摘要
许多音频处理任务需要感知评估。获得人类判断的“黄金标准”是耗时、昂贵的,并且不能用作优化标准。另一方面,自动化度量的计算效率很高,但通常与人类判断的相关性很差,尤其是在人类检测的阈值处的音频差异。在这项工作中,我们通过将深度神经网络拟合到一个新的众包人类判断的大数据集来构建一个度量。受试者被提示回答一个简单、客观的问题:两个录音是否相同?这些对是在各种扰动下通过算法生成的,包括噪声、混响和压缩伪像;探索扰动空间的目的是有效地识别对象的刚刚可察觉的差异(JND)水平。我们表明,最终学习的度量标准与人类的判断很好地校准,优于基线方法。因为它是一个深度网络,所以度量是可微的,这使得它适合作为其他任务的损失函数。因此,用我们的度量简单地替换现有的损失(例如,深度特征损失)在去噪网络中产生了显著的改进,这是通过主观成对比较来测量的。
1. 介绍
人类天生具有分析和比较声音的能力。虽然已经努力通过自动方法模拟人类的判断,但是人类和机器的判断之间的差距仍然很大[见图1]。这种差距在基于深度学习的合成音频环境中尤为明显[1],深度学习已经变得如此现实,以至于大多数指标都无法反映人类的感知。许多深度学习模型依赖于一个度量来计算它们的损失函数;损失和人的判断之间的不一致会产生听觉假象。因此,对感知一致性度量的需求阻碍了音频处理的发展。
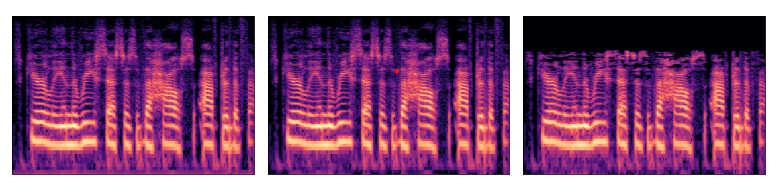
图1:音频1包含白噪声,而音频2受带宽限制:哪一个听起来“更接近”参考录音?现有的客观度量标准(例如,L1、L2、PESQ和ViSQOL)难以衡量JNDs,并且通常与人类的判断不一致,不像深度嵌入和我们的模型。
基于人类评估研究,研究人员开发了相对于参考录音评估声音质量的指标,例如PESQ [2],POLQA [3]和ViSQOL [4]。然而,这些方法有两个普遍的缺点。首先,这些模型有公认的缺点,如对感知不变变换的敏感性[5,6],这阻碍了在更多样的任务中的稳定性,如语音增强。其次,这些指标是不可区分的,因此不能直接作为深度学习环境中的培训目标。
为了解决后一个问题,研究人员训练了可区分的神经网络,将这些感知模型纳入其中,例如在每次训练迭代时估计PESQ[7,8]。Zhang等人的[7]方法在每一步都用昂贵的梯度估计阻碍训练,而Fu等人的[8]方法未能对未见的扰动进行建模。
另一种方法是通过对抗学习(GANs)学习损失函数,这种方法在增强[9]、合成[10]和分离[11]方面显示出了很好的效果。另一种方法采用计算机视觉社区的深度特征丢失[12]概念,通过使用从不同任务学习到的表示构造相似度量[13]。这一理念已被用于各种音频任务[14,15]。然而,这些方法都是针对特定问题的[16,17],需要人工评估才能准确评估,特别是当需要测量较小的感知差异时。
