
vs里先做了face frustrum sample三种test 剩下的 没被剔掉的 才做了varying的计算
然后genereate plygon list 写入system memory
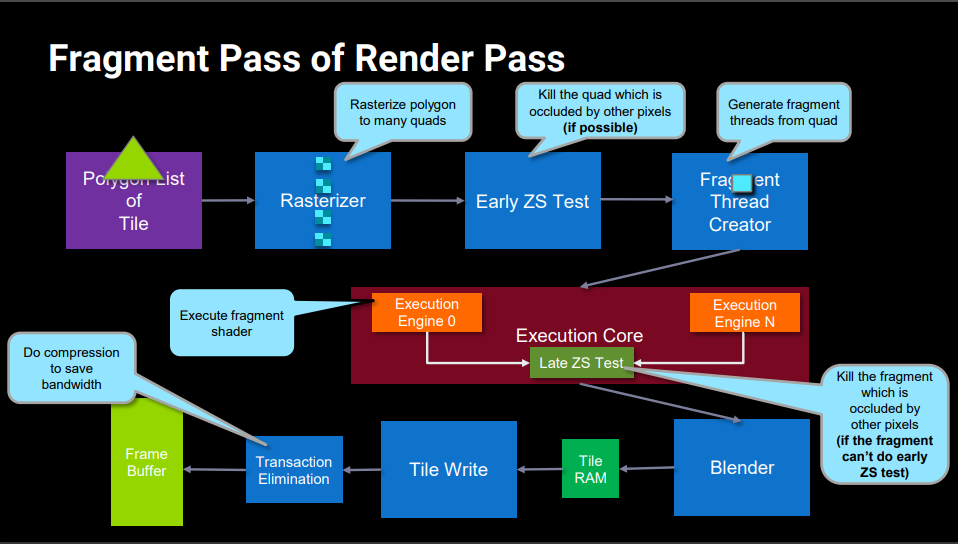
transaction elimination是mali的一个gpu优化技术
TE 为了省带宽做的
以tile为单位做比较 没更新内容的tile就不传了 用旧的
https://developer.arm.com/architectures/media-architectures/transaction-elimination
帧与帧之间 的比较 全格式支持
16x16pixels 的tile

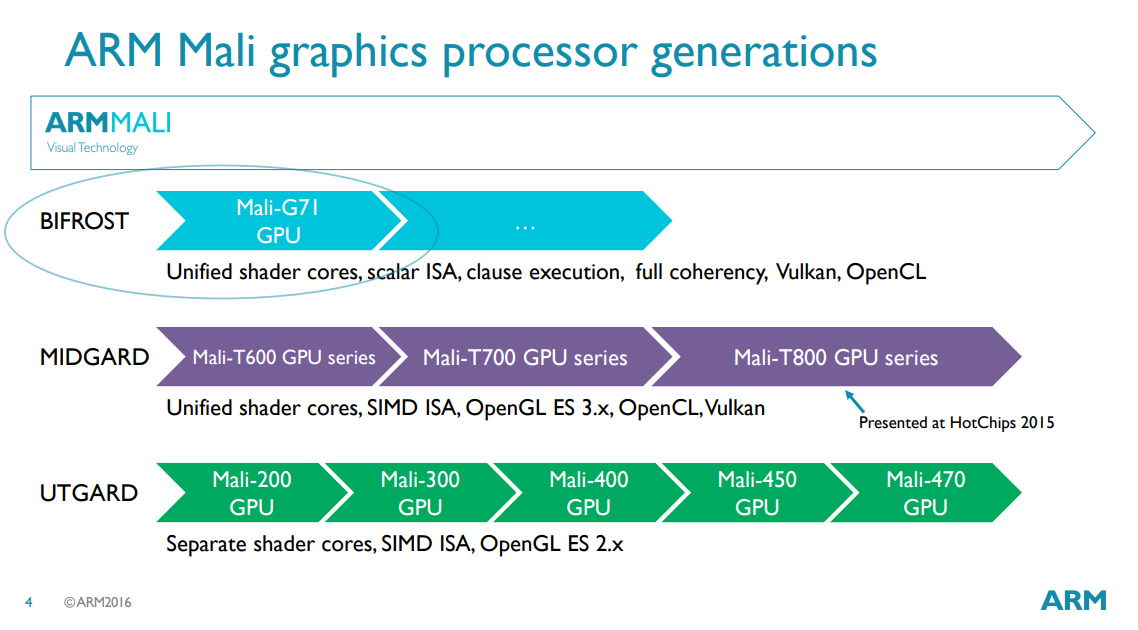
mali
Bifrost G系列
Midgard T系列 低配在这里 从这里看 opengl3.0支持
Utgard 这个没有手机用 不用看了 耶
耶 ogl2扔掉
Index-Driven Vertex Shading (IDVS)

