简介
Zookeeper 是一个分布式应用程序的分布式开源协调服务。是Apache Hadoop 的一个子项目,主要用来解决分布式应用中经常遇到的一些数据管理问题,例如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
Zookeeper 工作原理
ZooKeeper 核心是原子广播,该机制保证了各个Server之间的同步,实现这个机制的协议叫做 Zab协议 ,Zab协议有两个模式,他们分别是 “恢复模式 & 广播模式”。
恢复模式
Zab协议会让ZK集群进入崩溃恢复模式的情况如下:
(1)当服务框架在启动过程中
(2)当Leader服务器出现网络中断,崩溃退出与重启等异常情况。
(3)当集群中已经不存在过半的服务器与Leader服务器保持正常通信。
在所有的follower服务器中选举一台为Leader,当leader被选举出来,集群中有多数服务与新的Leader完成状态同步之后就会退出恢复模式,用来保证至少有一半的follower能和Leader保持数据一致,当多数的follower集群与leader数据保持一致的时候,就会进入消息广播模式。
状态同步保证了 Leader 和 Server具有相同的系统状态,所谓的状态同步其实就是数据的同步。
一旦leader 已经和多数的follower进行状态同步之后,它就开始广播消息,并且进入广播模式,这时候当一个server加入Zookeeper 服务中,它会在恢复模式下启动,发现leader,并和leader进行状态同步,同步结束后,它也参与消息广播,Zookeeper服务一直维持在 Broadcast状态,直到leader崩溃了或者leader失去了大部分的followers支持。
广播模式
消息广播模式,Zab协议消息广播过程使用的是原子广播协议,类似于一个二阶段提交,但是又有点不一样,并不是所有的follower节点都需要返回ack才进行一致性事务完成,只需要多数以上即可。
针对每个客户端的事务请求,leader服务器会为其生成对应的事务Proposal,并将其发送给集群中其余所有的机器,然后再分别收集各自的选票,最后进行事务提交。
- leader 接收到消息请求后,将消息赋予一个全局唯一的 64 位自增的 Id,我们通常称之为zxid,通过 zxid 的大小比较即可实现有序的特性。
- leader 通过 队列 保证发送的顺序性,将带有zxid的消息作为一个提案(proposal)分发给所有follower
- 当follower 接收到proposal,先将proposal写到本地事务日志,写事务成功后再向Leader 回一个ACK确认
- 当leader 接收到多数的ack确认后,leader 会向所有follower 发送 commit 命令,同意会在本地执行该消息。
- 当follower 收到消息 commit 命令后,就会执行该消息。
消息广播模式流程示意图如下:
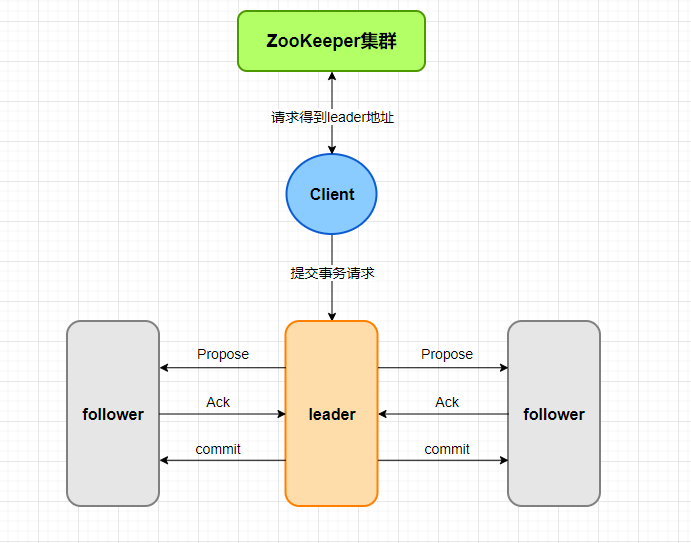
首先客户端会轮询Zookeeper集群中的各个节点,当轮询到一台是follower,如果是读的请求,follower会返回请求结果,如果是增删改操作,follower 会向leader生成事务请求,针对客户端的事务请求,针对客户端的事务请求,leader会为这个生成对应的事务Proposal,然后发送集群中所有follower服务器,然后分别在收集各自的选票,最后进行事务提交。
Zab协议的二阶段提交,在提交过程中移除了中断提交过程的操作,对于Zookeeper集群来说,超过半数反馈Ack确认就代表事务成功,这种方式无法完成所有节点事务一致性问题,所以Zab协议采用恢复模式来解决数据不一致的问题。
消息广播协议是基于具有FIFO特性的TCP协议进行通讯,因此可以保证消息广播过程中的接收和发送的顺序性。
事务ID
为了保证事务的顺序一致性,Zookeeper 采用了递增的事务ID号(zxid)来标识事务,所有的操作(proposal)都会在被提出时加上zxid,zxid是一个64位的数字,他高32位是epoch用来标识leader关系是否发生变化,每当有新的leader 被选举出来,都会有一个新的epoch,标识当前属于哪个leader的领导。