我们提出了一种新的基于显著差异(JNDs)的感知音频度量——一个差异被感知到的最小变化。为此,我们首先收集了一个大规模的人类判断数据集,其中受试者被问到一个简单的问题:两段录音听起来是相同的还是不同的。通过注入各种常见的音频处理任务中常见的退化特性的扰动来修改录音,包括噪声、混响、均衡失真和压缩。数据收集过程依赖于主动学习,以有效地对JND级别附近的工件进行取样。接下来,我们用这些数据训练一个神经网络,并使用学习到的表示构造一个距离度量,以测量两个音频信号之间的差异。我们验证了新的度量,显示它与三个不同的现有平均意见得分(MOS)数据集,以及三个两备选强迫选择测试(2AFC)数据集有良好的相关性。最后,我们证明了使用新的度量作为损失函数可以改善目前最先进的去噪网络的性能。
因此,我们的贡献如下:(1)为录音收集众包人类JND判断的框架;(2)基于这些数据训练的可区分感知损失模型;(3)实验表明,与标准度量相比,该模型与金属氧化物半导体测试的相关性更好;(4)在最先进的语音增强网络中的可证明的改进,其中通过我们的模型增强了损失函数;(5)数据集、代码和结果度量以及听力测试示例都可以从我们的项目页面获得:https://pixl.cs.princeton.edu/pubs/Manocha_2020_ADP/
2.拟议框架
我们使用众包工具收集人类判断数据集,这些工具的性能与专家实验室测试类似[18,19];然后我们根据这些数据建立一个模型。
2.1 通过主动学习收集数据
我们给一个听众两个录音,一个参考${x_{ref}}$和扰动信号${x_{per}}$,问这两个录音是否完全相同或不同,并记录二进制响应$h in left{ {0,1} ight}$。对于参考记录${x_{ref}}$,我们首先从一个大的集合中采样一个语音记录,然后通过随机应用一组扰动(例如噪音和混响)降低它的质量。为了产生扰动记录${x_{per}}$,我们选择一个扰动方向,或“轴”,它可以是几个扰动类型之一或顺序应用的组合。图2显示了一个例子,其中扰动方向是两种扰动类型的组合。我们研究的类型将在第3.1节中进一步描述。扰动记录${x_{per}}$是作为强度$ ho in left[ {0,100} ight]$的函数H产生,${x_{per}} = { m H}left( {{x_{ref}}, ho } ight)$。
对于过大或过小的ρ值,答案分别是“明显”不同或相同的,下游度量不太可能从这样的数据中获得信息。因此,与过去的[20]方法相比,我们采用了一种主动学习策略来有效地收集标记数据。我们的目标是识别适当的显著差异(JND)阈值,${ ho _{jnd}}$,这样受试者就能听到${x_{ref}}$和${x_{per}}$之间的区别。我们试图对ρ进行采样,使其接近JND点,如图2的高层所示。
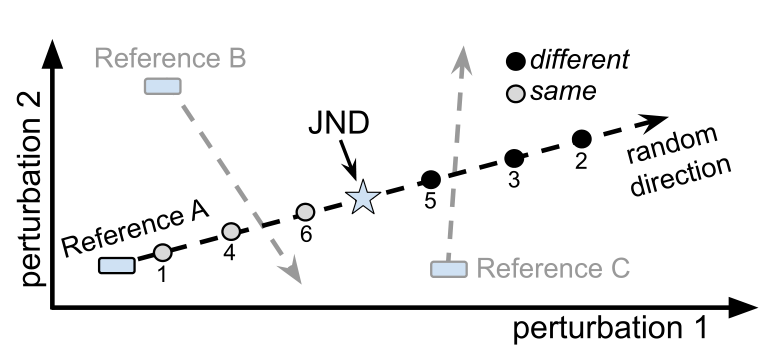
图2:对数据收集的主动学习的描述从每个参考中,我们沿着一个随机的组合扰动向量(虚线)探查JND。连续的听者响应(编号)表明录音的声音与参考的(空心点)相同或不同。
