数据介绍:
2008美国国内航班数据
- airports.csv
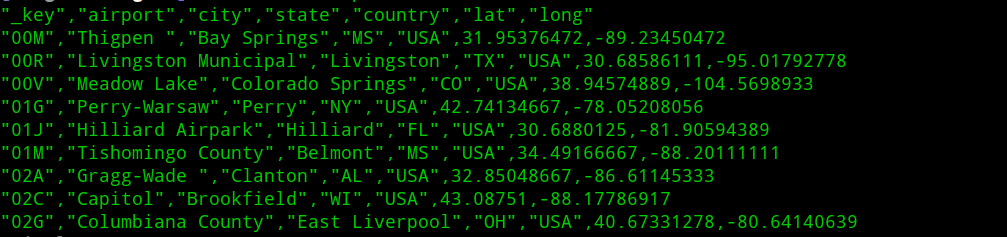
- flights.csv

数据下载地址:https://www.arangodb.com/graphcourse_demodata_arangodb-1/
数据导入:
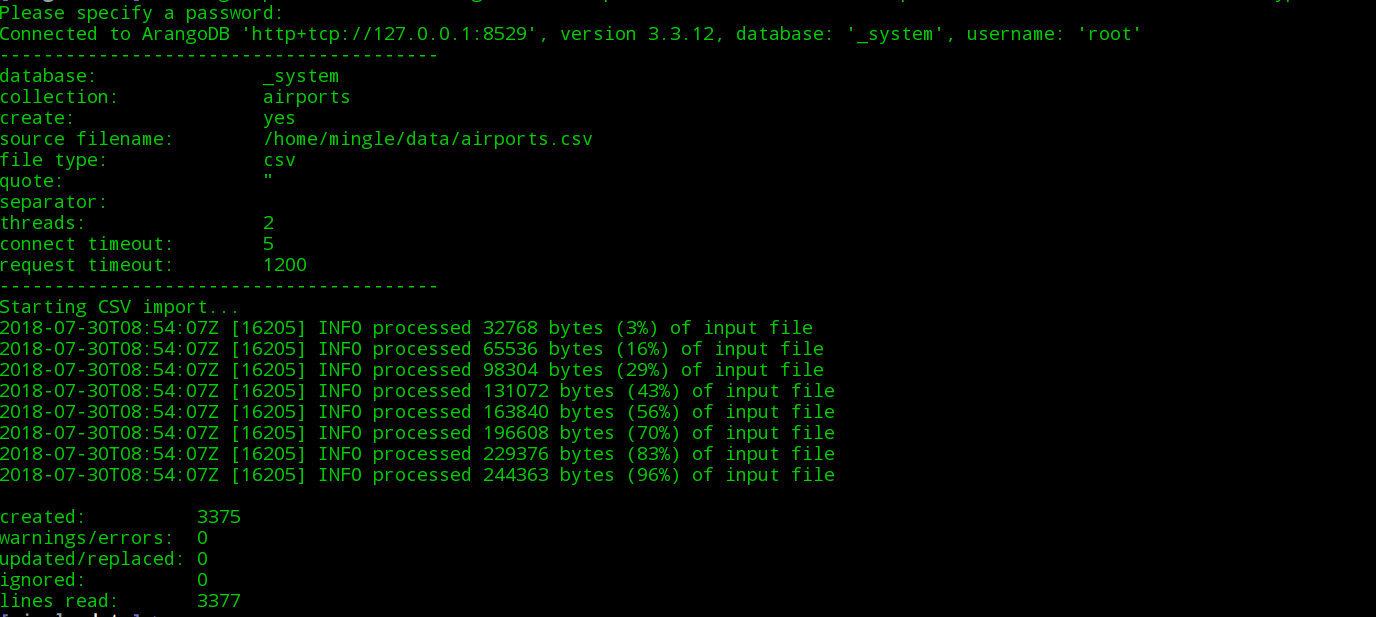
在终端中输入以下命令:
arangoimp --file path to airports.csv on your machine --collection airports --create-collection true --type csv
显示以下结果:
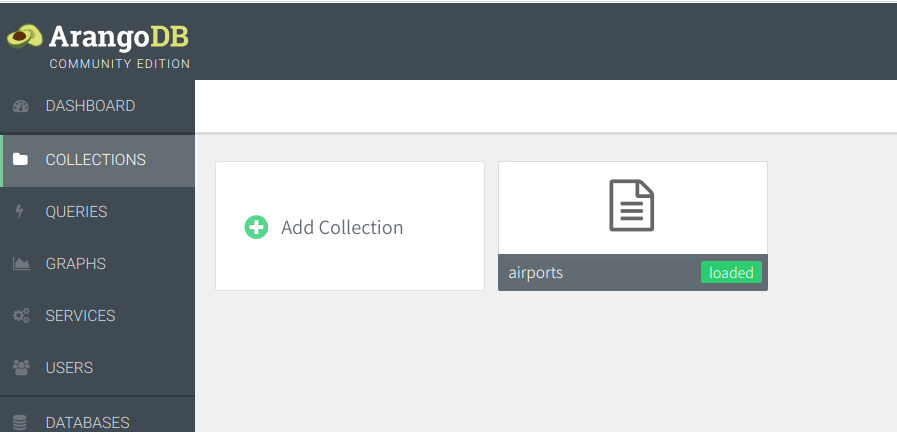
使用网页UI:
COLLECTIONS
点击页面左侧按钮"COLLECTIONS",可以看到之前导入的数据集"airports",图标样式表明它是一个文本集合
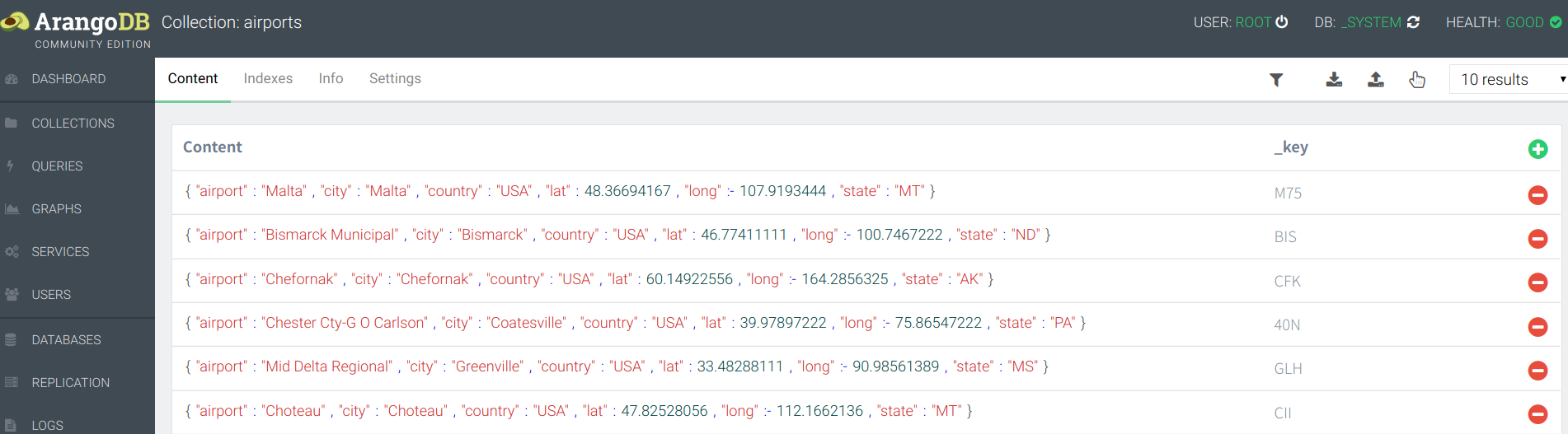
点击进入数据集"airports",该页面包含了对数据集的预览、筛选、上传、下载和删除等操作
QUERIES
该模块提供了AQL查询功能

尝试几个简单的查询
1、返回数据集"airports"中所有的airports:
FOR airport IN airports RETURN airport
2、只返回California的airports:
FOR airport IN airports
FILTER airport.state == "CA"
RETURN airport
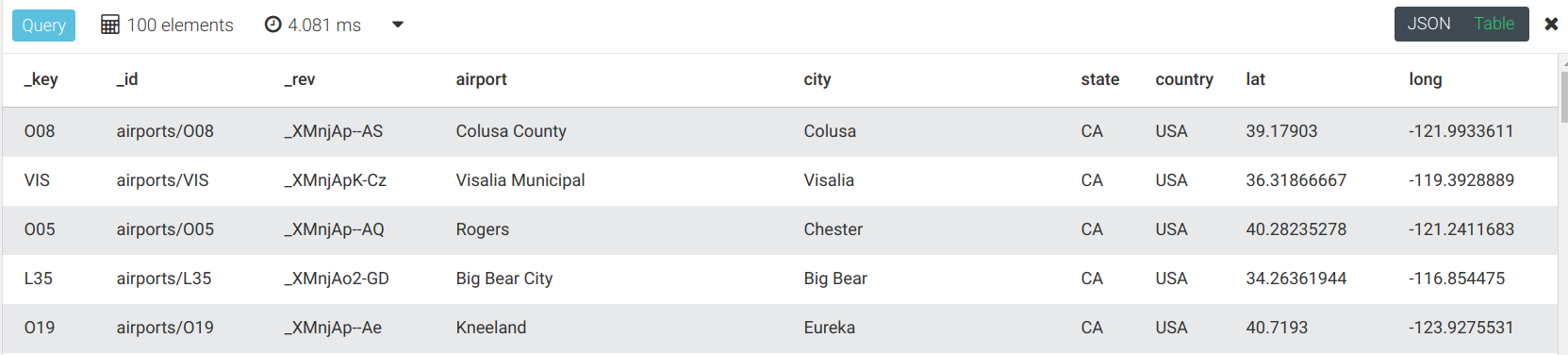
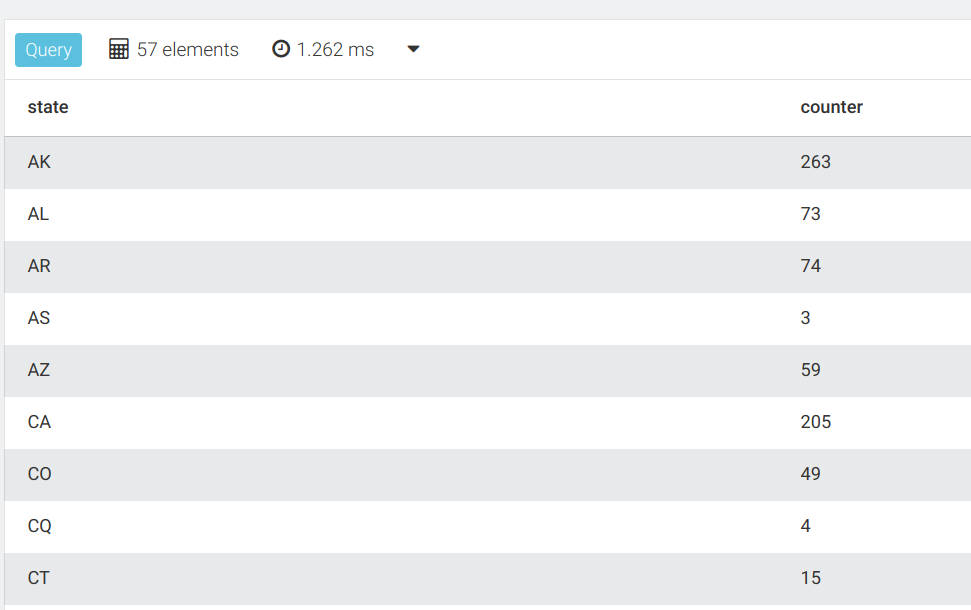
