-
Kafka核心技术与实战——09 | 生产者消息分区机制原理剖析
- 如何将这么大的数据量均匀地分配到 Kafka 的各个 Broker 上,就成为一个非常重要的问题
- 为什么分区?
- Kafka 有主题(Topic)的概念,它是承载真实数据的逻辑容器
- 而在主题之下还分为若干个分区,也就是说 Kafka 的消息组织方式实际上是三级结构:主题 - 分区 - 消息
- 主题下的每条消息只会保存在某一个分区中,而不会在多个分区中被保存多份
- 其实分区的作用就是提供负载均衡的能力
- 或者说对数据进行分区的主要原因,就是为了实现系统的高伸缩性(Scalability)
- 不同的分区能够被放置到不同节点的机器上,而数据的读写操作也都是针对分区这个粒度而进行的,这样每个节点的机器都能独立地执行各自分区的读写请求处理。
- 并且,我们还可以通过添加新的节点机器来增加整体系统的吞吐量
- 除了提供负载均衡这种最核心的功能之外,利用分区也可以实现其他一些业务级别的需求,比如实现业务级别的消息顺序的问题
- 都有哪些分区策略?
- 所谓分区策略是决定生产者将消息发送到哪个分区的算法。
- Kafka 为我们提供了默认的分区策略,同时它也支持你自定义分区策略
- 如果要自定义分区策略,你需要显式地配置生产者端的参数partitioner.class
- 在编写生产者程序时,你可以编写一个具体的类实现org.apache.kafka.clients.producer.Partitioner接口
- 这个接口也很简单,只定义了两个方法:partition()和close(),通常你只需要实现最重要的 partition 方法
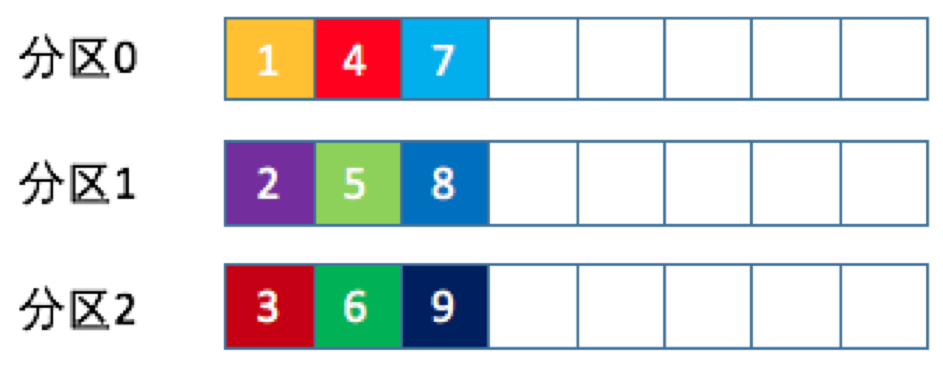
- 轮询策略
- 也称 Round-robin 策略,即顺序分配
- 这就是所谓的轮询策略。轮询策略是 Kafka Java 生产者 API 默认提供的分区策略。如果你未指定partitioner.class参数,那么你的生产者程序会按照轮询的方式在主题的所有分区间均匀地“码放”消息。
- 轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上,故默认情况下它是最合理的分区策略,也是我们最常用的分区策略之一
-
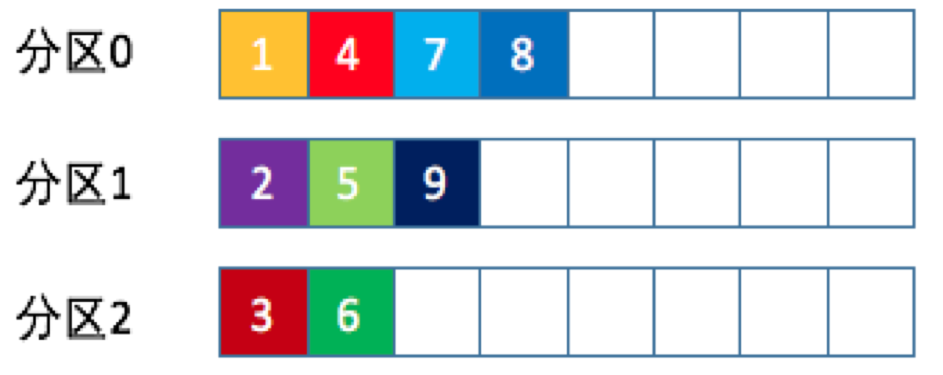
- 随机策略
- 也称 Randomness 策略。所谓随机就是我们随意地将消息放置到任意一个分区上
- 如果要实现随机策略版的 partition 方法,很简单,只需要两行代码即可:
- List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
- return ThreadLocalRandom.current().nextInt(partitions.size());