对于Zookeeper 来说,每次的变化都会产生一个唯一的事务id,zxid(ZooKeeper Transaction Id)通过zxid ,可以确定更新操作的先后顺序,如果说 zxid1 小于 zxid2,说明 zxid1比zxid先发生。
Zookeeper 模型
Zookeeper 是一个目录树结构,名称是由斜杠 (/) 分隔的一系列路径元素。ZooKeeper 命名空间中的每个节点都由路径标识。
ZooKeeper 层级树状结构

根节点 / 包含两个节点(/modele1 & /module2),其中节点 /module1 包含三个子节点(/module1/app1 & /module1/app2 & /module1/app3),在Zookeeper 中,节点以绝对路径表示,不存在相对路径,出了根节点以外,其他节点不能以 / 结尾。
特性
资源共享: 例如存储空间,计算能力,数据,和服务等等
扩展性: 从软件和硬件上增加系统的规模
并发性: 多个用户同时访问
性能: 确保当负载增加的时候,系统想要时间不会有影响
容错性: 尽管一些组件暂时不可用了,整个系统仍然是可用的
API抽象: 系统的独立组件对用户隐藏,仅仅暴露服务
Zookeeper的角色

- 领导者(leader) :负责进行投票的发起和决议,更新系统状态
- 学习者(learner) :包括跟随者(follower)和观察者(observer),follower用于接受客户端请求并想客户端返回结果,在选主过程中参与投票
- Observer :可以接受客户端连接,将写请求转发给leader,但observer不参加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度
- 客户端(client) :请求发起方
保证
顺序一致性: 客户端的更新将按发送顺序应用。
原子性: 更新成功或失败,没有部分结果。
统一视图: 无论服务器连接到哪个服务器,客户端都将看到相同的服务视图。即,即使客户端故障转移到具有相同会话的不同服务器,客户端也永远不会看到系统的旧视图。
可靠性: 一旦应用更新了,它将从那时起一直存在,直到客户端覆盖更新。
及时性: 系统的客户视图保证在特定时间范围内是最新的。
Znode 节点
Znode有两种类型: 持久节点和临时节点 ,Znode的类型在创建的之后就不能在进行修改了。
临时节点
临时节点在客户端会话结束的时候,Zookeeper 会将临时节点(znode)删除,并且临时节点不能有子节点。利用临时节点的特性,我们可以使用临时节点来进行集群管理以及发现服务的上下线等。
创建临时节点命令:create -e /module1/app1 app1
创建一个临时节点为 “/module1/app1” ,数据为 “app1”
持久节点
持久节点不依赖于客户端会话,只有当客户端明确要删除持久节点(znode)的时候才会被删除
创建临时节点命令:create /module1 module1
创建一个临时节点为 “/module1” ,数据为 “module1”
顺序节点
ZooKeeper 中还提供了一种顺序节点的类型,每次创建顺序节点时候,ZooKeeper 都会在路径后面自动添加10为的数据中,例如
0000000001 计数器会保证在同一父节点下唯一,创建节点的时候会添加顺序,常见分布式锁。
顺序节点只是节点的一种特性,也就说不管是 持久节点还是 临时节点 都可以设置为顺序节点,所以Znode类型可以理解为 4种类型:
- 持久节点
- 临时节点
- 持久顺序节点
- 临时顺序节点
创建顺序节点命令(加上 “-s”参数):create -s /module1/app app
我们会看到 Created /module1/app0000000001
意思是我们创建了一个持久顺序节点“/module1/app0000000001” 如果再执行上面命令 会生成节点 “/module1/app0000000002”,同理 如果我们 create -s后面添加 -e 参数,就表示我们创建了一个临时节点。
节点数据
- 创建节点的时候,我们可以指定节点中存储的数据,ZooKeeper可以保证读写都是原子操作,而且每次读写操作都是对数据的完整读取或者完成写入,不提供对数据的部分读取或者写入操作。
- ZooKeeper 虽然提供了节点存储数据的功能,但是我们并不能把它当成一个数据库,重点不要把Zookeeper 当成数据库用,因为Zookeeper 规定了节点的数据大小不能超过1M,所以我们不能在节点上存储过多的数据,尽可能保证小的数据量,因为数据过大,会导致ZK的性能下降。
