开始学习《数据算法:Hadoop/Spark大数据处理技巧》第1-5章,假期有空就摘抄下来,毕竟不是纸质的可以写写画画,感觉这样效果好点,当然复杂的东西仍然跳过。写博客越发成了做笔记的感觉。
以上。
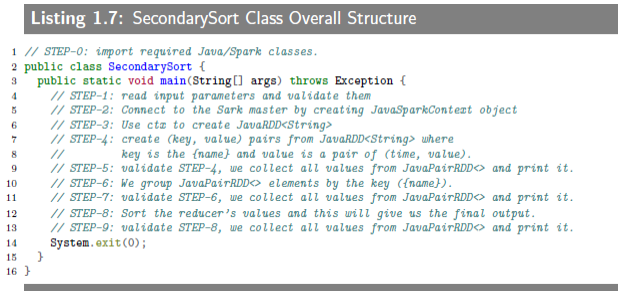
1.1 What is a Secondary Sort Problem?
MapReduce framework automatically sorts the keys generated by mappers.What we know is that MapReduce sorts input to reducers by key and values maybe arbitrarily ordered.MapReduce/Hadoop and Spark/Hadoop do not sort values for a reducer.Secondary Sort design pattern enable us to sort reducer's values.
"Secondary Sorting Problem" is the problem of sorting values associated with a key in the reduce phase.Sometimes,this is called "value-to-key conversion".The "Secondary Sorting" technique will enable ud to sort the values (in ascending or descending order) passed to each reducer.
大概就是说,map 函数输出的键值对只按键排序,但是我们希望在此基础上输出也能对值进行排序。举个例子来说,那个分析气象数据来找出最高温的问题,原来 map 函数的输出假设是(1950, 0)、(1950, 20)、(1950, 10)、(1951,...现在希望是(1950, 0) (1950, 10) (1950, 20)、(1951,...这就是所谓的“二次排序”,然后貌似并没有详细解释这样会有什么好处,只是说有时我们希望是这样,大概是有某种需求吧。
1.2 Solutions to Secondary Sort Problem
There are at least two possible approaches for sorting the reducer's values.
- The first approach involves having the reducer read and buffer all of the values for a given key(in an array data structuce,for example)Then do an in-reducer sort on the values.This approach will not scale:since the reducer will be receiving all values for a given key,this approach could possibly cause the reducer to run out of memory(java.lang.OutOfMemoryError).Tihs approach can work well if the number of values is small enough,which will not cause out-of memory error.
- The second approach involves using MapReduce framework for sorting the reducer's values(does not require in-reducer sorting of values passed to the reducer).This approach involves "creating a composite key by adding a part of,or the entire value to,the natural key to achieve your sorting objectives".For the details on this approach,see javacodegeeks.The second approach is scaleable and you will not see out-of-memory errors.Here,we basically offload the sorting to the MapReduce framework(sorting is a paramount feature of MapReduce/Hadoop framework).
This is the summary of second appoach:
- Use "Value-to-Key Conversion" dedisn pattern
- Let MapReduce execution framework do the sorting(rather than sorting in the memory,let the framework do the sorting by using the cluster nodes)
- Preserve state across multiple(key, value)pairs to handle processing;this can be achieved by having proper mapper output partitioners
接着开始说如何解决“二次排序”问题,说了两种方法。一是 reducer 把收到的键值对按键先存着,全部接受完之后,再分别对其按值进行排序。缺点是需要读完全部的数据,而且可能有存储空间不够的问题,适用于数据量很少的情况。第二种方法显然比较高大上,空间不会不够还是可伸缩的,没怎么看懂。大概是用 MapReduce 框架来进行排序,要在值的基础上再添加新的键。
