Resilient Distributed Datasets
Resilient Distributed Datasets (RDD) is a fundamental data structure of Spark. It is an immutable distributed collection of objects. Each dataset in RDD is divided into logical partitions, which may be computed on different nodes of the cluster. RDDs can contain any type of Python, Java, or Scala objects, including user-defined classes.
Formally, an RDD is a read-only, partitioned collection of records. RDDs can be created through deterministic operations on either data on stable storage or other RDDs. RDD is a fault-tolerant collection of elements that can be operated on in parallel.
There are two ways to create RDDs − parallelizing an existing collection in your driver program, or referencing a dataset in an external storage system, such as a shared file system, HDFS, HBase, or any data source offering a Hadoop Input Format.
Spark makes use of the concept of RDD to achieve faster and efficient MapReduce operations. Let us first discuss how MapReduce operations take place and why they are not so efficient.
Spark 拥有多种语言的函数式编程 API,提供了除 map 和 reduce 之外更多的运算符,这些操作是通过一个称作弹性分布式数据集(resilient distributed datasets, RDDs)的分布式数据框架进行的。
本质上,RDD 是种编程抽象,代表可以跨机器进行分割的只读对象集合。RDD 可以从一个继承结构(lineage)重建(因此可以容错),通过并行操作访问,可以读写 HDFS 这样的分布式存储,更重要的是,可以缓存到 worker 节点的内存中进行立即重用。由于 RDD 可以被缓存在内存中,Spark 对迭代应用特别有效,因为这些应用中,数据是在整个算法运算过程中都可以被重用。大多数机器学习和最优化算法都是迭代的,使得 Spark 对数据科学来说是个非常有效的工具。
RDD 是只读的、分区记录的集合。RDD 只能基于在稳定物理存储中的数据集和其他已有的RDD 上执行确定性操作来创建。这些确定性操作称之为转换,如 map、filter、groupBy、join(转换不是程开发人员在 RDD 上执行的操作)。在 Spark 中,RDD 被表示为对象,通过这些对象上的方法(或函数)调用转换。定义 RDD 之后,程序员就可以在动作中使用 RDD 了。动作是向应用程序返回值,或向存储系统导出数据的那些操作,例如,count(返回 RDD 中的元素个数),collect(返回元素本身),save(将 RDD 输出到存储系统)。在 Spark 中,只有在动作第一次使用 RDD 时,才会计算 RDD (即延迟计算)。可见转换是延迟操作,用于定义新的 RDD ;而动作启动计算操作,并向用户程序返回值或向外部存储写数据。
Data Sharing is Slow in MapReduce
MapReduce is widely adopted for processing and generating large datasets with a parallel, distributed algorithm on a cluster. It allows users to write parallel computations, using a set of high-level operators, without having to worry about work distribution and fault tolerance.
Unfortunately, in most current frameworks, the only way to reuse data between computations (Ex − between two MapReduce jobs) is to write it to an external stable storage system (Ex − HDFS). Although this framework provides numerous abstractions for accessing a cluster’s computational resources, users still want more.
Both Iterative and Interactive applications require faster data sharing across parallel jobs. Data sharing is slow in MapReduce due to replication, serialization, and disk IO. Regarding storage system, most of the Hadoop applications, they spend more than 90% of the time doing HDFS read-write operations.
Iterative Operations on MapReduce
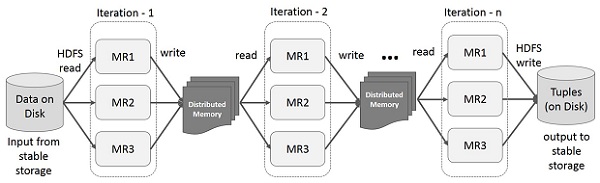
Reuse intermediate results across multiple computations in multi-stage applications. The following illustration explains how the current framework works, while doing the iterative operations on MapReduce. This incurs substantial overheads due to data replication, disk I/O, and serialization, which makes the system slow.
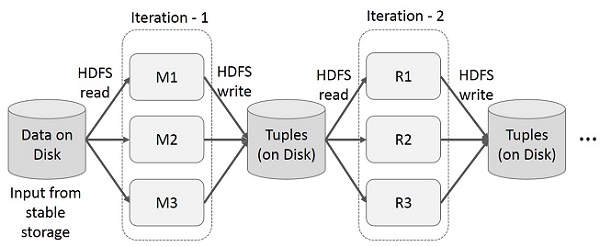
Interactive Operations on MapReduce
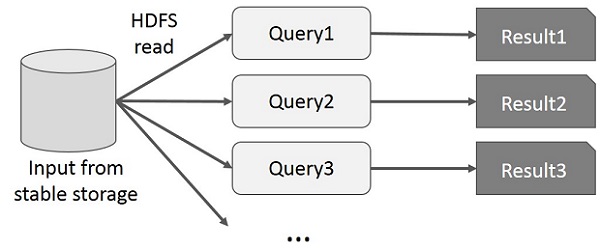
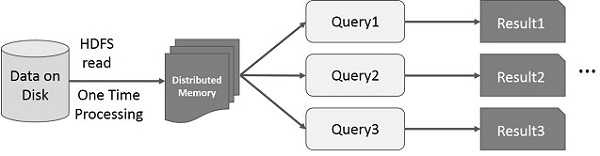
User runs ad-hoc queries on the same subset of data. Each query will do the disk I/O on the stable storage, which can dominates application execution time.
The following illustration explains how the current framework works while doing the interactive queries on MapReduce.