基于所有过去的答案,我们估计当前主题最可能的JND $ ho _{jnd}^ * $,然后通过${x_{per}} = { m H}left( {{x_{ref}}, ho _{jnd}^ * } ight)$产生下一个测试用例。我们假设人类的答案服从一个高斯分布,在JND点的均值为µ,方差为σ2,表示人类误差。接着,我们用$Lleft( {mu ,{sigma ^2}} ight) = Pi _{j = 1}^Nleft( {1 - {h_j}} ight)left( {1 - cleft( {{ ho _j}|mu ,{sigma ^2}} ight)} ight) + {h_j}cleft( {{ ho _j}|mu ,{sigma ^2}} ight)$,其中${ ho _1}, ldots ,{ ho _N}$是过去摄动强度,${h_1}, ldots ,{h_N}$是人的判断,$cleft( {{ u _j}|mu ,{sigma ^2}} ight)$是高斯$Nleft( {mu ,{sigma ^2}} ight)$的CDF。在计算µ和σ来最大化上述似然函数之后,下一个测试用例从$ ho _{jnd}^ * = mu$开始。我们的数据收集的最终产品是一个三元组$left{ {{x_{ref}},{x_{per}},h} ight}$的数据库,我们利用它来训练一个感知度量。
2.2 训练感知度量
一个高质量的感知距离度量D将提供一个小的距离$Dleft( {{x_{ref}},{x_{per}}} ight)$,如果人类判断他们是相同的记录,和一个大的距离,如果他们被判断为不同的。这里,我们将探索四种不同的策略来学习这种度量。然后,我们研究每种方法与人类判断的相关性。所有的模型都有相同的架构来进行比较,如3.3节所述。
使用预先训练过的网络。“现成的”深度网络嵌入已被用作训练的度量标准,并已被证明与视觉设置[13]中的人类感知判断很好地相关,即使没有明确地训练人类感知判断。我们首先调查在音频设置中是否存在类似的趋势。我们将l层深度网络嵌入的l层激活描述为${F_l}left( x ight) in {mathbb{R}^{{{ m T}_l} imes {C_l}}}$,其中${T_l}$和${C_l}$分别表示该层的时间分辨率和通道数量。两个音频记录之间的距离可以通过对完整功能激活栈音频记录之间的平均来定义。
$$Dleft( {{x_{ref}},{x_{per}}} ight) = sumlimits_l {frac{1}{{{T_l}{C_l}}}{{left| {{F_l}left( {{x_{ref}}} ight) - {F_l}left( {{x_{per}}} ight)} ight|}_1}}$$
我们按照[14]中的策略,就DCASE 2016 [21]中的两个一般音频分类任务,即音频场景分类(ASC)和家庭音频标记(DAT),训练一个模型(pre)。