3、返回每个国家的机场数量
FOR airport IN airports
COLLECT state = airport.state
WITH COUNT INTO counter
RETURN {state, counter}
注意:
在上面的代码示例中,所有关键字COLLECT、WITH和RETURN等都是大写的,但它只是一个约定。你也可以将所有关键词小写或混合大小写。但是变量名、属性名和集合名是区分大小写的。
Graph Basics:
上面的例子中,我们使用的数据"airports"可以当做图的节点,但是为了完善图,我们还需要数据来作为边,在这里我们使用''flights"中的数据作为边。
首先导入"flights.csv"文件
arangoimp --file "/home/data/flights.csv" --collection flights --create-collection true --type csv --create-collection-type edge
得到如下结果表明数据导入成功:
the concepts of the query options:
FOR vertex[, edge[, path]]
IN [min[..max]]
OUTBOUND|INBOUND|ANY startVertex
edgeCollection[, more…]
Explanation
FOR 有三个参数
‣ vertex (object): 遍历中的当前顶点
‣ edge (object, optional): 遍历中的当前边
‣ path (object, optional): 两个对象的路径表示
‣ vertices: 此路径上所有顶点的数组
‣ edges: 此路径上所有边的数组
IN min..max: 定义遍历的最小深度和最大深度。如果未指定,默认为1!
OUTBOUND/INBOUND/ANY :定义搜索的方向
edgeCollection: 保存在遍历中要考虑的边缘的集合的一个或多个名称
OPTIONS options(object,optional):用于修改遍历的执行。只有以下属性有效果,所有其他属性将被忽略:
uniqueVertices(string):可选地确保顶点唯一性
“path” - 保证没有路径返回一个重复的顶点
“global” - 保证在遍历期间每个顶点最多被访问一次,无论从起始顶点到这个顶点有多少路径。如果您从最小深度min depth > 1之前发现的顶点开始,可能根本不会返回(它仍然可能是路径的一部分)。注意: 使用此配置,结果不再是确定性的。如果从startVertex到顶点有多条路径,则选择其中一条路径。
“none”(默认) - 不对顶点应用唯一性检查
uniqueEdges(string):可选地确保边缘唯一性
“path”(默认) - 保证没有路径返回一个重复的边
“global” - 保证在遍历过程中,每个边缘最多被访问一次,无论从起始顶点到该边缘有多少条路径。如果从a开始,min depth > 1在最小深度之前发现的边缘根本不会被返回(它仍然可能是路径的一部分)。注意: 使用此配置,结果不再是确定性的。如果有从多个路径startVertex超过边缘的那些中的一个被拾取。
“none” - 不对边缘应用唯一性检查。注意: 使用此配置,遍历将跟随边沿周期。
bfs(bool):可选地使用可选的宽度优先遍历算法
true - 遍历将被执行宽度优先。结果将首先包含深度1的所有顶点。比深度2处的所有顶点等等。
false(默认) - 遍历将以深度优先执行。它首先将深度1的一个顶点的最小深度的最小深度返回到最大深度。对于深度1处的下一个顶点,依此类推。
