非必填 |
| names | 指定列的名称,用list表示,默认None | 非必填 |
| index_col | 指定行索引,可以是一列或多列,默认None | 非必填 |
| usecols | 需要读取的列,可以使用列序列也可以使用列名,默认None | 非必填 |
| prefix | 给列名添加前缀。如prefix=x,会出来X0,X1,....,默认None | 非必填 |
| skiprows | 需要忽略的行数(从文件开始处算起),或需要跳过的行号列表(从0开始),默认None | 非必填 |
| skipfooter | 需要忽略的行数(从最后一行开始算) | 非必填 |
| nrows | 需要读取的行数(从文件头开始算起),默认None | 非必填 |
| encoding | 编码方式,乱码时使用,默认None | 非必填 |
| 另附上公司大佬整理的常用参数,以供参考,膜拜大佬 | ||
 |
数据的保存
常用的方式,更全面请详见官档
- df.to_csv(filename):导出数据到CSV文件
- df.to_excel(filename):导出数据到Excel文件
- df.to_sql(table_name, connection_object):导出数据到SQL表
- df.to_json(filename):以Json格式导出数据到文本文件
loc/iloc方式访问DataFrame
3. 数据的基本操作:数据的检查、查看、选择、删减、填充
在pandas中,使用的最多的数据结构是series和DataFrame,以下操作更多的基于这两者进行。

常用数据检查方法
| 常用方法 | 介绍 |
|---|---|
| df.head() | 默认显示前 5 条 |
| df.tail(7) | 指定显示后 7 条,不填为5条 |
| df.describe() | 对数据集进行概览,会输出该数据集每一列数据的计数、最大值、最小值,std,25%,50%,75%值等 |
| df.values | 将 DataFrame 转换为 NumPy 数组 |
| df.index | 查看索引 |
| df.columns | 查看列名 |
| df.shape | 查看形状,如(n,m)n行m列 |
| df.mean() | 返回所有列的均值 |
| df.corr() | 返回列与列之间的相关系数 |
| df.count() | 返回每一列中的非空值的个数 |
| df.median() | 返回每一列的中位数 |
| ... | count,min,max,std.. |
| pd.isnull() | 检查DataFrame对象中的null值,并返回一个Boolean数组 |
| pd.notnull() | 检查DataFrame对象中的非null值,并返回一个Boolean数组 |
| pd.isna() | 检查DataFrame对象中的空值(null和''),并返回一个Boolean数组 |
| pd.notna() | 检查DataFrame对象中的非空值(非null和非''),并返回一个Boolean数组 |
| s.value_counts(dropna=False) | 查看Series对象的唯一值和计数 |
| df.apply(pd.Series.value_counts) | 查看DataFrame对象中每一列的唯一值和计数 |
常用数据查看选择方法
在数据预处理过程中,我们往往会对数据集进行切分,只将需要的某些行、列,或者数据块保留下来,输出到下一个流程中去。这也就是所谓的数据选择,或者数据索引。由于 Pandas 的数据结构中存在索引、标签,所以我们可以通过多轴索引完成对数据的选择。
基于索引数字选择
当我们新建一个 DataFrame 之后,如果未自己指定行索引或者列对应的标签,那么 Pandas 会默认从 0 开始以数字的形式作为行索引,并以数据集的第一行作为列对应的标签。其实,这里的「列」也有数字索引,默认也是从 0 开始,只是未显示出来
我们可以用.iloc 方法对数据集进行基于索引数字的选择。Selection by Position i可理解为index,与下方的loc区分开
该方法可接受的索引为:
- 整数;
- 整数构成的列表或数组,例如:[1, 2, 3];
- 布尔数组;
- 可返回索引值的函数或参数。
选择示例
| 方法 | 介绍 |
|---|---|
| df.iloc[:3] | 选择前3行,类似Python的切片 |
| df.iloc[5] | 选择特定一行 |
| df.iloc[[1, 3, 5]] | 选择1,3,5行,注意不是 df.iloc[1, 3, 5],df.iloc[] 的 [[行],[列]] 里面可以同时接受行和列的位置 |
| df.iloc[:, 1:4] | 选择2-4列,注意:df.iloc[] 的 [[行],[列]] 里面可以同时接受行和列的位置 |
| df.iloc[:3, 1:4] | 选择前3行的2-4列,#访问指定的index和columns,注意此处指的是索引,所以是前闭后开区间 |
基于标签名称选择
直接根据标签对应的名称选择,为 df.loc[]。loc为Selection by Label函数
df.loc[] 可以接受的类型有:
- 单个标签。例如:2 或 'a',这里的 2 指的是标签而不是索引位置。
- 列表或数组包含的标签。例如:['A', 'B', 'C']。
- 切片对象。例如:'A':'E',注意这里和上面切片的不同之处,首尾都包含在内。
- 布尔数组。
- 可返回标签的函数或参数。
| 常用方法 | 介绍 |
|---|---|
| df.loc[0:2] | 访问前3条(和index无关,和顺序有关) |
| df.loc[[0, 2, 4]] | 选择1,3,5行 |
| df.loc[:, 'A':'B'] | 选择A,B列 |
| df.loc[:, 'A':] | 选择A列后面的列 |
数据删减/清理
| df.drop(labels=['A','B'], axis=1) | 直接去掉数据集中指定的列和行。一般在使用时,我们指定 labels 标签参数,然后再通过 axis 指定按列或按行删除即可。 |
| df.drop_duplicates | 剔除数据集中的重复值。使用方法非常简单,指定去除重复值规则,以及 axis 按列还是按行去除即可 |
| df.dropna() | 删除所有包含空值的行 |
| df.dropna(axis=1) | 删除所有包含空值的列 |
| df.dropna(axis=1,thresh=n) | 删除所有小于n个非空值的行 |
数据填充/替换
| 常用方法 | 介绍 |
|---|---|
| df.fillna(x) | 用x替换DataFrame对象中所有的空值(null和''),也可以添加参数method='pad'和method='bfill'使用缺失值前面/后面的值进行完全填充,可通过limit= 参数设置连续填充的限制数量 |
| df.fillna(df.mean()['C':'E']) | 通过C,E列的平均值来填充na值 |
| s.astype(float) | 将Series中的数据类型更改为float类型 |
| s.replace(1,'one') | 用‘one’代替所有等于1的值 |
| s.replace([1,3],['one','three']) | 用'one'代替1,用'three'代替3 |
| df.rename(columns=lambda x: x + 1) | 批量更改列名 |
| df.rename(columns={'old_name': 'new_ name'}) | 选择性更改列名 |
| df.set_index('column_one') | 更改索引列 |
| df.rename(index=lambda x: x + 1) | 批量重命名索引 |
插值填充
还有一种比较符合数据趋势的填充方式,插值填充,是利用数据的变化趋势来填充
# 生成一个 DataFrame
df = pd.DataFrame({'A': [1.1, 2.2, np.nan, 4.5, 5.7, 6.9],
'B': [.21, np.nan, np.nan, 3.1, 11.7, 13.2]})
df
df_interpolate = df.interpolate() # 线性插值
df_interpolate
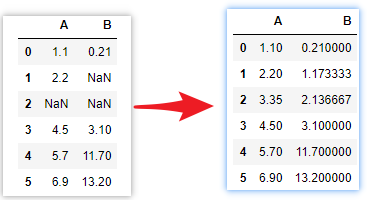
下面是插值插入的两个数据,

