一、项目背景
随着时代的发展,国人对于阅读的需求也是日益增长,既然要阅读,就要读好书,什么是好书呢?本项目选择以豆瓣图书网站为对象,统计其排行榜的前250本书籍。
二、项目介绍
本项目使用Python爬虫技术统计豆瓣图书网站上排名前250的书籍信息,包括书名、作者、出版社、出版日期、价格、评星、简述信息
将获取到的信息存储在Mysql数据库中
三、项目流程
3.1 分析第一页
第一页地址为:https://book.douban.com/top250,打开后页面呈现为如下:
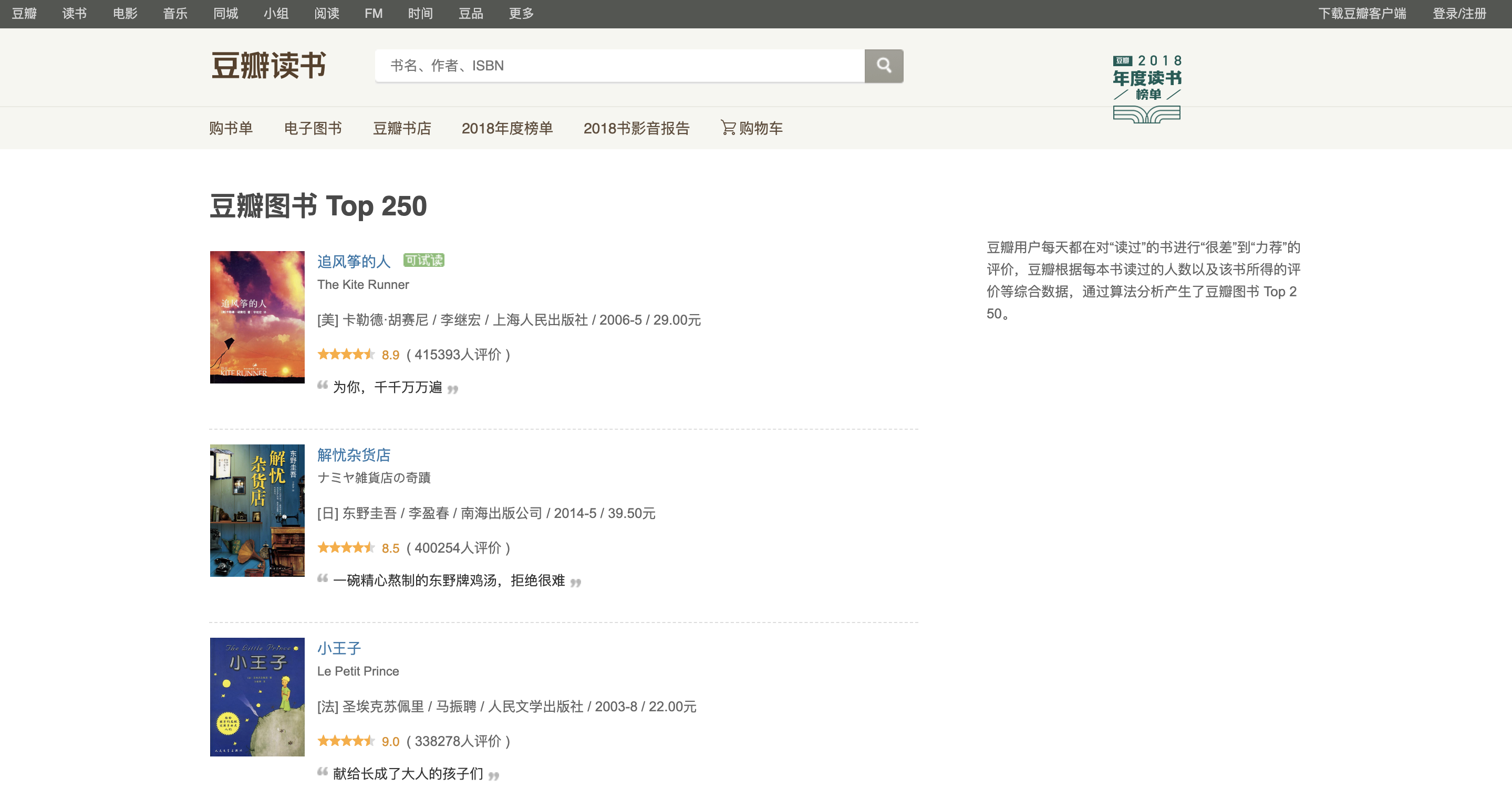
我们需要获得的信息为每一本书的所有信息:
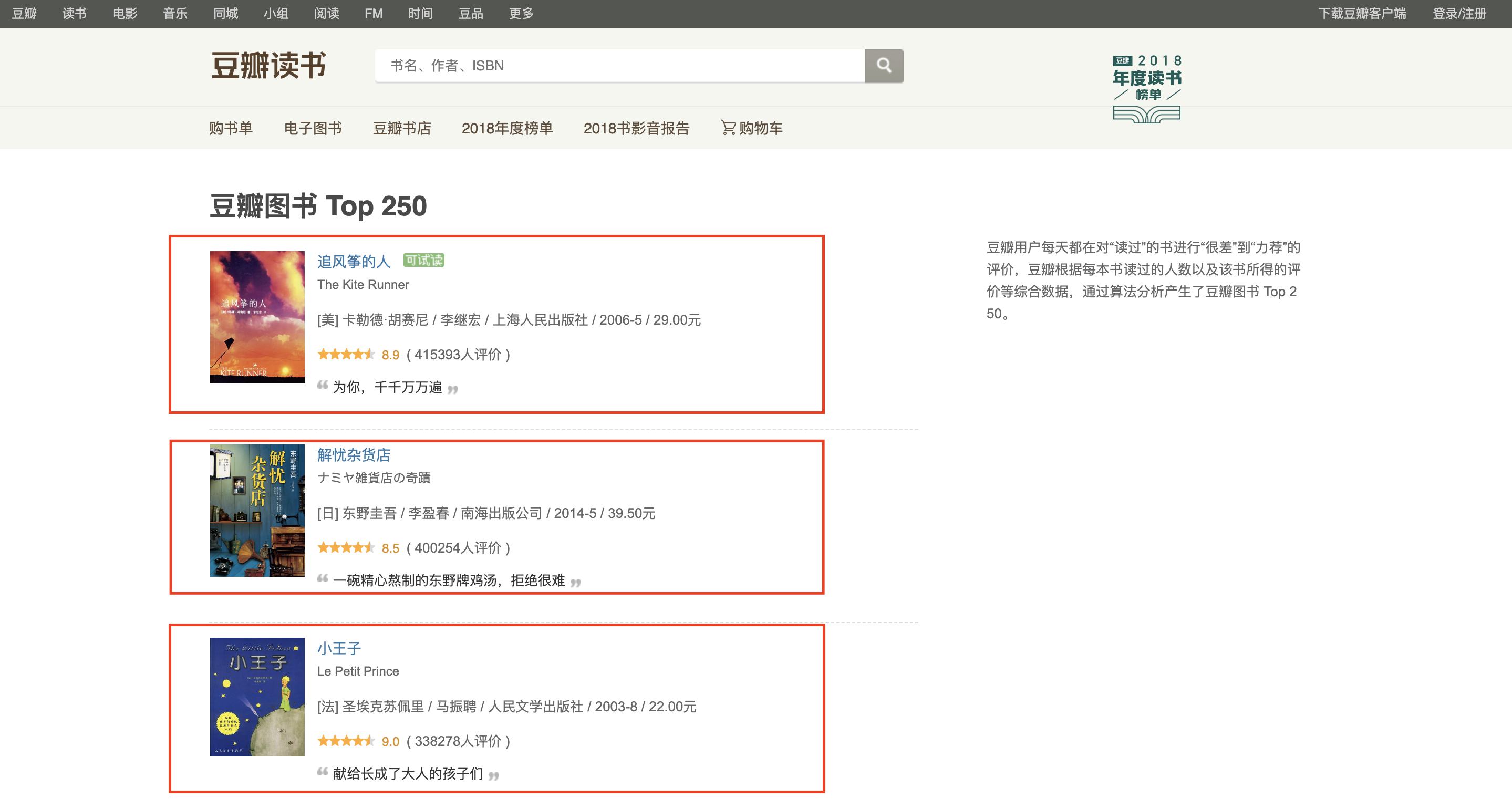
所以思路为:
解析这一页--->得到这一页所有图书的信息
3.2 解析第一页
使用开发者模式查看网页源代码(Chrome浏览器按F12),选择network后,刷新网页,效果如下图:
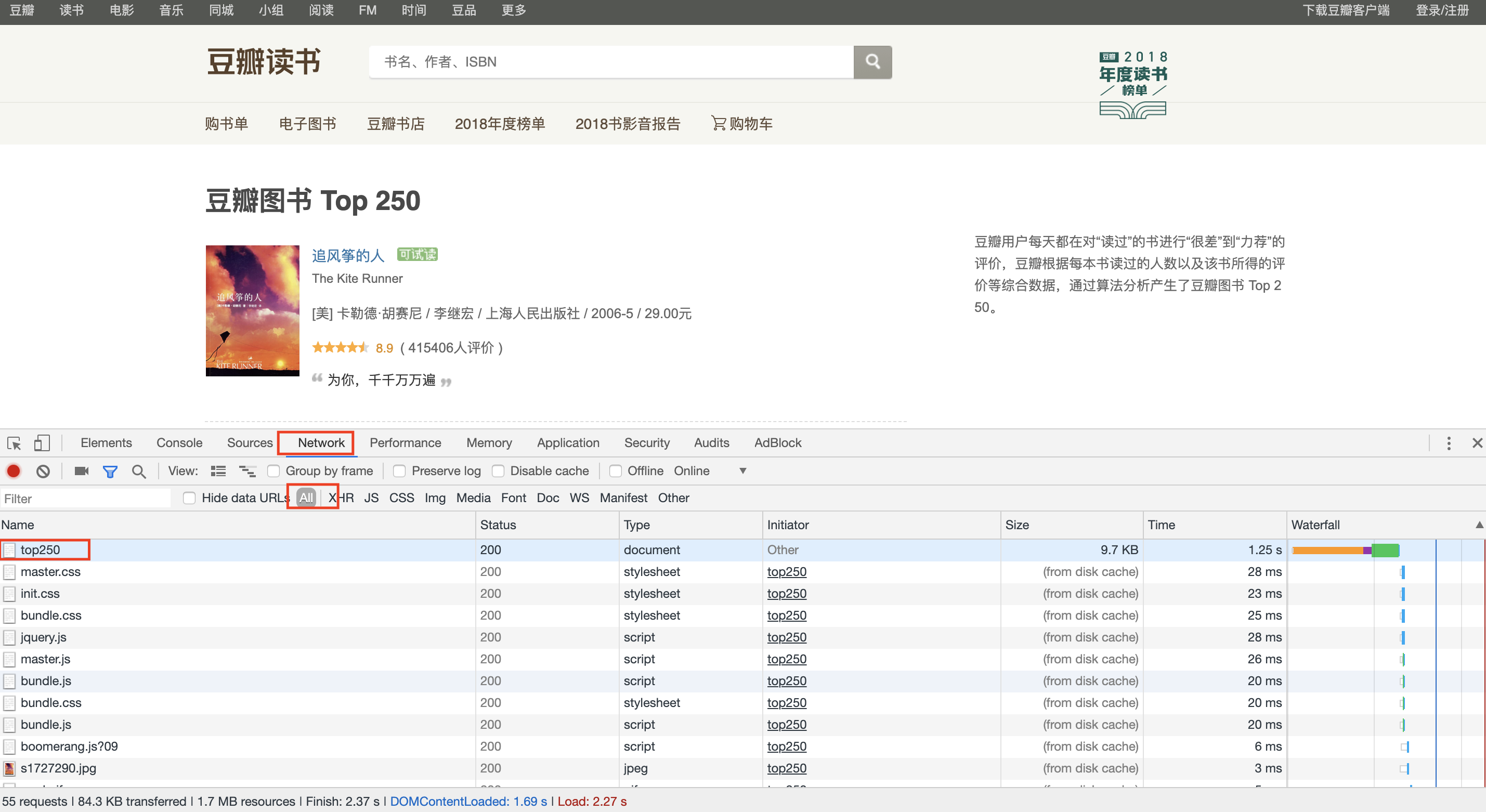
之后点击top250--->Response,如下图:
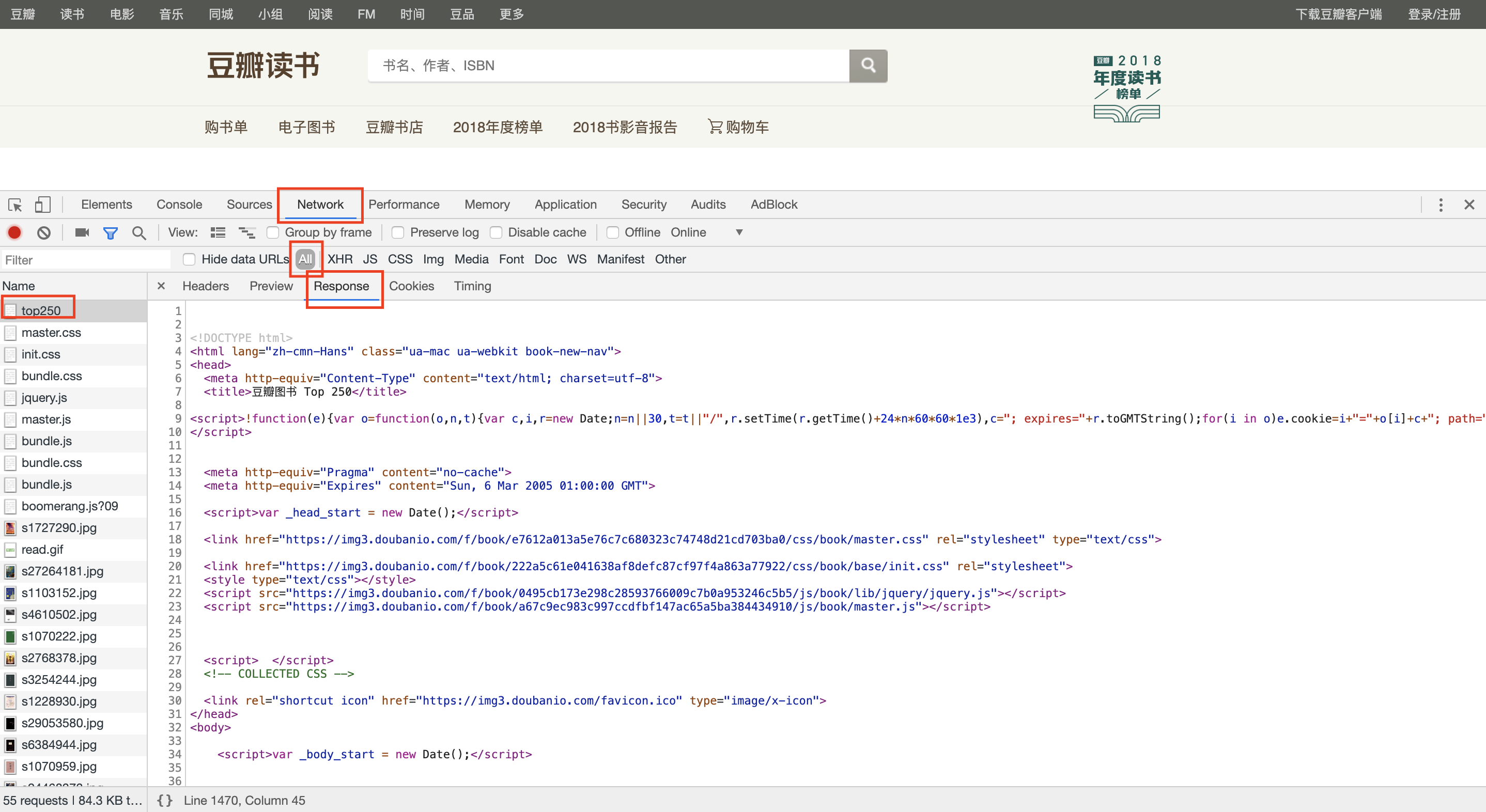
此时就会在右下方看到网页的源代码,分析源代码可知:
每一本书都是被「table标签,class=item」扩起来的,比如《追风筝的人》源代码在253-307行。
使用requests模块获取源代码,Python代码如下:
import requests
def parse_index(url): ''' 解析索引页面 返回图书所有信息 ''' try: response = requests.get(url) if response.status_code == 200: return response.text except Exception as e: print('error:', e)
『防抄袭:读者请忽略这段文字,文章作者是博客园的MinuteSheep』
3.3 解析图书详细信息
获取到页面源代码后,接下来要做的工作就是解析每一本图书的详细信息了。所以思路继续深入:
解析这一页--->得到这一页所有图书的信息--->解析一本图书--->将图书详细信息保存为字典格式
书名都是被「a标签」扩起来的,比如《追风筝的人》书名源代码在268-274行;
作者、出版社、出版日期、价格都是被「p标签,class=pl」扩起来的,比如《追风筝的人》这些信息源代码在285行;
评星都是被「span标签,class=rating_nums」扩起来的,比如《追风筝的人》评星源代码在292行;
简述信息都是被「span标签,class=inq」扩起来的,比如《追风筝的人》简述信息源代码在301行。
Python源代码如下:
from bs4 import BeautifulSoup
def parse(text): ''' 解析图书详细信息 ''' soup = BeautifulSoup(text.strip(), 'lxml') books = soup.select('.item') info = {} for book in books: info.clear() info['title'] = book.select('.pl2 a')[0].get_text( ).strip().replace(' ', '').replace(' ', '') info['author'] = book.select( '.pl')[0].get_text().strip().split('/')[0].strip() info['publishers'] = book.select( '.pl')[0].get_text().strip().split('/')[-3].strip() info['date'] = book.select( '.pl')[0].get_text().strip().split('/')[-2].strip() info['price'] = book.select( '.pl')[0].get_text().strip().split('/')[-1].strip() info['star'] = float(book.select('.rating_nums')[0].get_text()) info['summary'] = book.select('.inq')[0].get_text( ).strip() if book.select('.inq') else '' yield info