图查询:
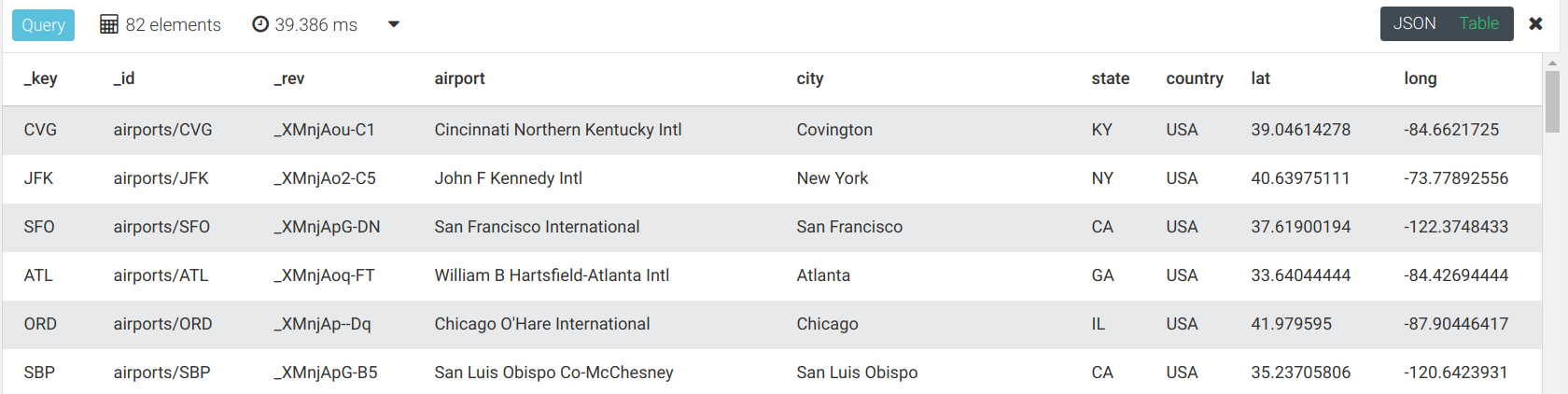
1、返回能到达洛杉矶国际机场(Lax)的所有机场
FOR airport IN OUTBOUND 'airports/LAX' flights
RETURN DISTINCT airport
2、返回10个洛杉矶的航班和他们的目的地
FOR airport, flight IN OUTBOUND 'airports/LAX' flights
LIMIT 10
RETURN {airport, flight}

遍历图:
对于最小深度大于2的遍历,有两个选项可以选择:
深度优先(默认):继续沿着从起始顶点到该路径上的最后顶点的边缘,或者直到达到最大遍历深度,然后向下走其他路径
广度优先(可选):从开始顶点到下一个级别遵循所有边缘,然后按另一个级别跟踪邻居的所有边缘,并继续这个模式,直到没有更多的边缘跟随或达到最大的遍历深度。
返回LAX直达的所有机场:
FOR airport IN OUTBOUND 'airports/LAX' flights
OPTIONS {bfs: true, uniqueVertices: 'global'}
RETURN airport
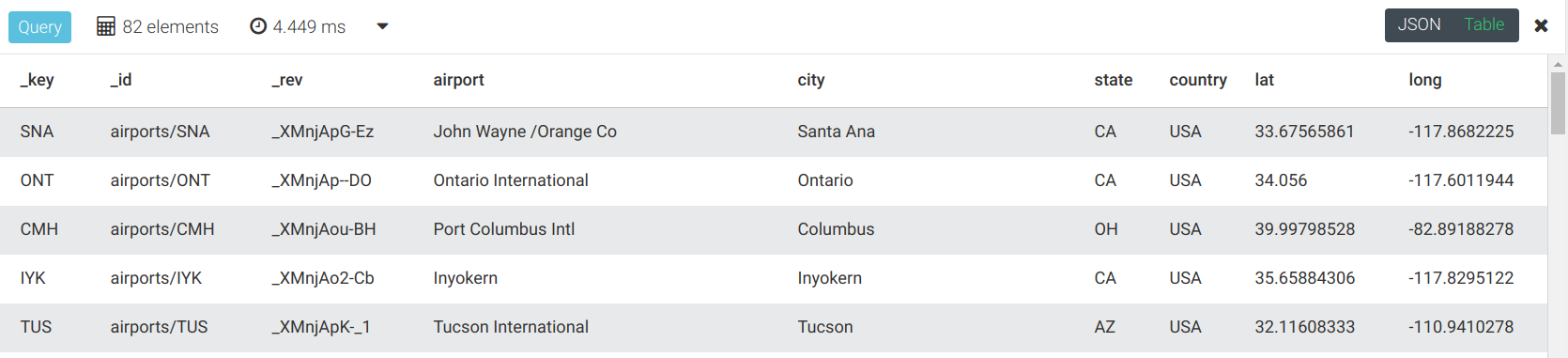
通过执行时间与之前的查询进行比较,返回相同的机场:
FOR airport IN OUTBOUND 'airports/LAX' flights
RETURN DISTINCT airport
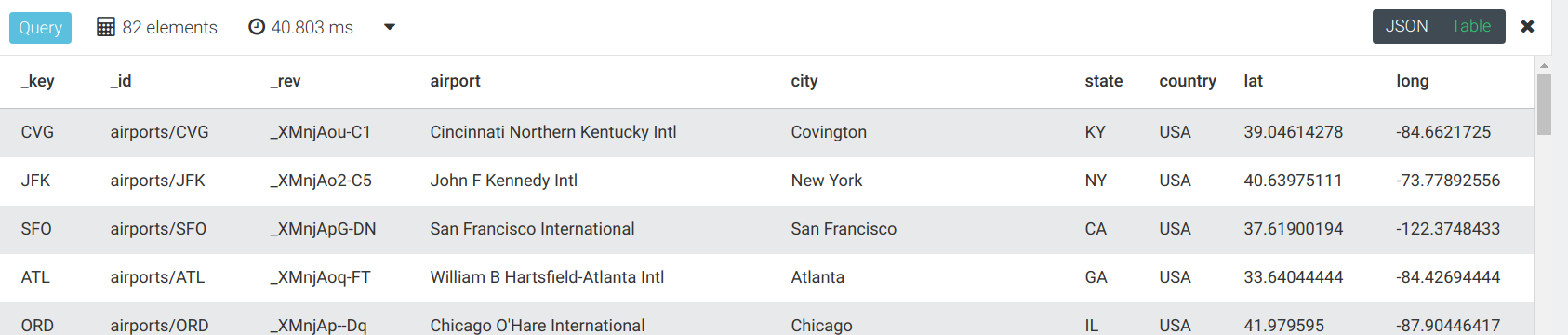
对比这两次结果,将看到显著的性能改进。
The LET keyword in AQL
Hands on: Storing Results in Variables