Implementation details
To implement the "Secondary Sort" feature,we do need additional plug-in Java classes.We have to tell to MapReduce/Hadoop framework:
- how to sort reducer keys
- how to partition keys passed to reducers(custom partitioner)
- how tp group data reached to reducers
1.2.1 Sort Order of Intermediate Keys
First,we inject value(temperature data)to the composite key and then provide control on sort order of intermediate keys.In this section,we will implement the "Secondary Sort"(or so called "value to key")approach.We have to mention how DataTemperaturePair Objects are sorted by the compareTo() method.You need to define a proper data structure for holding your key and value,while also providing the sort order of intermediate keys.In Hadoop,to persist custom data types,they have to implement the Writable inerface;and if we are going to compare custom data types,then they have to implement an additinal interface called WritableComparable.
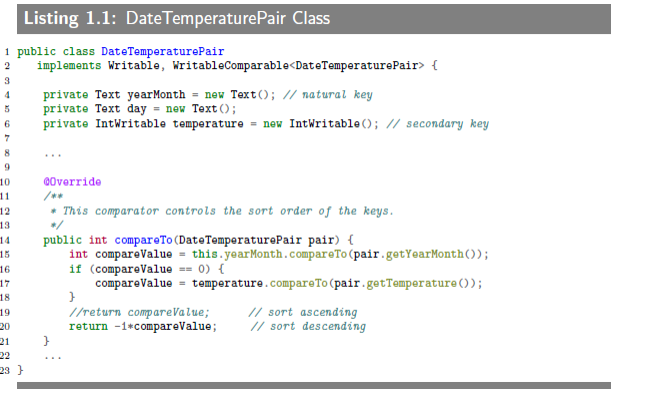
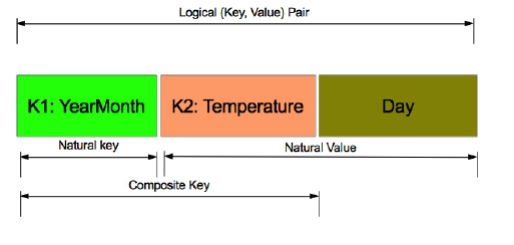
为了实现二次排序(这个例子中即按气温再排一次),我们需要把部分或全部的值(例子即气温)和原来的键组成复合键(中间键),并且提供相应的比较函数。大概是这么个意思吧,然后代码啥的当然是不抠。
1.2.2 Partition Code
In a nutshell,partitioner decides which mapper output goes to which reducer based on mapper output key.We do need to write a custom partitioner to ensure that all the data with same key(the natural key not including the composite key with the value - value is the temperature data field)is sent to the same reducer and a custom Comparator so that the natural key(composite of year and month)groups the data once it arrives at the reducer.
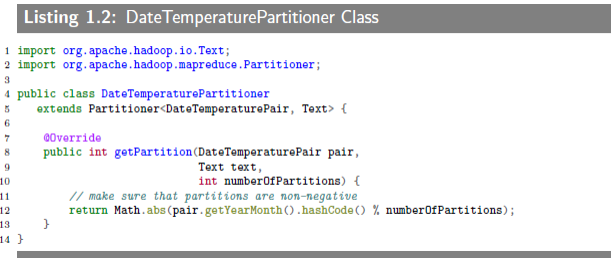
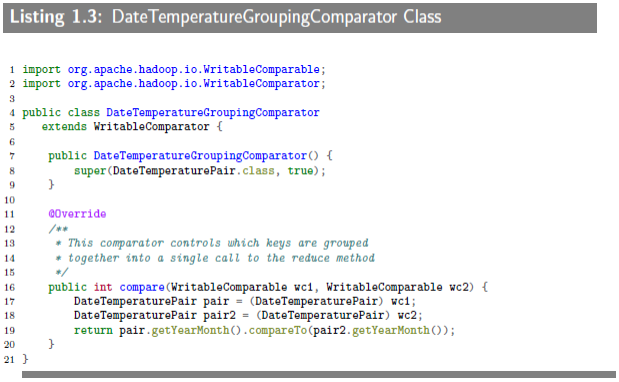
1.2.3 Grouping Comparator
We define the comparator(DataTemperatureGroupingComparator class) that controls which keys are grouped together for a single call to Reducer.reduce() function.
看得懂英文意思,但是仍然不清楚1.2.2和1.2.3在干啥。唔,问题不大,继续往下。
1.3 Data Flow Using Plug-in Classes
To understand the map(),reduce()and custom plug-in classes,the data flow for portion of input is illustrated blew.
The mappers creat(K, V)pairs,where K is a composite key of (year, month, temperature) and V is a temperature.Note that (year, month) part of the composite key is called a natural key.The partitioner plug-in class enables us to send all natural keys to the same reducer and "grouping comparator" plug-in class enables temperature's to arrive sorted to reducers.The "Secondary Sort" design pattern uses MapReduce's framework for sorting the reducer's values rather than collecting all and then sort in the memory.The "Secondary Sort" design pattern enables us tp "scale out" no matter how many reducer values we want to sort.