3.4 将信息保存在Mysql数据库
进入Mysql的交互环境,依次建立数据库、创建数据表:
create database douban;
use douban;
create table book_top250( -> id int not null primary key auto_increment, -> title char(100) not null unique key, -> author char(100) not null, -> publisher char(100), -> date char(100), -> price char(100) -> star float, -> summary char(100) ->);
之后使用Mysql官方推荐的连接库:mysql.connector
Python代码如下:
import mysql.connector
def open_mysql(): ''' 连接mysql ''' cnx = mysql.connector.connect(user='minutesheep', database='douban') cursor = cnx.cursor() return cnx, cursor def save_to_mysql(cnx, cursor, info): ''' 将数据写入mysql ''' add_book_top250 = ("INSERT IGNORE INTO book_top250 " "(title,author,publishers,date,price,star,summary) " "VALUES (%(title)s, %(author)s, %(publishers)s, %(date)s, %(price)s, %(star)s, %(summary)s)") cursor.execute(add_book_top250, info) cnx.commit() def close_mysql(cnx, cursor): ''' 关闭mysql ''' cursor.close() cnx.close()
到此为止,一本图书的信息就已经保存完毕了
3.5 遍历本页面所有图书
现在只需要将本页面的所有图书遍历一遍,就完成了一个页面的抓取
『防抄袭:读者请忽略这段文字,文章作者是博客园的MinuteSheep』
3.6 遍历所有页面
最后只需要将所有页面遍历就可以抓取到250本图书了。现在观察每一页的URL变化:
第一页:https://book.douban.com/top250 或 https://book.douban.com/top250?start=0
第二页:https://book.douban.com/top250?start=25
第三页:https://book.douban.com/top250?start=50
第十页(最后一页):https://book.douban.com/top250?start=225
通过观察可知,后一页的URL只需要将前一页的URL最后的数字加25
基于此,Python代码为:
def main(): base_url = 'https://book.douban.com/top250?start=' cnx, cursor = open_mysql() for page in range(0, 250, 25): index_url = base_url + str(page) text = parse_index(index_url) info = parse(text) for result in info: save_to_mysql(cnx, cursor, result) close_mysql(cnx, cursor)
四、项目流程图

五、项目源代码