简单表达式以及整个子查询的结果可以存储在变量中。若要声明变量,请使用LET关键字,后面跟着变量名、等号和表达式。如果表达式是子查询,则代码必须位于括号中。
在下面的示例中,预先计算出发时间的时间和分钟,并将其存储在变量H和M中。
FOR f IN flights
FILTER f._from == 'airports/BIS'
LIMIT 100
LET h = FLOOR(f.DepTime / 100)
LET m = f.DepTime % 100
RETURN {
year: f.Year,
month: f.Month,
day: f.DayofMonth,
time: f.DepTime,
iso: DATE_ISO8601(f.Year, f.Month, f.DayofMonth, h, m)
}

Shortest_Path
最短路径查询在两个给定文档之间找到连接,其边缘数量最少。
寻找机场BIS和JFK之间的最短路径:
FOR v IN OUTBOUND
SHORTEST_PATH 'airports/BIS'
TO 'airports/JFK' flights
RETURN v

返回从BIS到JFK的最小航班数:
LET airports = (
FOR v IN OUTBOUND
SHORTEST_PATH 'airports/BIS'
TO 'airports/JFK' flights
RETURN v
)
RETURN LENGTH(airports) - 1

Pattern Matching
目标:找出BIS与JFK之间花费时间最短的路径
STEP1
筛选BIS到JFK的所有路径,由于在shortest path中最短路径深度为2,所以这里直接使用“IN 2 OUTBOUND”
FOR v, e, p IN 2 OUTBOUND 'airports/BIS' flights
