看了一点《数据算法:Hadoop/Spark大数据处理技巧》,觉得有必要了解一下 Spark 。
以上。
Spark was introduced by Apache Software Foundation for speeding up the Hadoop computational computing software process.
As against a common belief, Spark is not a modified version of Hadoop and is not, really, dependent on Hadoop because it has its own cluster management. Hadoop is just one of the ways to implement Spark.
Spark uses Hadoop in two ways – one is storage and second is processing. Since Spark has its own cluster management computation, it uses Hadoop for storage purpose only.
Hadoop 是对大数据集进行分布式计算的标准工具,允许使用相对便宜的商业硬件集群进行超级计算机级别的计算。不过,Hadoop 也存在很多已知限制。比如说 MapReduce 作业的 I/O 成本很高,导致交互分析和迭代算法(iterative algorithms)开销很大。但是事实上,几乎所有的最优化和机器学习都是迭代的。为了解决这些问题,Hadoop 一直在向一种更为通用的资源管理框架转变,即 YARN(Yet Another Resource Negotiator, 又一个资源协调者)。而 Spark 是第一个脱胎于该转变的快速、通用分布式计算范式,拥有自己的集群管理方式,并不是 Hadoop 的一个新版本。Hadoop 只是 Spark 实现方式的一种,而且只是用来存储数据。
Apache Spark
Apache Spark is a lightning-fast cluster computing technology, designed for fast computation. It is based on Hadoop MapReduce and it extends the MapReduce model to efficiently use it for more types of computations, which includes interactive queries and stream processing. The main feature of Spark is its in-memory cluster computing that increases the processing speed of an application.
Spark is designed to cover a wide range of workloads such as batch applications, iterative algorithms, interactive queries and streaming. Apart from supporting all these workload in a respective system, it reduces the management burden of maintaining separate tools.
Spark 是个轻量快速的集群计算技术,设计成能进行快速的计算。使用函数式编程范式扩展了 MapReduce 模型以支持更多计算类型,可以涵盖广泛的工作流,这些工作流之前被实现为 Hadoop 之上的特殊系统。Spark 使用内存缓存来提升性能,因此进行交互式分析也足够快速。缓存同时提升了迭代算法的性能,这使得 Spark 非常适合数据理论任务,特别是机器学习。
Evolution of Apache Spark
Spark is one of Hadoop’s sub project developed in 2009 in UC Berkeley’s AMPLab by Matei Zaharia. It was Open Sourced in 2010 under a BSD license. It was donated to Apache software foundation in 2013, and now Apache Spark has become a top level Apache project from Feb-2014.
Spark 由 UC(University of California) Berkeley AMP lab (加州大学伯克利分校的AMP实验室) 开发。
Features of Apache Spark
Apache Spark has following features.
- Speed − Spark helps to run an application in Hadoop cluster, up to 100 times faster in memory, and 10 times faster when running on disk. This is possible by reducing number of read/write operations to disk. It stores the intermediate processing data in memory.
- Supports multiple languages − Spark provides built-in APIs in Java, Scala, or Python. Therefore, you can write applications in different languages. Spark comes up with 80 high-level operators for interactive querying.
- Advanced Analytics − Spark not only supports ‘Map’ and ‘reduce’. It also supports SQL queries, Streaming data, Machine learning (ML), and Graph algorithms.
Spark Built on Hadoop
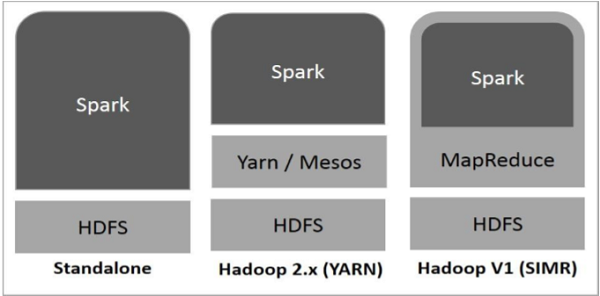
The following diagram shows three ways of how Spark can be built with Hadoop components.
There are three ways of Spark deployment as explained below.
- Standalone − Spark Standalone deployment means Spark occupies the place on top of HDFS(Hadoop Distributed File System) and space is allocated for HDFS, explicitly. Here, Spark and MapReduce will run side by side to cover all spark jobs on cluster.
- Hadoop Yarn − Hadoop Yarn deployment means, simply, spark runs on Yarn without any pre-installation or root access required. It helps to integrate Spark into Hadoop ecosystem or Hadoop stack. It allows other components to run on top of stack.
- Spark in MapReduce (SIMR) − Spark in MapReduce is used to launch spark job in addition to standalone deployment. With SIMR, user can start Spark and uses its shell without any administrative access.
Components of Spark
The following illustration depicts the different components of Spark.
Apache Spark Core
Spark Core is the underlying general execution engine for spark platform that all other functionality is built upon. It provides In-Memory computing and referencing datasets in external storage systems.
包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。
Spark SQL
Spark SQL is a component on top of Spark Core that introduces a new data abstraction called SchemaRDD, which provides support for structured and semi-structured data.
Spark Streaming
Spark Streaming leverages Spark Core's fast scheduling capability to perform streaming analytics. It ingests data in mini-batches and performs RDD (Resilient Distributed Datasets) transformations on those mini-batches of data.
MLlib (Machine Learning Library)
MLlib is a distributed machine learning framework above Spark because of the distributed memory-based Spark architecture. It is, according to benchmarks, done by the MLlib developers against the Alternating Least Squares (ALS) implementations. Spark MLlib is nine times as fast as the Hadoop disk-based version of Apache Mahout (before Mahout gained a Spark interface).
一个常用机器学习算法库,算法被实现为对 RDD 的 Spark 操作。
GraphX
GraphX is a distributed graph-processing framework on top of Spark. It provides an API for expressing graph computation that can model the user-defined graphs by using Pregel abstraction API. It also provides an optimized runtime for this abstraction.
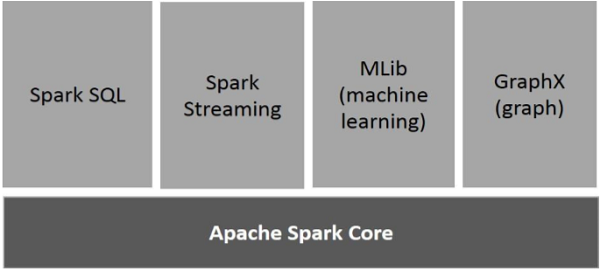
Spark 库本身包含很多应用元素,这些元素可以用到大部分大数据应用中,其中包括对大数据进行类似 SQL 查询的支持,机器学习和图算法,甚至对实时流数据的支持。