作者都这么生动形象了,然而并没有什么用,还是不大理解这种方法的原理。
1.4 MapReduce/Hadoop Solution
This section provides a complete MapReduce implementation of "Secondary Sort" problem by using Hadoop framework.
1.4.1 Input
Input will be a set of files,which will have the following format:

1.4.2 Expected Output
Output will be a set of files,which will have the following format:

1.4.3 map() function
The map() function parses and tokenizes the input and then injects the value(value of temperature)into the reducer key.
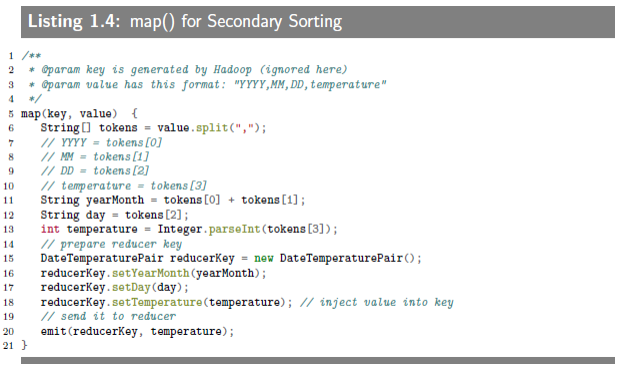
1.4.4. reduce() function

1.4.5 Hadoop Implementation
The following classes are used to solve the problem.
The first comparator(DataTemperaturePair.compareTo method)controls the sort order of the keys and the second comparator(DataTemperatureGroupingComparator.compare() method)controls which keys are grouped together into a single call to the reduce method.The combinnation of these two allows you to set up jobs that act like you've defines an order of the values.
The SecondarySortDriver is the driver class,which registers the custom plug-in classes (DataTemperaturePartitioner and DataTemperatureGroupingComparator classes) with the Mapreduce/Hadoop framework.This class is presented below:

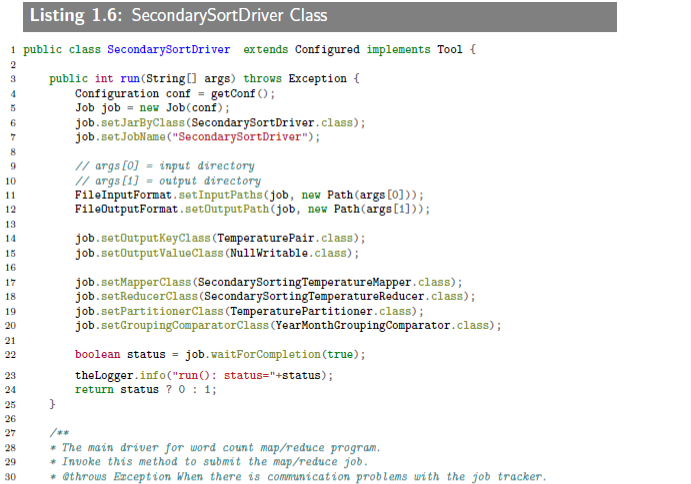
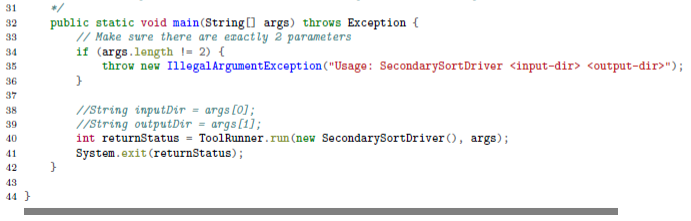
特地举了个例子来说明怎么应用,输入输出长啥样,要写哪些代码。这些代码我当然是写不出来啦,看看就好,看看就好。这里跳过“1.4.6 and 1.4.7 sample run”,实际的运行情况,有输入文件,脚本,执行日志啥的,贴上来也看不懂,不管。
1.5 What if Sorting Ascending or Descending

