一、使用AVG、SUM、MAX、MIN
AVG 平均值
SUM 求和
MAX 求最大值
MIN 求最小值
SELECT SUM(A.DEPTNO),min(A.DEPTNO),avg(A.EMPNO),SUM(A.EMPNO) FROM SCOTT.EMP A;

1.1 null空值除了count(*),不参与AVG、SUM、MAX、MIN运算。
1.2 MAX和MIN一起写时的优化
SQL>SELECT MAX(OBJECT_ID),MIN(OBJECT_ID) FROM T; ---效率差,选择INDEX FAST FULL SCAN SELECT MAX_VALUE,MIN_VALUE FROM (SELECT MAX(OBJECT_ID) MAX_VALUE FROM T) A, (SELECT MIX(OBJECT_ID) MIX_VALUE FROM T) B; ---效率高,选择INDEX FULL SCAN (MIN/MAX)
二、使用count
count(1) 和 count(*) 有什么区别?答案是没区别。是一样的。count(IDSTICT a.deptno) 是去重,不包括空值。
三、GROUP BY 子句和HAVING 子句
group by 是分组,having 是对分组以后的过滤
SQL>select d.deptno,count(*) counts FROM scott.emp d GROUP BY d.deptno HAVING count(*)>4 and d.deptno>20 ---这里不能使用别名counts ORDER BY counts desc;
SQL>SELECT d.object_type,d.owner,count(*) counts FROM dba_objects d group by d.object_type,d.owner ---这里设置了两个分组 having count(*)>1000 order by counts desc;
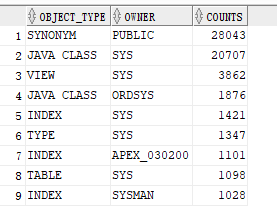
数据库对象中最多的就是同义词 SYNONYM,然后就是 JAVA CLASS,视图view,索引index,表table,等。
在语句中将HAVING 和 GROUP BY 子句放在 WHERE 子句的后面,将 ORDER BY 子句放在最后。
WHERE 子句-----GROUP BY 子句-----HAVING子句-----ORDER BY 子句