FILTER v._id == 'airports/JFK'
LIMIT 5
RETURN p
STEP2
筛选一天内的路径,这里以1月1号为例
FOR v, e, p IN 2 OUTBOUND 'airports/BIS' flights
FILTER v._id == 'airports/JFK'
FILTER p.edges[*].Month ALL == 1
FILTER p.edges[*].DayofMonth ALL == 1
LIMIT 5
RETURN p
STEP3
使用DATE_DIFF() 函数计算出发时间与到达时间的差值,然后将结果升序排列
FOR v, e, p IN 2 OUTBOUND 'airports/BIS' flights
FILTER v._id == 'airports/JFK'
FILTER p.edges[*].Month ALL == 1
FILTER p.edges[*].DayofMonth ALL == 1
LET flightTime = DATE_DIFF(p.edges[0].DepTimeUTC, p.edges[1].ArrTimeUTC, 'i')
SORT flightTime ASC
LIMIT 5
RETURN { flight: p, time: flightTime }
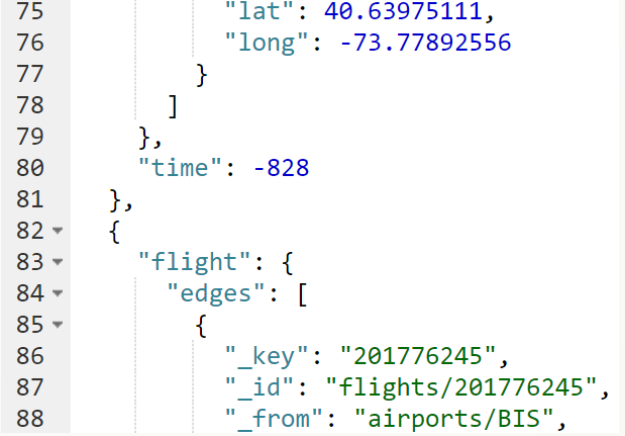
通过观察结果,我们发现有些结果是负值。原因是有些路径中,第一条航线未降落时,第二条就已经起飞,为此需要增加一条限定条件。
FOR v, e, p IN 2 OUTBOUND 'airports/BIS' flights
FILTER v._id == 'airports/JFK'