- 如果确实需要存储大量的数据,一般可以在分布式数据库或者Redis保存这部分数据,然后在Znode中保留数据库中的索引。
Zookeeper单机模式安装
java 环境
配置JAVA环境,检验环境 java -version
下载安装Zookeeper
下载地址:https://zookeeper.apache.org/releases.html

下载解压Zookeeper
cd /usr/local/
get https://dlcdn.apache.org/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz
tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz
cd zookeeper-3.7.0/
重命名配置文件 zoo_sample.cfg
cp conf/zoo_sample.cfg conf/zoo.cfg
启动ZK
./bin/zkServer.sh start
连接ZK客户端
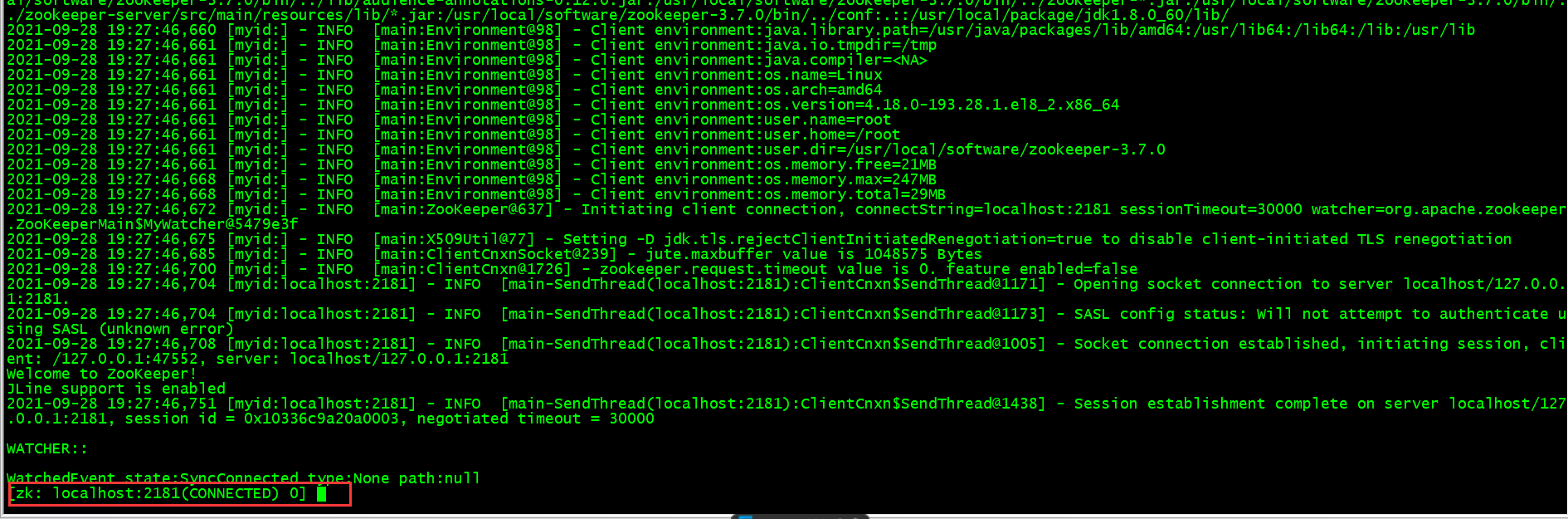
./bin/zkCli.sh
当我们看到下图的信息的时候,表示我们启动成功
Zookeeper命令
基本命令
- create : 在树中的某个位置创建一个节点
- delete : 删除一个节点存在:测试节点是否存在于某个位置
- get data : 从节点读取数据
- set data: 将数据写入节点
- get children : 检索节点的子节点列表
- sync : 等待数据被传播
操作Zookeeper
- 查看Zookeeper中包含的key
ls /
- 创建一个新的Znode
创建成功以后我们可以使用ls /查看我们创建的内容
create /zkMxn muxiaonong
ls /
[zkMxn, zookeeper]
get命令获取创建Znode的内容
get /zkMxn
- set 命令来对 zk 所关联的字符串进行设置
set /zkMxn mxn666
- 删除Znode
delete /zkMxn
Java Api操作 ZK
1. 导入Jar包
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.6.3</version>
</dependency>
<!--junit单元测试-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>runtime</scope>
</dependency>
2. API操作Zookeeper
创建Zookeeper对象
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher) throws IOException {
this(connectString, sessionTimeout, watcher, false);
}
- connectString: 连接的地址,包括主机名和端口号,多个的话用逗号隔开
- sessionTimeout: 等待客户端通信的最长时间,客户端如果超过这个时间没有和服务端进行通信,那么就认为该客户端已经终止,一般设置值为 5-10秒,单位为毫秒
- watcher: 监听器,用于接收会话事件的接口,需要自己定义,实现process()方法
连接Zookeeper
Zookeeper zkClient = "";
String connectStr = "192.168.2.1:2181";
zkClient = new ZooKeeper(connectStr, 5000, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) { }
});
创建节点
public String create(String path, byte[] data, List<ACL> acl, CreateMode createMode) throws KeeperException, InterruptedException {}
- path: 节点路径
- data: 节点数据
- acl: 节点权限,例如:
ZooDefs.Ids.OPEN_ACL_UNSAFE
