首先介绍一下我的环境,我是在vmware12版本下安装的CentOS-7-x86_64-DVD-1804版本
1、安装python3
#python官网下载python
sudo wget https://www.python.org/ftp/python/3.6.8/Python-3.6.8.tar.xz
#配置yum源
sudo yum groupinstall 'Development Tools'
#yum源安装python需要的库
sudo yum install openssl-devel bzip2-devel expat-devel gdbm-devel readline-devel sqlite-devel
#解压
sudo tar xf Python-3.6.8.tar.xz
#移动到/usr/local/python3/,没有可以mkdir建立
mv Python-3.6.8 /usr/local/python3/
#进入到Python-3.6.8/
cd /usr/local/python3/
cd Python-3.6.8/
#配置路径
sudo ./configure --prefix=/usr/local/python3 --enable-optimizations
#编译,注意在Python-3.6.8/下,失败重试前要make clean
sudo make
#安装
sudo make install
#建立软连接
sudo ln -s /usr/local/python3/bin/python3 /usr/bin/python
#如果原来的python存在导致建立软连接失败,需要删除原来的软连接
sudo rm -rf /usr/bin/python
#删除后建立软连接
sudo ln -s /usr/local/python3/bin/python3 /usr/bin/python
#查看版本
python -V
#安装完成python3后,要注意yum源是python2版本写的,所以要将yum源改回来
vi /usr/libexec/urlgrabber-ext-down
#!/usr/bin/python2.7
vim /usr.bin/yum
#!/usr/bin/python2.7
sudo yum -y install epel-release
安装pip
sudo yum install -y python-pip
2、安装jdk
jdk版本是jdk1.8.0_144
#解压到指定文件夹
tar -zxvf filename -C /usr/local/java/
#编辑/etc/下的profile文件,
vim ~/.bash_profile
#配置环境变量
export JAVA_HOME=/usr/local/java/jdk1.8.0_144
exort PATH=$JAVA_HOME/bin:$PATH
#使环境变量生效
source /etc/profile
#测试
java -version
3、安装scala
#解压文件到指定路径
sudo tar -zxvf scala-2.11.8.tgz -C /opt/app/
#进入文件
vi ~/.bash_profile
#在.bash_profile 文件下填写
export SCALA_HOME=/opt/app/scala-2.11.8
exort PATH=$SCALA_HOME/bin:$PATH
#完成后
source ~/.bash_profile
4、安装hadoop
#下载hadooop
sudo wget sudo http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0.tar.gz
#解压到/opt/app/
sudo tar -zxvf hadoop-2.6.0-cdh5.7.0.tar.gz -C /opt/app/
#进入到hadoop路径下
cd /opt/app/hadoop-2.6.0-cdh5.7.0
#修改配置文件
sudo vi ~/.bash_profile
#添加内容
export HADOOP_HOME=/opt/app/hadoop-2.6.0-cdh5.7.0
export PATH=$HADOOP_HOME/bin:$PATH
#进入到hadoop路径下的/etc/hadoop下,
/opt/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
#进入后修改配置文件,1,hadoop-env.sh
sudo vi hadoop-env.sh # The java implementation to use. #export JAVA_HOME=${JAVA_HOME} export JAVA_HOME=/opt/app/jdk1.8.0_144
#查看JAVA_HOME的路径
echo $JAVA_HOME
#改配置文件,2,core-site.xml
sudo vi core-site.xml
#修改如下,centosmj 是本地名称
<configuration> <property> <name>fs.default.name</name> <value>hdfs://centosmj:8020</value> </property> </configuration>
#修改配置文件, 3. hdfs-site.xml
sudo vi hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/app/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/app/tmp/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