在感知数据上训练模型。我们把上面的F模型加上线性权重,
$$Dleft( {{x_{ref}},{x_{per}}} ight) = sumlimits_l {frac{1}{{{T_l}{C_l}}}{{left| {{omega _l} odot left( {{F_l}left( {{x_{ref}}} ight) - {F_l}left( {{x_{per}}} ight)} ight)} ight|}_1}}$$
其中${omega _l} in mathbb{R}_l^C$和$ odot $是Hadamard的产品通道,线性权重有效地决定了哪些通道或多或少是“感知的”。我们提出三种变体。首先,我们保持所有层F的权重不变,只训练线性层。这给出了现成网络的“线性校准”,表示为lin。第二,我们从一个预先训练的分类模型(pre)初始化,并允许网络(F和线性层)的所有权重被微调,表示为fin。第三,我们允许网络F和线性层都从头开始训练。
培训目标。我们的网络F在末尾有一个小的分类网络G,它将这个距离$Dleft( {{x_{ref}},{x_{per}}} ight)$映射到预测的人类判断$mathop hlimits^ wedge $。我们最小化这个预测值和ground truth人类判断h之间的二进制交叉熵(BCE):
$$Lleft( {G,D} ight) = BCEleft( {Gleft( {Dleft( {{x_{ref}},{x_{per}}} ight)} ight),h} ight)$$
3.实验装置
我们现在从第2节开始描述框架中的实验
3.1 扰动空间
我们将该框架应用于广泛的语音通信领域。在这个领域中,噪声如数据包丢失、抖动、可变延迟和其他信道噪声如信道噪声和侧音是常见的。
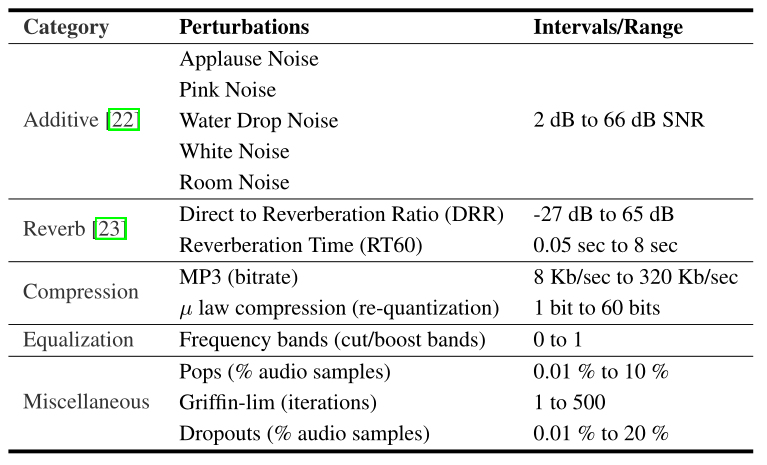
表1列出了我们研究的所有扰动及其范围。对于每个听力测试集,我们从每个类别中最多选择一个实例,并按照随机顺序对这些类别进行采样,例如加性噪声能量、混响DRR、压缩MP3比特率、均衡(EQ)和pops作为五个扰动值(v1、v2、v3、v4、v5)。我们改变订单以模拟不同的场景。例如,(混响,附加,EQ,压缩,pops)模拟远程通信,而(压缩,EQ,混响,pops,附加)在房间环境中模拟播放音频。
表1:所有检查的扰动和配置。
3.2 数据收集的众包
在确定扰动空间后,我们在Amazon Mechanical Turk (AMT)上众包JND答案。我们要求工人拥有95%以上的支持率。在人类智能任务(HIT)的开始阶段,受试者要进行音量电平校准测试,交替播放响亮和柔和的声音。然后参与者被要求不要在敲击的中途改变音量。接下来,会进行一项注意力测试,参与者被要求辨认一个长句子中听到的单词。这样可以排除那些不懂英语或没有注意的参与者。在成功地选择了正确的单词后,实验对象会经历两次教学测试,在我们开始实际任务之前,我们会训练工人们寻找什么样的差异。