- 先计算出该主题总的分区数,然后随机地返回一个小于它的正整数。
- 本质上看随机策略也是力求将数据均匀地打散到各个分区,但从实际表现来看,它要逊于轮询策略,所以如果追求数据的均匀分布,还是使用轮询策略比较好。事实上,随机策略是老版本生产者使用的分区策略,在新版本中已经改为轮询了。
-
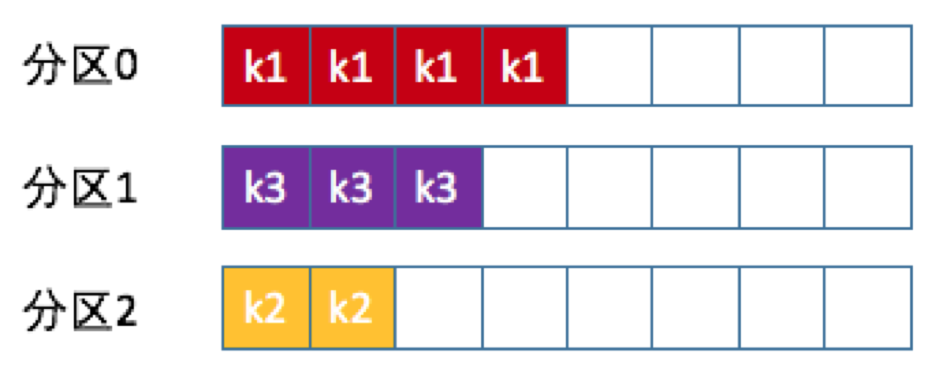
- 按消息键保序策略
- 也称 Key-ordering 策略
- Kafka 允许为每条消息定义消息键,简称为 Key。这个 Key 的作用非常大,它可以是一个有着明确业务含义的字符串,比如客户代码、部门编号或是业务 ID 等
- 实现这个策略的 partition 方法同样简单,只需要下面两行代码即可:
- List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
- return Math.abs(key.hashCode()) % partitions.size();
- 前面提到的 Kafka 默认分区策略实际上同时实现了两种策略:如果指定了 Key,那么默认实现按消息键保序策略;如果没有指定 Key,则使用轮询策略
- 有因果关系的消息
- 对此标志位设定专门的分区策略,保证同一标志位的所有消息都发送到同一分区
- 这样既可以保证分区内的消息顺序,也可以享受到多分区带来的性能红利
- 这种基于个别字段的分区策略本质上就是按消息键保序的思想,其实更加合适的做法是把标志位数据提取出来统一放到 Key 中,这样更加符合 Kafka 的设计思想
- 经过改造之后,这个企业的消息处理吞吐量一下提升了 40 多倍
- 从这个案例你也可以看到自定制分区策略的效果可见一斑
-
- 其他分区策略
- 基于地理位置的分区策略
- 根据 Broker 所在的 IP 地址实现定制化的分区策略
- 小结
- 切记分区是实现负载均衡以及高吞吐量的关键
- 故在生产者这一端就要仔细盘算合适的分区策略,避免造成消息数据的“倾斜”,使得某些分区成为性能瓶颈,这样极易引发下游数据消费的性能下降
- 发现kafka同一个topic是无法保证数据的顺序性的,但是同一个partition中的数据是有顺序的
- 要保证全局顺序。后来发现其实使用key+多分区也可以实现。反正保证同一批因果依赖的消息分到一个分区就可以
-
相关阅读:
element input number e
地图 scatter 自定义图片
地图某一个区域设置高亮
echarts 获取县级json
echarts map 阴影(重叠)
echarts 渐变色
echarts tooltip 超出处理
npm 下载 zip
axios post 下载文件
书签 css
-
原文地址:https://www.cnblogs.com/minimalist/p/12821602.html
Copyright © 2020-2023
润新知