#修改配置文件,4. mapred-site.xml.template
sudo vi mapred-site.xml.template
#拷贝一份模板
sudo cp mapred-site.xml.template mapred-site.xml #更改配置如下 <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
#修改配置文件,5. yarn-site.xml
sudo vi yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
#格式化hadoop,完成后会在/opt/app/tmp 下生成文件夹
sudo ./hadoop namenode -format #登陆dfs,在sbin路径下 ./start-dfs.sh
#免密登陆问题,关键->检查.ssh (700) 和 authorized_keys(600) 权限
#完成命令./start-dfs.sh后,用jps看到如下
[hadoop@centosmj sbin]$ jps 3700 SecondaryNameNode 3355 NameNode 3503 DataNode 3903 Jps
#创建文件夹 hadoop fs -mkdir /test #查看是否创建 hadoop fs -ls / #试一下放入/test下一个文件 [hadoop@centosmj hadoop-2.6.0-cdh5.7.0]$ hadoop fs -put README.txt /test/ #命令查看 hadoop fs -ls /test/ #读一下放入的文件 hadoop fs -text /test/README.txt
#在本地浏览器中试验,输入url-> centosmj:50070
#启动yarn
#进入到sbin路径下 ./start-yarn.sh #jps会看到 [hadoop@centosmj sbin]$ jps 4962 ResourceManager 3700 SecondaryNameNode 5124 Jps 3355 NameNode 5070 NodeManager 3503 DataNode
#在本地浏览器中试验,输入url-> centosmj:8088
5、安装maven
#在官网下载后解压到/opt/app/路径下,
#修改配置文件,vi ~/.bash_profile
export MAVEN_HOME=/opt/app/apache-maven-3.6.0
export PATH=$MAVEN_HOME/bin:$PATH
#修改配置文件settings.xml
#maven的配置文件settings.xml,如果不改会代码库会建在默认路径, <!-- localRepository | The path to the local repository maven will use to store artifacts. | | Default: ${user.home}/.m2/repository <localRepository>/path/to/local/repo</localRepository> --> <localRepository>/opt/maven_repository</localRepository>
6、安装spark
#spark 官网地址 spark.apache.org/downloads.html
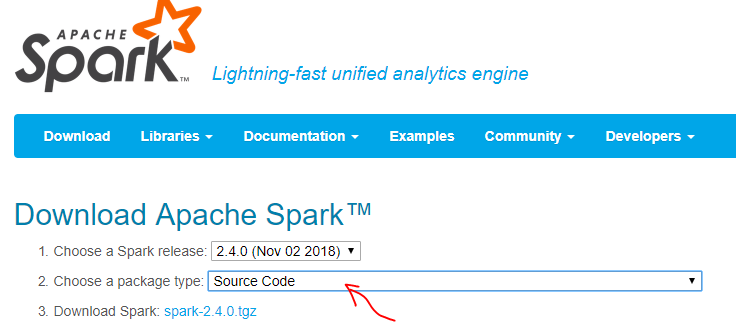
#下载后解压到/opt/app/下,进入spark目录,执行下面的命令
./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Pyarn -Phadoop-2.6 -Phive -Phive-thriftserver -Dhadoop.version=2.6.0-cdh5.7.0
#编译要很长时间,而且需要联网,网速还要好,最好能FQ。编译的过程中有许多坑!
#坑一、要修改pom.xml文件,修改远程仓库地址,(修改成阿里镜像地址,增加cdh镜像地址)
#进入spark目录下,有一个pom.xml文件,要修改它:vim ./pom.xml
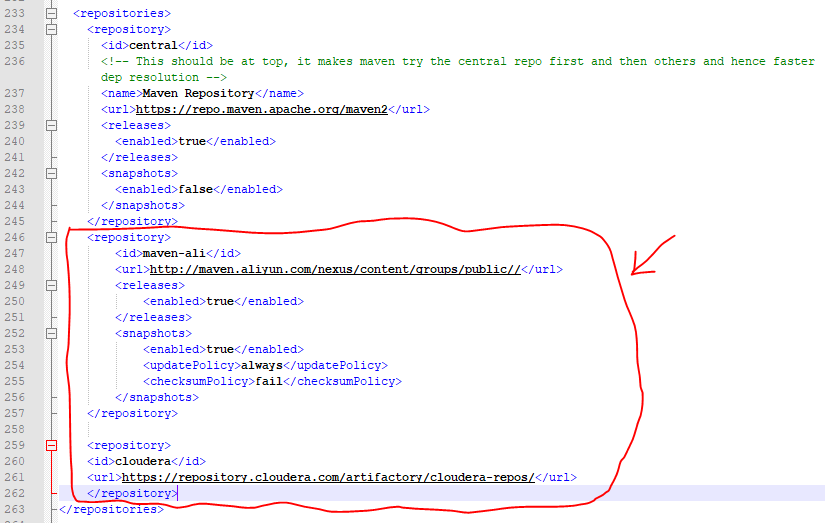
<repository>
<id>maven-ali</id>
<url>http://maven.aliyun.com/nexus/content/groups/public//</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
<updatePolicy>always</updatePolicy>
<checksumPolicy>fail</checksumPolicy>
</snapshots>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
#大家一定会有疑问这段代码应该贴在pom文件的什么位置呢,像那种贴在文件末尾段一定是不行的,
#因为pom文件是maven的核心,里面的规则还是很严谨的。那么让我的亲身经历告诉你,应该在贴在如下图所示的位置
#我把pom.xml文件拷贝出来,用Notepad++打开,网上的做法是把第一个repository替换成下面画红圈的部分,但我添加到后面也没问题。
#坑二、虚拟机的内存要大于4G,不然编译也会有问题的。
#除了上面的两个比较大的坑之外,还有许多下载失败导致编译出问题的情况,要仔细看error提示,将下载不下来的自己手动下载下来,或者重复编译一下
#本人遇到的问题还算少的,编译一共花费两个晚上一个白天。