OPEN_ACL_UNSAFE:完全开发,采用world验证模式,由于每个ZK连接都有world验证模式,所以当我们节点设置了该参数时,对所有连接开放
CREATOR_ALL_ACL: 创建该Znode连接的拥有所有权限,这里采用的是auth验证模式,用sessionID做验证,如果设置了该参数,只有创建改Znode节点的连接才能对这个Znode进行任何操作
READ_ACL_UNSAFE:所有的客户端都可读,这里采用world验证模式,和第一条同理,所有连接都可以读取该znode
- createMode: 节点类型,例如:
CreateMode.PERSISTENT
PERSISTENT:持久节点
PERSISTENT_SEQUENTIAL:持久有序节点
EPHEMERAL:短暂节点
EPHEMERAL_SEQUENTIAL:短暂有序节点
完整APIDemo:
import lombok.extern.slf4j.Slf4j;
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.concurrent.CountDownLatch;
/** @Author mxn
* @Description //TODO ZooKeeper Java API测试
* @Date 10:22 2021/9/29
* @Param
* @return
**/
@Slf4j
public class ZookeeperTest {
// IP 和端口
private final static String ipAddress = "192.168.2.123:2181";
public static void main(String[] args) {
ZookeeperTest test = new ZookeeperTest();
String key = "/zkMxn";
String value = "wo is muxiaonong";
//创建Znode
test.add(key,value);
// 获取节点数据
// test.get(key);
//修改节点数据
// test.modify(key,"wo is zhuzhuxia");
//删除节点
// test.delete(key);
}
/**
* @return
* @Author mxn
* @Description //TODO 获取ZooKeeper连接
* @Date 10:22 2021/9/29
* @Param
**/
public static ZooKeeper getConntection() {
ZooKeeper zooKeeper = null;
try {
final CountDownLatch countDownLatch = new CountDownLatch(1);
//watch机制(回调),监听是否连接成功
zooKeeper = new ZooKeeper(ipAddress, 5000, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
if (Event.KeeperState.SyncConnected == watchedEvent.getState()) {
//如果受收到了服务端的响应事件,连接成功
countDownLatch.countDown();
}
}
});
countDownLatch.await();
log.info("zookeeper状态:{}",zooKeeper.getState());//CONNECTED
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
return zooKeeper;
}
/** @Author lyy
* @Description //TODO 关闭ZooKeeper连接
* @Date 14:57 2021/9/29
* @Param
* @return
**/
public static void closeConnection(ZooKeeper zooKeeper) {
try {
// zooKeeper.close();
} catch (Exception e) {
e.printStackTrace();
}
}
/** @Author lyy