对于 interpolate() 支持的插值算法,也就是 method=。建议
- 如果你的数据增长速率越来越快,可以选择 method='quadratic'二次插值。
- 如果数据集呈现出累计分布的样子,推荐选择 method='pchip'。
- 如果需要填补缺省值,以平滑绘图为目标,推荐选择 method='akima'。
最后提到的 method='akima',需要你的环境中安装了 Scipy 库。除此之外,method='barycentric' 和 method='pchip' 同样也需要 Scipy 才能使用
4. 数据的处理:合并、聚合、分组、filter、sort、groupBy
合并
- merge 实现两个DataFrame通过value或index连接成一张宽表的操作,是基于column连接
- join 基于两个DataFrame的索引进行合并,是基于索引连接
- concat 两个DataFrame按照0轴或1轴拼接成一个DataFrame(即行拼接或列拼接)
merge方法
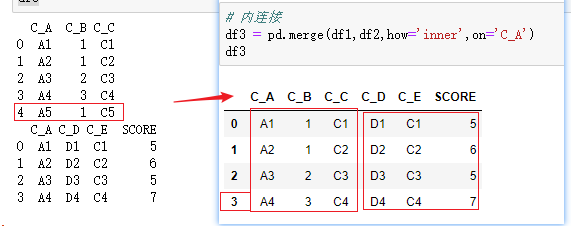
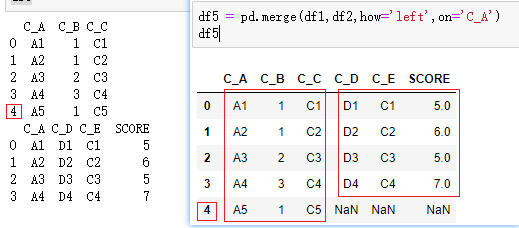
pd.merge(df1,df2,how='inner',on='column')
参数
df1/df2:左/右位置的dataframe。
how:数据合并的方式。left:基于左dataframe列的数据合并;right:基于右dataframe列的数据合并;outer:基于列的数据外合并(取并集);inner:基于列的数据内合并(取交集);默认为'inner'。
on:用来合并的列名,这个参数需要保证两个dataframe有相同的列名。on=['A','B']
left_on/right_on:左/右dataframe合并的列名,也可为索引,数组和列表。
left_index/right_index:是否以index作为数据合并的列名,True表示是。
sort:根据dataframe合并的keys排序,默认是。
suffixes:若有相同列且该列没有作为合并的列,可通过suffixes设置该列的后缀名,一般为元组和列表类型。
整体效果,与SQL中的join操作类似,就是制定连接方式,按on的列进行join,然后以how的方式输出DataFrame。
测试数据如下:
内连接
左连接
另外,外连接写作outer,右连接写作right ;和SQL的join效果简直一模一样。

