2.1 Introduction
MapReduce framework sorts input to reducers by key, but values of reducers are arbitrarily ordered. This means that if all mappers generated the following (key-value) pairs for key = K: (K, V1), (K, V2), ..., (K, Vn). Then all these values {V1, V2, ..., Vn} will be processed by a single reducer (for key = K), but there is no order (ascending or descending) between Vi‘s. Secondary sorting is a design pattern which will put some kind or ordering (such as "ascending sort" or "descending sort") among the values Vi‘s. How do we accomplish this? That is we want to have some order between the reducer values:
S1<=S2<=...<=Sn
or
S1>=S2>=...>=Sn
where Si∈{V1, V2, ..., Vn} for i = {1, 2, ..., n}. Note that each Vi might be a simple data type such as String or Integer or a tuple (more than a single value – a composite object).
仍然在说“二次排序”问题,简单来说就是字面意思的排两次序嘛。在 MapReduce 框架里,mappers 输出的键值对会按照键排序,然后作为 reducers 的输入。于是,具有同一键值的键值对会被送到同一个 reducer 分析,但是键值对里的值则是随机的。然后,我们希望这些值之间也能有一定顺序,即通过所谓“二次排序”来实现。至于为什么这么希望,倒是没有详细说,不过想想第一章那个从气象数据找年最高温的例子,mappers 从数据中提取出键值对(年份,气温),要是值(气温)再按序拍好传给 reducer ,那问题好像会简单点。所以,大概是某些时候这样方式会更优吧。还有要明确的是键值对里的类型可以是复合的,之前例子就有 value 是 tuple(time, value)的情况。
There are two ways to have sorted values for reducer values:
- Solution-1: Buffer reducer values in memory, then sort. If the number of reducer values are small enough, so they can fit in memory (perreducer), then this solution will work. But if the the number of reducer values are high, then these values might not fit in memory (not a preferable solution). Implementation of this solution is trivial and will not be discussed in this chapter.
- Solution-2: Use “secondary sorting” design pattern of MapReduce framework and reducer values will arrive sorted to a reducer (no need to sort values in memory). This technique uses the shuffle and sort technique of MapReduce framework to perform sorting of reducer
values. This technique is preferable to Solution-1 because you do not depend on the memory for sorting (and if you have too many values, then Solution1 might not be a viable option). The rest of this chapter will focus on presenting Solution-2. We present
implementation of Solution-2 in Hadoop by using- Old Hadoop API
(usingorg.apache.hadoop.mapred.JobConfandorg.apache.hadoop.mapred.*);
I intentionally included Hadoop‘s old API if in case you are using an old API and have not migrated to new Hadoop API.- New Hadoop API (using
org.apache.hadoop.mapreduce.Joband
org.apache.hadoop.mapreduce.lib.*)
同样是上一章说到的两个解决办法,这一章打算更加具体地讲如何用 Hadoop 实现第二种方法,还很贴心的新旧 API 都讲(我感觉就是...跳过)。第二种方法的原理细节,像“This technique uses the shuffle and sort technique of MapReduce framework to perform sorting of reducer values.”仍然不是很懂。这个方法不用 reducer 来二排,传到 reducer 的键值对最后组起来就是二排好的,不明觉厉。
2.2 Secondary Sorting Technique
Let’s have the following values for key = K:
(K, V1), (K, V2),..., (K, Vn).
and further assume that each Vi is a tuple of m attributes as:
(ai1, ai2,..., aim).
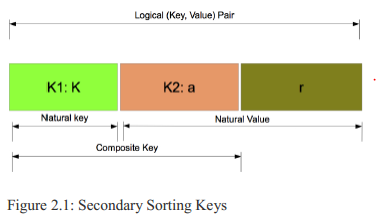
where we want to sort reducer’s tuple values by ai1. We will denote (ai2, ..., aim) (the remaining attributes) by r. Therefore, we can express reducer values as:
(K, (a1, r1)), (K, (a2, r2)),..., (K, (an, rn)).