import requests from bs4 import BeautifulSoup import mysql.connector def parse_index(url): ''' 解析索引页面 返回图书所有信息 ''' try: response = requests.get(url) if response.status_code == 200: return response.text except Exception as e: print('error:', e) def parse(text): ''' 解析图书详细信息 ''' soup = BeautifulSoup(text.strip(), 'lxml') books = soup.select('.item') info = {} for book in books: info.clear() info['title'] = book.select('.pl2 a')[0].get_text( ).strip().replace(' ', '').replace(' ', '') info['author'] = book.select( '.pl')[0].get_text().strip().split('/')[0].strip() info['publishers'] = book.select( '.pl')[0].get_text().strip().split('/')[-3].strip() info['date'] = book.select( '.pl')[0].get_text().strip().split('/')[-2].strip() info['price'] = book.select( '.pl')[0].get_text().strip().split('/')[-1].strip() info['star'] = float(book.select('.rating_nums')[0].get_text()) info['summary'] = book.select('.inq')[0].get_text( ).strip() if book.select('.inq') else '' yield info def open_mysql(): ''' 连接mysql ''' cnx = mysql.connector.connect(user='minutesheep', database='douban') cursor = cnx.cursor() return cnx, cursor def save_to_mysql(cnx, cursor, info): ''' 将数据写入mysql ''' add_book_top250 = ("INSERT IGNORE INTO book_top250 " "(title,author,publishers,date,price,star,summary) " "VALUES (%(title)s, %(author)s, %(publishers)s, %(date)s, %(price)s, %(star)s, %(summary)s)") cursor.execute(add_book_top250, info) cnx.commit() def close_mysql(cnx, cursor): ''' 关闭mysql ''' cursor.close() cnx.close() def main(): base_url = 'https://book.douban.com/top250?start=' cnx, cursor = open_mysql() for page in range(0, 250, 25): index_url = base_url + str(page) text = parse_index(index_url) info = parse(text) for result in info: save_to_mysql(cnx, cursor, result) close_mysql(cnx, cursor) if __name__ == '__main__': main()
整个项目地址:https://github.com/MinuteSheep/DoubanBookTop250
六、项目结果展示
Mysql部分数据如下图:

提醒:仅供学习使用,商用后果自负