Data Sharing using Spark RDD
Data sharing is slow in MapReduce due to replication, serialization, and disk IO. Most of the Hadoop applications, they spend more than 90% of the time doing HDFS read-write operations.
Recognizing this problem, researchers developed a specialized framework called Apache Spark. The key idea of spark is Resilient Distributed Datasets (RDD); it supports in-memory processing computation. This means, it stores the state of memory as an object across the jobs and the object is sharable between those jobs. Data sharing in memory is 10 to 100 times faster than network and Disk.
Let us now try to find out how iterative and interactive operations take place in Spark RDD.
Iterative Operations on Spark RDD
The illustration given below shows the iterative operations on Spark RDD. It will store intermediate results in a distributed memory instead of Stable storage (Disk) and make the system faster.
Note − If the Distributed memory (RAM) is not sufficient to store intermediate results (State of the JOB), then it will store those results on the disk.
Interactive Operations on Spark RDD
This illustration shows interactive operations on Spark RDD. If different queries are run on the same set of data repeatedly, this particular data can be kept in memory for better execution times.
By default, each transformed RDD may be recomputed each time you run an action on it. However, you may also persist an RDD in memory, in which case Spark will keep the elements around on the cluster for much faster access, the next time you query it. There is also support for persisting RDDs on disk, or replicated across multiple nodes.
主要意思就是说,Spark 可以把中间计算的结果先缓存起来,而不是像 Hadoop 那样每次都写到磁盘上,像迭代算法和交互式分析这样的问题,用 Spark 处理就会快很多。
Spark API
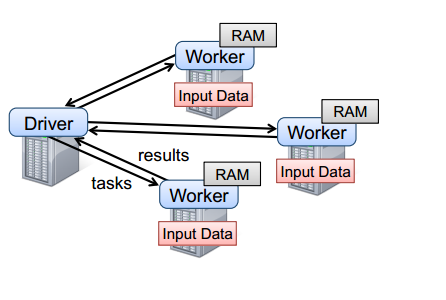
要使用 Spark,开发者需要编写一个 driver 程序,连接到集群以运行 Worker,如下图所示。Driver 定义了一个或多个 RDD,并调用 RDD 上的动作。Worker 是长时间运行的进程,将 RDD 分区以 Java 对象的形式缓存在内存中。
Spark 运行时。用户的 driver 程序启动多个 worker,worker 从分布式文件系统中读取数据块,并将计算后的 RDD 分区缓存在内存中。
具体的 API 可以查看最后一个参考资料,不过也没解释详细作用。
RDD 的描述及作业调度
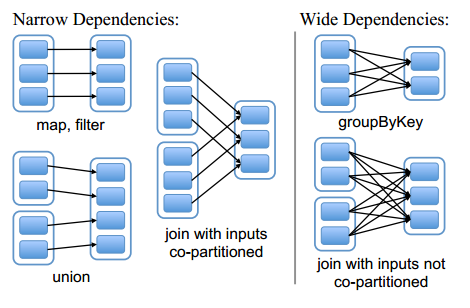
RDD 之间的依赖关系可以分为两类,即:(1)窄依赖(narrow dependencies):子 RDD 的每个分区依赖于常数个父分区(即与数据规模无关);(2)宽依赖(wide dependencies):子 RDD 的每个分区依赖于所有父RDD分区。例如,map 产生窄依赖,而 join 则是宽依赖(除非父 RDD 被哈希分区)。
窄依赖允许在一个集群节点上以流水线的方式(pipeline)计算所有父分区。例如,逐个元素地执行 map、然后 filter 操作;而宽依赖则需要首先计算好所有父分区数据,然后在节点之间进行 Shuffle,这与 MapReduce 类似。第二,窄依赖能够更有效地进行失效节点的恢复,即只需重新计算丢失 RDD 分区的父分区,而且不同节点之间可以并行计算;而对于一个宽依赖关系的 Lineage 图,单个节点失效可能导致这个 RDD 的所有祖先丢失部分分区,因而需要整体重新计算。
Spark任务调度器
调度器根据 RDD 的结构信息为每个动作确定有效的执行计划。调度器的接口是 runJob 函数,参数为 RDD 及其分区集,和一个 RDD 分区上的函数。该接口足以表示 Spark 中的所有动作(即count、collect、save等)。
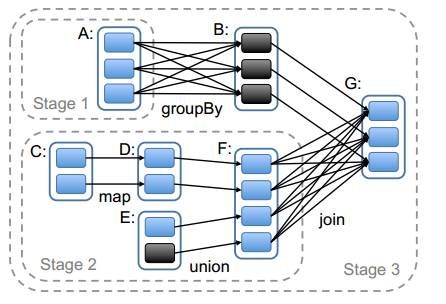
调度器根据目标 RDD 的 Lineage 图创建一个由 stage 构成的无回路有向图(DAG)。每个 stage 内部尽可能多地包含一组具有窄依赖关系的转换,并将它们流水线并行化(pipeline)。stage 的边界有两种情况:一是宽依赖上的 Shuffle 操作;二是已缓存分区,它可以缩短父 RDD 的计算过程。
图中实线方框表示 RDD,实心矩形表示分区(黑色表示该分区被缓存)。要在 RDD G上执行一个动作,调度器根据宽依赖创建一组 stage,并在每个 stage 内部将具有窄依赖的转换流水线化(pipeline)。 本例不用再执行 stage 1,因为 B 已经存在于缓存中了,所以只需要运行2和3。