1.6 Spark Solution To Secondary Sorting
To solve a "secondary sort" in Spark,we have at least two options and we will present a solution to each option.
- OPTION-1:read and buffer all of the values for a given key in an array of a list data structure and then do an in-reducer sort on the values.This solution works if you have small set of values(which will fit in memory)per reducer key.
- OPTION-2:use Spark framework for sorting the reducer's values(does not repuire in-reducer sorting of values passed to the reducer).This approach involves "creating a composite key by adding a part of,or the entire value to,the natural key to achieve your sorting objectives".This option always scales(because you are not limited by memory of a commodity server).
这不是和上面的解决方法一样么。
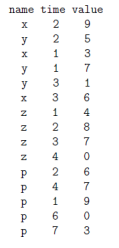
1.6.1 Time-Series as Input
To demostrate "secondary sorting", let's use a time-series data:
1.6.2 Expected Output
Our expected output is illustrated blew. As you observe, the values of reducers are grouped by "name" and sorted by "time".

同样的,举例子之前先说明输入输出。
1.6.3 Option-1:Secindary Sorting in Memory
Since Spark has a very powerfull and high-level API, we will present the entire solution in a single Java class. Spark API is built by the basic abstraction concept of RDD (Resilient Distributed Dataset). To fully utilize Spark's API, we have to understand RDD's. An
RDD<T>(or type T) object represents an immutable, partitioned collection of elements (or type T) that can be operated on in parallel. TheRDD<T>class contains the basic MapReduce operations available on all RDDs, such as map, filter, and persist. WhileJavaPairRDD<K, V>class contains the basic MapReduce operations such as mapToPair, flatMapToPair, and groupByKey. In additon, Spark's PairRDDFunctions contains operations available only on RDDs of (key, value) pairs, such as reduce, groupByKey and join. For details on RDDs, see Spark's API. Therefore,JavaRDD<T>is a list of objects of type T andJavaPairRDD<K, V>is a list of objects of typeTuple2<K, V>(each tuple represents a (key, value) pair).
稍微了解了一下 Spark,看起来感觉好一点。Spark 有着很高级的 API ,这个例子甚至可以只要写一个类。RDD (Resilient Distributed Dataset, 弹性分布式数据集)是 Spark 的核心,是一个抽象模型,是一个不可修改的分割的数据集(反正就很厉害)。
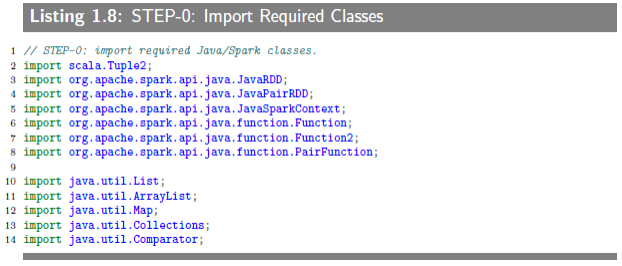
1.6.3.1 STEP-0: Import Required Classes
The main Spark packeage for Java API is org.apache.api.java, which includes JavaRDD, JavaPairRDD and JavaSparkContext classes. The JavaSparkContext is a factory class for creating new RDDs (such as JavaRDD and JavaPairRDD).
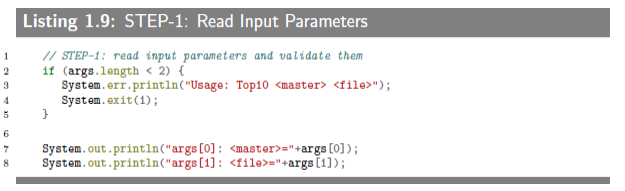
1.6.3.2 STEP-1: Read Input Parameters
This step reads a spark master URL and HDFS input file. The examples for this step can be:
- Spark master URL:
spark://<spark-master-node>:7077- HDFS file:
/dir1/dir2/myfile.txt
1.6.3.3 STEP-2: Connect to the Sark Master
To do some work with RDDs, first you need to create a JavaSparkContext object, which id a factory class for creating JavaRDD and JavaPairRDD objects. It is also possible to create a JavaSparkContext object by injecting SparkConf object to JavaSparkContext's class constructor. This approach is useful when you read your cluster configurations from an XML file. In a nutshell, JavaSparkContext object has following responsibilities:
- Initializes the application driver
- Registers the application driver to the cluster manager (if you are using Spark cluster, then this will be Spark master, and if you are using YARN, then that will be YARN‘s resource manager)
- Obtain a list of executors for executing your application driver