To sort the reducer values by ai, we create a composite key: (K, ai). Our new mappers will emit the following (key, value) pairs for key = K.
| Key | Value |
|---|---|
| (K, a1) | (a1, r1) |
| (K, a2) | (a2, r2) |
| ... | ... |
| (K, an) | (an, rn) |
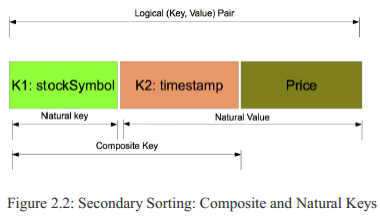
So the "composite key" is (K, ai) and the "natural key" is K. Defining the composite key (by adding the attribute ai to the "natural key" where the values will be sorted on) enables us to sort the reducer values by the MapReduce framework, but when we want to partition keys, we will partition it by the "natural key"
(as K). Below "composite key" and "natural key" are presented visually in 2.2.
把你二排需要用到的值和“natural key”一起定义成“compisite key”, MapReduce 框架就可以实现二排。好像又很简单的样子,不过那么多 mapper ,最后结果是不是也要处理。不过实际上,你也需要写不少东西(如下)告诉框架怎么来排。
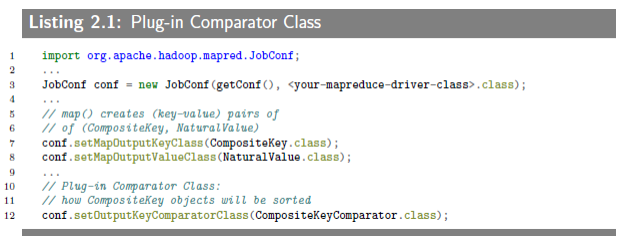
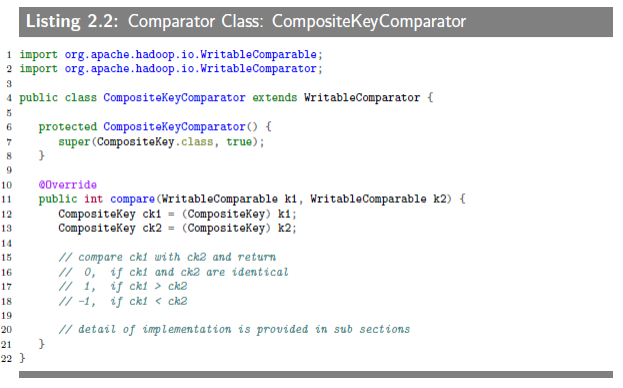
Since we defined a "composite key" (composed of "natural key" (as K) and an attribute (as ai) where the reducer values will be sorted on), we have to tell the MapReduce framework how to sort the keys by usinga "composite key" (comprised of two fields: K and ai): for this we need to define a plug-in sort class, CompositeKeyComparator, which will be sorting the Composite Keys. This is how you plug-in this comparator class to a MapReduce framework:
The CompositeKeyComparator class is telling to the MapReduce framework how to sort the composite keys (comprised of two fields: K and ai). The implementation is provided below, which compares two WriteableComparables objects (representing a CompositeKey object).