* @Description //TODO 添加节点
* @Date 13:36 2021/9/29
* @Param
* @return
**/
public void add(String key ,String value) {
ZooKeeper zooKeeper = ZookeeperTest.getConntection();
try {
//参数类型
//1.key
//2.value
//3.对应的ACL,当前节点的权限控制
//4.设置当前节点类型
zooKeeper.create(key, value.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
ZookeeperTest.closeConnection(zooKeeper);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/** @Author lyy
* @Description //TODO 获取节点信息
* @Date 14:57 2021/9/29
* @Param
* @return
**/
public void get(String key) {
ZooKeeper zooKeeper = ZookeeperTest.getConntection();
Stat stat = new Stat();
String data = null;
try {
byte[] bytes = zooKeeper.getData(key, null, stat);
data = new String(bytes, "gbk");
log.info("当前节点信息:{}",data);
ZookeeperTest.closeConnection(zooKeeper);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
/** @Author lyy
* @Description //TODO 修改节点信息
* @Date 14:57 2021/9/29
* @Param
* @return
**/
public void modify(String key,String newValue) {
ZooKeeper zooKeeper = ZookeeperTest.getConntection();
Stat stat = new Stat();
//version乐观锁概念,此处需要获取version信息,则需要先get拿到节点信息
try {
//获取节点(修改需要version信息)
zooKeeper.getData(key, null, stat);
//再修改
zooKeeper.setData(key, newValue.getBytes(), stat.getVersion());
ZookeeperTest.closeConnection(zooKeeper);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/** @Author lyy
* @Description //TODO 删除节点
* @Date 14:57 2021/9/29
* @Param
* @return
**/
public void delete(String key) {
ZooKeeper zooKeeper = ZookeeperTest.getConntection();
Stat stat = new Stat();
try {
//获取节点(删除需要version信息)
zooKeeper.getData(key, null, stat);
//删除节点
zooKeeper.delete(key, stat.getVersion());
ZookeeperTest.closeConnection(zooKeeper);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
总结
到这里我们对Zookeeper 大概有个入门级的了解了,不过Zookeeper远远比我们这里讲述的功能多,如何用Zookeeper实现集群管理、分布式锁,队列等等,小农会在后面的文章中进行讲解,关注我,后续精彩内容第一时间推送。
我是牧小农,怕什么真理无穷,进一步有进一步的欢喜,大家加油!!!