实际上我觉得 “Spark Master” 比较合理啊。
1.6.3.4 STEP-3: Use JavaSparkContext to Creat JavaRDD
This step reads an HDFS file and creates a
JavaRDD<String>(represents a set of records – each record is a String object). By definition, Spark‘s RDDs are immutable (cannot be altered or modified). Note that Spark‘s RDDs are the basic abstraction for parallel execution.
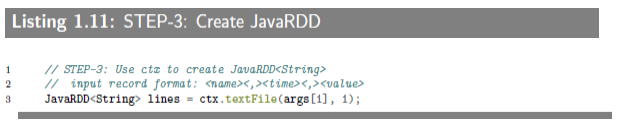
从 HDFS 文件中读取输入,并以字符串形式存放在“JavaSparkContext”创建的“JavaRDD
1.6.3.5 STEP-4: Creat(key, value) pairs from JavaRDD
This step implements a mapper. Each record (from
JavaRDD<String>as<name><,><time><,><value>) is converted to a (key, value) where key is a name and value is a Tuple2(time, value).
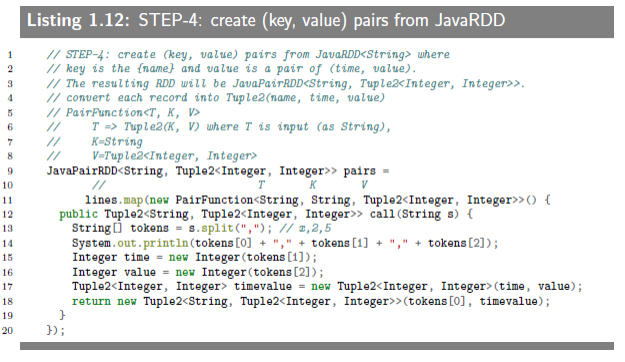
将JavaRDD<String>中的记录变成键值对的形式,并将键值对存放在“JavaSparkContext”创建的“JavaPairRDD”中。这个例子中, key 是 name, value 是元组 (time, value)。
1.6.3.6 STEP-5: Validate STEP-4
To debug and validate your steps in Spark, you may use JavaRDD.collect() and JavaPairRDD.collect().
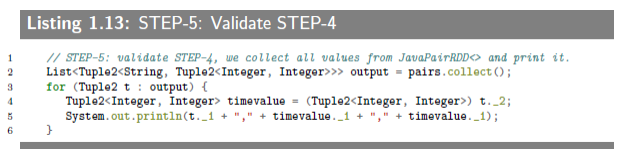
检验存放在“JavaPairRDD”中键值对是否正确,方法就是打印出来。
1.6.3.7 STEP-6: Group JavaPairRDD elements by the key (name)
We implement the reducer operation by groupByKey(). As you observe, it is much easier to implement the reducer by Spark than MapReduce/Hadoop.

用动作groupByKey() 来对“JavaPairRDD”中的键值对按键排序,说比 MapReduce/Hadoop 简单得多(Hadoop 不是会自动按键排序么)。
1.6.3.8 STEP-7: Validate STEP-6
The output of this step is presented below. reducer values are not sorted.
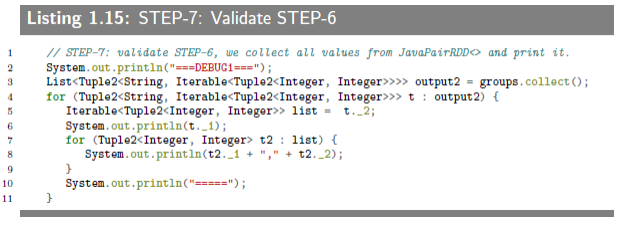

打印按键排序之后的键值对以检查是否正确,同时可以发现此时的键值对的值是无序的。
1.6.3.9 STEP-8: Sort the Reducer's Values in Memory
This step uses another powerful Spark method mapValues() to just sort the values generted by reducers. The mapValues() method enable us to convert (K, V1) into (K, V2). One important note about Spark‘s RDD is that they are immutable and can not be altered/updated by any means. For example, in STEP-8, to sort our values, we have to copy them into another list before sorting. Immutability applies to RDD itself and its elements.