FILTER p.edges[*].Month ALL == 1
FILTER p.edges[*].DayofMonth ALL == 1
FILTER DATE_ADD(p.edges[0].ArrTimeUTC, 20, 'minutes') < p.edges[1].DepTimeUTC
LET flightTime = DATE_DIFF(p.edges[0].DepTimeUTC, p.edges[1].ArrTimeUTC, 'i')
SORT flightTime ASC
LIMIT 5
RETURN { flight: p, time: flightTime }
至此,已经得到了用时最短的路径。
优化:
在这个例子中,我们的查询需要遍历非常多的边,其中有些边是不需要去遍历的。我们这里用vertex-centric index方法来优化。
‣ 进入Collection界面
‣ 打开 flights collection
‣ 点击Indexes 选项
‣ 点击绿色的+号来添加一个新的索引

‣ 设置 Type 为 Hash Index
‣ 在Fields中填写 _from,Month,DayofMonth
‣ 点击绿色Create 选项生成新索引

重新运行STEP3代码,会发现运行效率大大提高,点击Explain选项能够看到以下信息:

原理解释:
如果没有以顶点为中心的索引,则需要跟踪出发机场的所有外出边缘,然后检查它们是否满足我们的条件(在某一天,到达期望的目的地,具有可行的中转)。
我们创建的新索引允许在某一天(Month,DayofMonth属性)内快速查找离开机场的外部边缘(_from属性),这消除了在不同天提取和过滤所有边缘的需要。它减少了需要用原始索引检查边缘的数量,并节省了相当长的时间。
参考资料:
https://www.arangodb.com/documentation/