每一击包含30对两两比较,每10对随机选择的参考和方向。在这30个比较中,有6个(20%)测试是以明显的音频变形的形式出现的前哨问题。如果参与者答错了6个问题中的任何一个,我们将丢弃他们的数据。每段录音大约2.5秒长,如果参与者愿意,他们可以重放这些文件。通常情况下,完成一项攻击需要7-8分钟。在最后,我们还会询问参与者关于他们的经验的意见/建议/评论。我们发布了2000个点击量,并在验证后保留了1812个点击量,收集了大约55k对人类的主观判断。
我们验证得到的数据集具有所需的属性:
1.相同或不同答案的平衡数量:我们的主动学习策略预测听众给出的所有先前答案的JND。在JND这个点上,听者同样有可能说出完全相同或不同的答案,因此如果我们的模型确实运行良好,我们应该观察到在我们的数据集中有几乎相等数量的“相同”或“不同”答案。这正是我们观察到的——我们观察到25782个“相同”到26130个“不同”的答案。
2.个体一致性检查:我们检查听众给出的所有答案和他们最终预测的JND水平之间的一致性;低于JND的噪音水平应该说“相同”,高于JND的应该说“不同”。用户同意的低值意味着听众随机回答和/或我们的JND预测方法不准确,而高值意味着我们的模型正确预测了JND,并且用户没有随机回答。用户同意率在88.3%左右,算是高了。
3.3 培训和建筑
我们使用了一个受[14]启发的网络,该网络由14个具有3×1核的卷积层、批量归一化和泄漏ReLU单元以及零填充组成,以在每一步之后将输出维度减少一半。从第一层的32个通道开始,每5层后通道的数量加倍。我们还在所有卷积层中使用丢弃。网络的感受野是214-1。我们使用交叉熵损失来训练模型,交叉熵损失使用将距离映射到预测的人类判断的小分类模型。
我们训练该网络1000个epoch,使用1个GeForce RTX 2080 GPU,耗时约3天即可完成。作为在线数据增强的一部分,为了使模型对小延迟不发生变化,我们随机地决定是在音频的开头还是结尾添加0.25s的静默,然后将其呈现给网络。这有助于为模型提供移位不变性属性,以消除当时间移位时音频实际上是相似的。
4. 结果
4.1 主观验证
我们使用先前发表的各种大型第三方研究来验证我们训练的指标与他们的任务很好地相关。我们展示了我们模型的结果,并将其与自监督模型(例如openl3[24])和大规模预训练模型(例如在音频集[26]上训练的vggish[25])以及更传统的客观指标(如MSE、PESQ[2]和ViSQOL[3])获得的嵌入结果进行了比较。
我们使用斯皮尔曼秩序相关(SC)和皮尔逊相关系数(PC)计算模型预测距离与公开可用的MOS分数之间的相关性。这些相关分数是对每个说话者进行评估的我们对每个说话者在每种情况下的平均分数。
作为扩展,我们还检查了2选强迫选择测试(2AFC)的准确性,在这个测试中,我们提供了一个参考录音和两个测试录音,并询问听众哪一个听起来更像参考录音。每一个三连音大约由10个听者来评估。2AFC检查每个样本基础上相似度的精确排序,而MOS检查聚合排序、规模和一致性。我们选择四类不同的可用数据集进行分析:
1. VoCo[27]:由MOS测试组成,以验证6种不同的词合成和插入算法的质量,因此不是采样对齐数据。
2. FFTnet[28]:由5种不同的语音生成算法生成的合成音频的MOS测试组成。它引入了特定于SE(语音增强)的伪影,并且由于相位变化而没有对样本进行对齐。2AFC研究包括2050个干净的参考和嘈杂的测试录音。
3.带宽扩展[29]:包括三种不同带宽扩展算法的MOS测试,目的是通过填充缺失的高频信息来提高采样率。这些音频样本包含非常细微的高频差异。2AFC研究包括1020组干净参考和噪声测试录音。
4.模拟的:由1210个干净的参考和噪声测试记录的三元组组成,它们来自我们在第3.1节中描述的扰动空间。
表2:Spearman (SC)、Pearson (PC)和2AFC准确性。模型包括:我们的、(自我)监督的嵌入,以及传统的度量标准。↑更好
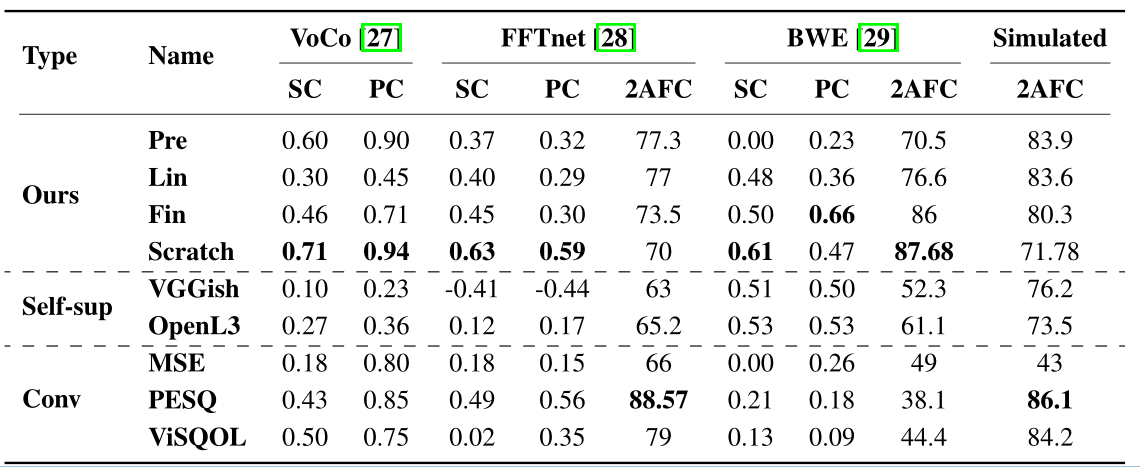
结果显示在表2中,我们提出的方法“scratch”总体性能最好。我们还总结了其他一些值得注意的观察结果,如下:
•基于神经网络的指标对非采样对齐的数据更加稳健——我们看到,我们的大多数模型,包括pre,在V oCo和FFTnet中的非采样对齐合成音频样本上表现得比传统指标更好。
•PESQ和VISQOL在FFTnet和模拟数据集上具有更好的2AFC精度,但MOS分数较低,这表明这些方法保持了顺序而不是规模。我们还观察到,pre具有更高的2AFC准确性,但MOS分数稍低,这表明它学习的是知觉排序,而不是量表。有趣的是,它在上述两个2AFC数据集上的表现优于scratch,这表明在(相关)分类上的训练可能产生与排序更相关的特征(A比B更接近C)。根据JND数据进行调整可以被认为是在刻度上进行校准(多少A接近于多少C)。
•尽管预模型对非样本对齐的数据是稳健的,但它在揭示高频细微差异方面存在问题。很可能是因为这个模型是在一个不依赖这些频段的任务(声音分类)上训练出来的。相反,VGGish和OpenL3的表现相对较好,因为它们是在更大规模的任务上训练的(AudioSet [26]),因此更依赖于高频感知特征。然而,他们在前两项任务中表现较差,这可能是因为他们没有直接接受语音训练。
•传统的度量标准,如PESQ和ViSQOL,在VooCO和FFTnet上的表现优于BWE,这表明它们在测量细微差异时与人类感知的相关性较低。
•依赖谱图差异的方法(如VGGish、OpenL3、MSE)与MOS相关性较差。虽然声谱图对小位移相对稳定,但相位变化会使振幅不稳定[30],导致随机变化。当两个信号非常相似时,这种变化变得占主导地位,导致频谱图差异波动,从而与人类感知去相关,如我们在VoC和FFTnet情况下所见。