利用函数 mapValue() 让 reducer 来进行二次排序。需要注意的是,Spark 的 RDD 是不可变的,这意味着其元素也是不可变的。所以在我们排序之前,我们得将数据复制到另一个 list 上。
1.6.3.10 STEP-9: Output Final Result
The collect() method collects all RDD‘s elements into a java.util.List object. Then we iterate through the List to get all final elements.
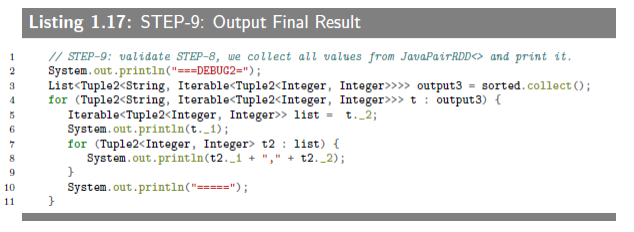
最后的输出保存在一个 Java list 对象里,遍历这个 list 即可检验结果。
同样跳过“1.6.4 SparkSample Run”,稍微提一下“1.6.4.2 Spark Run”,说运行 Spark 应用有三种不同的模式。
As far as Spark/Hadoop is concerned: you can run a Spark application in three different modes:
- Standalone mode, which is the default setup. You start Spark master on a master node and a "worker‖"on every slave node and submit you Spark application to the Spark master.
- YARN client mode: in this mode, you do not start a spark master or worker nodes. In this mode, you submit the Spark application to YARN, which runs the Spark driver in the client Spark process that submits the application.
- YARN cluster mode: in this mode, you do not start a spark master or worker nodes. In this mode, you submit the Spark application to YARN, which runs the Spark driver in the ApplicationMaster in YARN.
1.6.5 Option-2: Secondary Sorting using Framework
In solution for Option-1, we sorted reducers values in memory (using Java‘s Collections.sort() method), which might not scale if the reducers values will not fit in a commodity server‘s memory. We implemented Option-2 for MapReduce/Hadoop framework. we cannot achieve this in current Spark (Spark-1.0.0) framework, because current Sparks Shuffle is based on hash, which is different from MapReduces sort-based shuffle, so you should implement sorting explicitly using RDD operator. If we had a partitioner by a natural key (by name), which preserved the order of RDD, then that would be a viable solution: for example, if we sort by (name, time), we would get:
There is a partitioner (represented as an abstract class org.apache.spark.Partitioner), but it does not preserve the order of original RDD elements. Therefore, Option-2 cannot be implemented by the current version of Spark (1.0.0).
简单来说就是,Spark (1.0.0) 无法实现方法二。因为 Spark 的中间结果是基于 hash ,不像 MapReduce 是按键排序的,你只能用 RDD 动作来排序。如果有一个 partitioner 支持 RDD 的动作,那么理论上这会是一个可行的方法。但是,Spark (1.0.0) 并没有这样的 partitioner(不明觉厉有没有)。
第一章就这样,总结一下收获。知道了“二次排序”问题到底是什么问题,就字面意思的排两次序嘛。解决该问题的两个方法:一是把第一次排好的缓存,全部缓存之后再排第二次(适用于数据规模小的情形,太大缓存不来,还可能停不下来);二是利用大数据处理框架来二次排序,不是很懂具体过程,好像是把任务再具体的“分割”,像是先排好月份气温的序,然后年份的就组合起来(什么鬼),总之比第一种方法好。还有两种方法的实现,书上详细的举了例子写了代码,甚至还实际运行(嗯,跳得不亦乐乎)。Hadoop 两种都能实现,Spark (1.0.0) 不能实现第二种(反正目前我是肯定用不上的)。总得来说,只知道个大概,还差得远。但是,问题不大,继续往下。