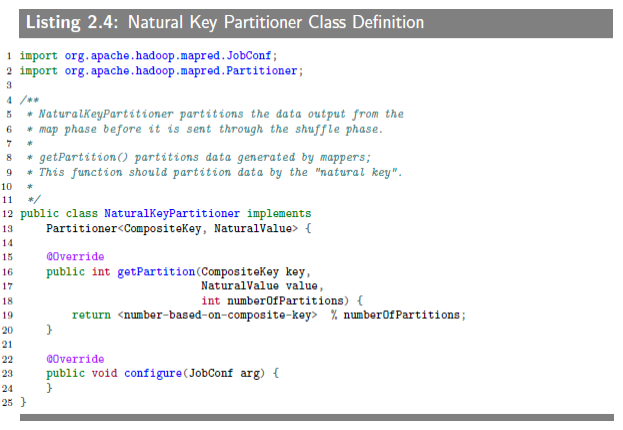
The next piece of plug-in class is a "natural key partitioner" class (let’s call this NaturalKeyPartitioner class), which will implement the org.apache.hadoop.mapred.Partitio interface. This is how we plug-in the class to the MapReduce framework:
Next, we define the Natural Key Partitioner class:
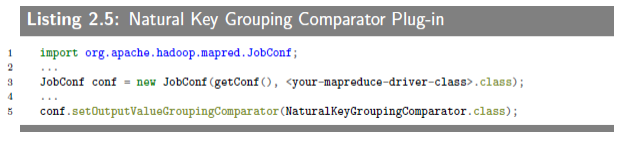
The last piece to plugin is NaturalKeyGroupingComparator, which considers the natural key. This class just compares two natural keys. This is how you plug-in the class to the MapReduce framework:
This is how you define the NaturalKeyGroupingComparator class:

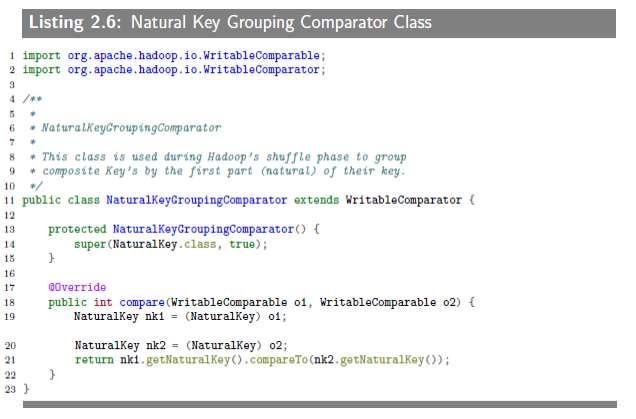
往框架里写了不少东西,有CompositeKeyComparator来告诉框架怎么对自己定义的“composite key”进行排序,这个可以理解(当然不是代码层面上的)。不过还有NaturalKeyPartitioner用来提取“natural key”以及NaturalKeyGroupingComparator用来按“natural key”进行分组。所以是你给框架新写了个类来告诉它怎么按“composite key”排序,原来的按键排序输出给覆盖了,还要自己把“natural key”提取出来再分个组,然后就可以实现“二排”(纯属个人猜测)。
2.3 Complete Example of Secondary Sorting
2.3.1 Problem Statement
Consider the following data:
Stock-Symbol Date Closed-Price
and assume that we want to generate the following output data per stock-symbol:
Stock-Symbol: (Date1, Price1)(Date2, Price2)...(Daten, Pricen)
where
Date1<=Date2<=...<=Daten.
That is we want the reducer values to be sorted by the date of closed price. This can be accomplished by "secondary sorting".