•OpenL3在任务间的性能优于VGGish。这可能是因为OpenL3是使用自我监督来训练的,将视觉和听觉映射到同一个嵌入空间,这比分类保留了更多的信息。
4.2 使用训练损失的语音增强
我们展示了我们训练的度量作为语音增强(SE)任务的损失函数的效用。我们使用[31]中可用的数据集,包括大约11,572个用于训练的语句和824个用于验证的文件。本数据集包含28个扬声器,平均分为男性和女性扬声器,包含10种独特的背景类型,横跨4种不同的信噪比。我们去噪网络(独立于学习损失网络)由16层完全卷积上下文聚合网络组成,如[14]。为了公平比较,我们保持SE模型的大小不变。我们从我们训练的损失函数的所有14层计算损失,并将它们相加得到总的损失。我们使用Adam Optimiser[32],学习速率为10−4,训练400个epoch。
我们将我们的SE模型与最先进的基于深度特征丢失[14]的方法以及其他一些值得注意的基线包括Wavenet[33]、OMLSA[34]和Wiener Filter[35]进行了比较。我们从[31]的验证集中随机选取600条有噪声的录音,并使用上述算法对其进行增强。我们对AMT进行A/B偏好测试,包括我们与基线两两比较。每一对都由15个不同的土耳其人打分,然后大多数人投票决定哪一种方法表现更好。为了分析这些结果,我们将结果分为4组:从输入噪声最高(困难)到输入噪声最低(容易)。结果如图3所示。所有结果均具有统计学意义,p < 10−4。
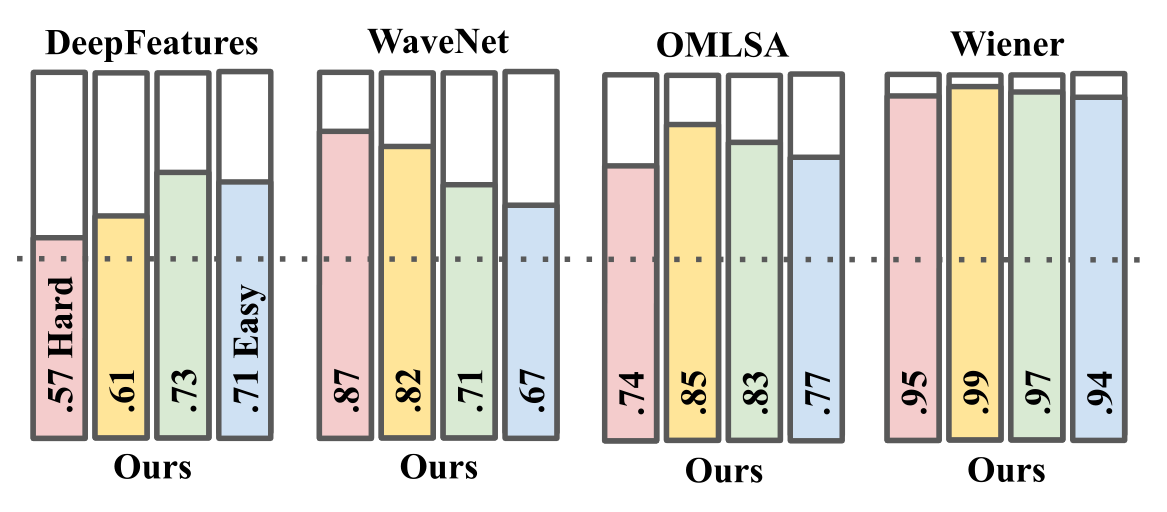
图3:去噪方法的两两比较我们的方法(下面)优于每个基线(上面)。结果根据难度被划分为从粉色=困难到蓝色=容易的部分。概率为50%(虚线)。↑对我们来说更好。
我们观察到,我们的模型在所有基线方法的所有噪声水平上都是首选的。特别是对比我们的和deepfeatures,我们观察到我们的模型在高信噪比记录中表现最好,在高信噪比记录中,由强背景噪声引起的退化不太明显。这突出了在JND数据上训练我们感知损失的有用性。考虑到我们的损失函数是根据JND数据训练的,它能够比其他损失函数更好地与局部的、微妙的差异相关联。
5. 结论与未来工作
我们提出了一个框架来收集人类对音频信号的“明显差异”判断。直接从我们的数据中学习一个感知指标会产生一个比传统指标(如PESQ[3])更好地与MOS测试相关联的指标。我们还表明,预先训练分类任务的模型有正确的顺序,但不正确的感知尺度,可以通过训练我们的数据校准。此外,在语音增强的任务中,我们证明了度量可以作为一个损失函数直接优化。在计算机视觉文献中也出现了类似的情况,与传统指标(如SSIM[37])相比,训练过的网络既能很好地与人类感知判断[13]相关,也能很好地作为优化目标[36]。
我们希望在未来扩展该数据集,以探索更广泛的扰动类型,并在更大的强度范围内以更大的样本密度进行探索。我们也希望包括除了演讲以外的内容,尤其是音乐。这些数据可以用来更广泛地研究音频感知的多种形式,并支持更广泛的应用。