join方法
join方法是基于index连接dataframe,merge方法是基于column连接,连接方法有内连接,外连接,左连接和右连接,与merge一致。
join和merge的连接方法类似,与merge很相似,直接用merge方法就ok了。
concat方法
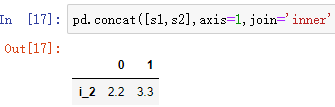
concat方法是拼接函数,有行拼接和列拼接,默认是行拼接,拼接方法默认是外拼接(并集),拼接的对象是pandas数据类型。
series类型,行拼接和列拼接


注:也可在其中添加参数,join='inner' 默认是以并集的方式拼接的
dataframe类型,行拼接和列拼接
dataframe类型的行拼接
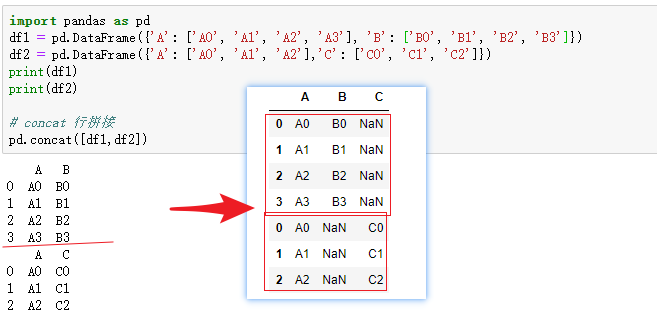
dataframe类型的列拼接

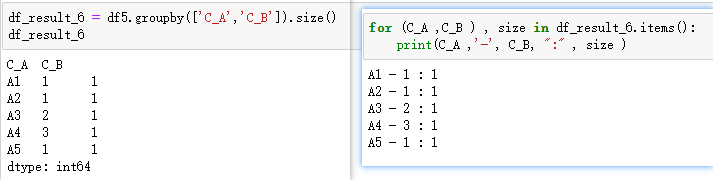
分组
size方法直接获取分组后每组的大小
5. 函数应用与映射
- map() 将一个自定义函数应用于Series结构中的每个元素
- apply() 将一个函数作用于DataFrame中的每个行或者列
- applymap() 将函数做用于DataFrame中的所有元素
map()
map() 是一个Series的函数,将一个自定义函数应用于Series结构中的每个元素(elements),注意DataFrame结构中没有map()

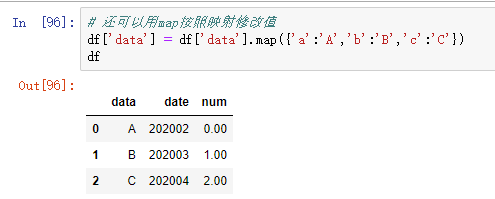
apply()
apply() 针对DataFrame在每行或者每列上执行计算 (支持维度变化: n==>1 返回Series 、 n ==>m 返回DataFrame)
基于上一步的df继续操作:

apply中还可搭配逻辑判断,或者value_counts()效果很佳
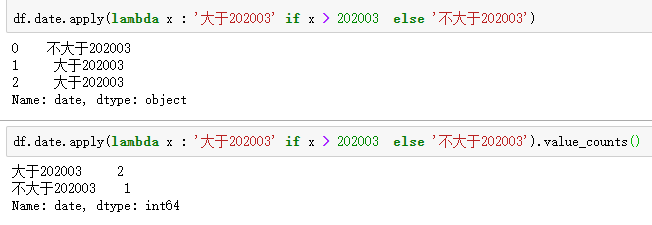
applymap()
applymap()
以下案例为向DataFrame中的每个元素添加‘!’结尾,以下两种方式是等效的