又举了一个完整的例子来说明二排,想要的输出是数据按 “Stock-Symbol” 分类,并且每类元素按 “Date” 升序。
2.3.2 Input Format
We assume that input data is in CSV (Comma-separated Value) format:
Stock-Symbol,Date,Colsed-Price
for example:
ILMN,2013-12-05,97.65
GOOG,2013-12-09,1078.14
IBM,2013-12-09,177.46
ILMN,2013-12-09,101.33
ILMN,2013-12-06,99.25
GOOG,2013-12-06,1069.87
IBM,2013-12-06,177.67
GOOG,2013-12-05,1057.34
输入的格式是 CSV (用逗号分隔的值)。
2.3.3 Output Format
We want our output to be sorted by "date of closed price": for our sample input, our desired output is listed below:
ILMN: (2013-12-05,97.65)(2013-12-06,99.25)(2013-12-09,101.33)
GOOG: (2013-12-05,1057.34)(2013-12-06,1069.87)(2013-12-09,1078.14)
IBM: (2013-12-06,177.67)(2013-12-09,177.46)
2.3.4 Composite Key
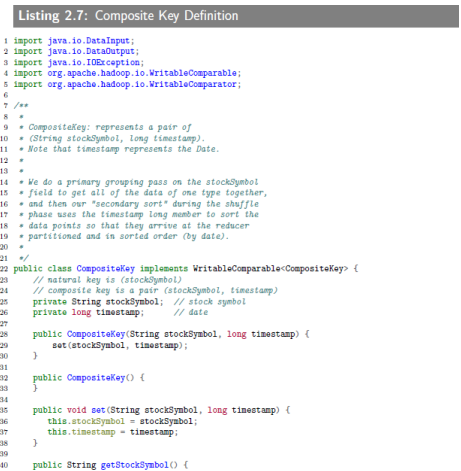
2.3.4.1 Composite Key Definition
The Composite Key Definition is implemented as a CompositeKey class, which implements the
WritableComparable<CompositeKey>interface.
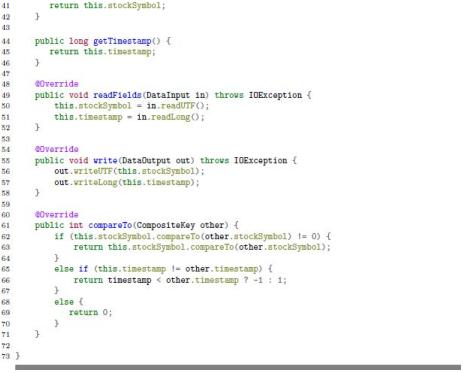
2.3.4.1 Composite Key Comparator Definiton
Composite Key Comparator Definition is implemented by the CompositeKeyComparator class which compares two CompositeKey objects by implementaing the compare() method. The compare() method returns 0 if they are identical, returns -1 if the first composite key is smaller than the second one, otherwise returns +1.
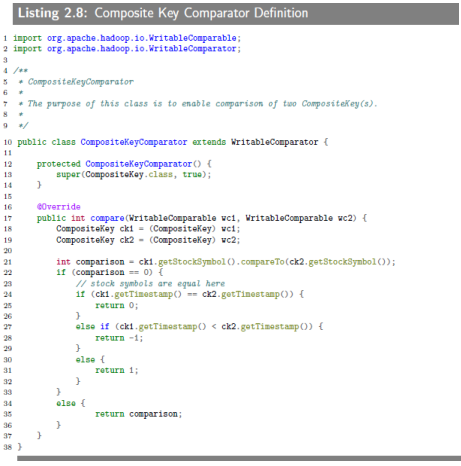
2.3.5 Sample Run
2.3.5.1 Implementation Classes using Old Hadoop API
跳过实际运行的“2.3.5.2 Input,2.3.5.3 Running MapReduce Job以及2.3.5.4 Output”。
2.4 Secondary Sorting using New Hadoop API
2.4.0.5 Implementation Classes using New API
WritableComparable(s) can be compared to each other, typically via Comparator(s). Any type which is to be used as a key in the Hadoop Map-Reduce framework should implement this interface.
同样跳过“2.4.0.6 Input,2.4.0.7 Running MapReduce Job以及2.4.0.8 Output of MapRedue Job”。
第二章就像名字一样,又举了个更加详细的例子来说明解决“二次排序”问题的第二个方法怎么用 Hadoop 来实现,大概是又加深了一点对其原理的理解,这也是我的主要目的。至于其具体的实现,代码和新旧 API 是蛮贴蛮看,实际还差的远,自己是打不出来的。书上的实际运行,因为觉得对现在没什么必要,也就没有贴。不过稍微看了下,大概就是直接运行run.sh这个脚本,然后检查输入输出文件用的是cat,只有执行时的 Log 比较迷。问题不大,继续往下。