把position和其它attitude分开放
https://community.arm.com/developer/tools-software/graphics/b/blog/posts/eats-shoots-and-interleaves
这个功能有些鸡肋,mali上多半bifrost性能够了 midgrard需要优化 可idvs低端机又不支持。。。
高端机做的feature更高,低端机还是得阉。。噢 一套数据就可以了 运行时分平台bind pack吧。。
mali的shadercore是unified的
一种core 可以做三种计算 vertex shader,fragment shader,compute kernel
MIDGARD
这个是弱一些的
MaliT系列
BIFROST
是Mali高端的G系列----摇摇欲坠的天国之路
这两者在GPU block model部分是一样的(对shader core的调度) 只是Bifrost最高32core并行 Midgard最高16core

vertex queue-----vertex/tile/compute tile是fixed管线
fragment queue--fragment
一个rendertarget的task进一个queue
一个queue的工作可以给多个shader core并行
多个queue的工作可以在一个shader core上并行
不同rt的vertex queue和fragment queue也可以并行
一个rt的vq和fq之间 必然是线性的了 fq对vq有依赖
L2cache减小的带宽在于 重复数据 的fetch 只拿一次 省的是这部分
L2cache的大小 32-64KB / shader core
L2cache到总线(system memory)的port的数量和带宽可配置 数据在32bit pixel/core/clock
8-core design to have a total of 256-bits of memory bandwidth (for both read and write) per clock cycle
bifrost 这里最高做到12core以上的带宽量 这里高于midgard
midgard shadercore
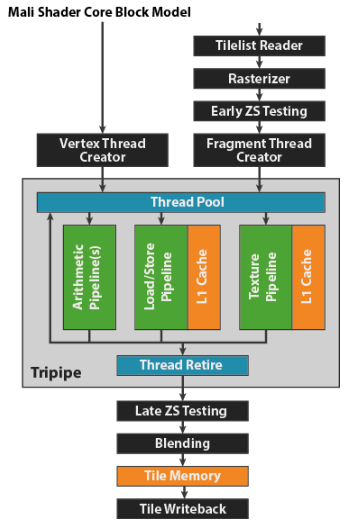
tripipe是可编程部分 其它是固定管线部分
tripipe有三部分功能
算术运算A-pipe
memory load/sstore 和 varying access --LS-pipe
texture access--texture unit ---T-pipe bilinear filter一个clock,trilinear需要两个时钟周期 因为采样两级mipmap
=================
bifrost shadercore
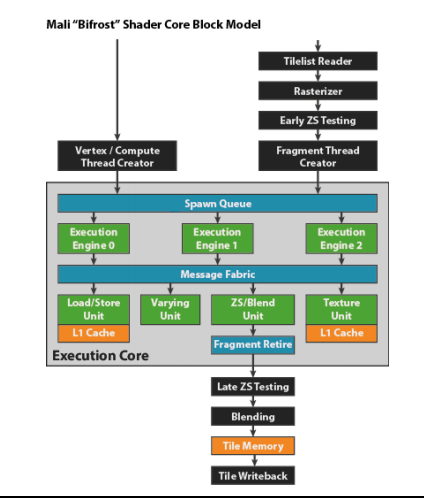

bifrost的固定部分和midgard类似
由excution core替代了 tripipe因为超过三部分了。。
一个core里面有一个或者多个excution engine做算术运算 和thread state
Load/store unit
varying unit
ZS/blend unit ---depth stencil /blend
texture unit bilinear filter一个clock,trilinear需要两个时钟周期 因为采样两级mipmap
https://admin.jlb.kr/upload/abstract/190007/259.pdf
unite 2019
http://fileadmin.cs.lth.se/cs/Education/EDAN35/guestLectures/ARM-Mali.pdf
midgard
bifrost
G76 streamline原始数据
MIDGARD
memory system
每个shader core 俩16k的L1cache--一个给texture fetche一个给geometry
所有的shader cores公用一个32K-64K的L2cache
L1和L2使用 64 byte cache lines
然后这部分信息 对优化compute shader 增加cache locality有帮助 这部分信息目前我还不太了解 mark
DDR 是Double Data Rate 随机存储器 ---内存 在时钟升沿降沿都能读写数据 所以是double rate
GPU Limits
If we scale this to a Mali-T760 MP8 running at 600MHz we can calculate the theoretical peak performance as:
-
- Fillrate:
- 8 pixels per clock = 4.8 GPix/s
- That's 2314 complete 1080p frames per second!
- Texture rate:
- 8 bilinear texels per clock = 4.8 GTex/s
- That's 38 bilinear filtered texture lookups per pixel for 1080p @ 60 FPS!
- Arithmetic rate:
- 17 FP32 FLOPS per pipe per core = 163 FP32 GFLOPS
- That's 1311 FLOPS per pixel for 1080p @ 60 FPS!
- Band
- 256-bits of memory access per clock = 19.2GB/s read and write bandwidth1.
- That's 154 bytes per pixel for 1080p @ 60 FPS!
- Fillrate:
带宽看上去比苹果小些哦。。。
他还说。。。。compute shader 和vertex shader 行为是一致的。。。interesting 把顶点看成cs的一维数据
BIFROST
The Execution Engines: Arithmetic Processing
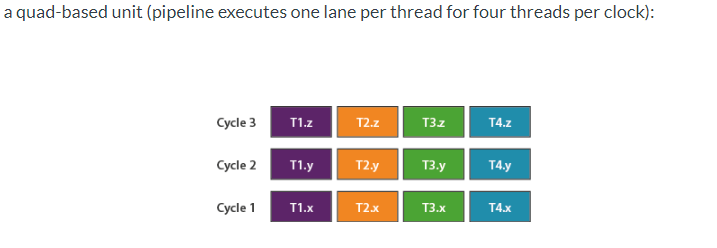
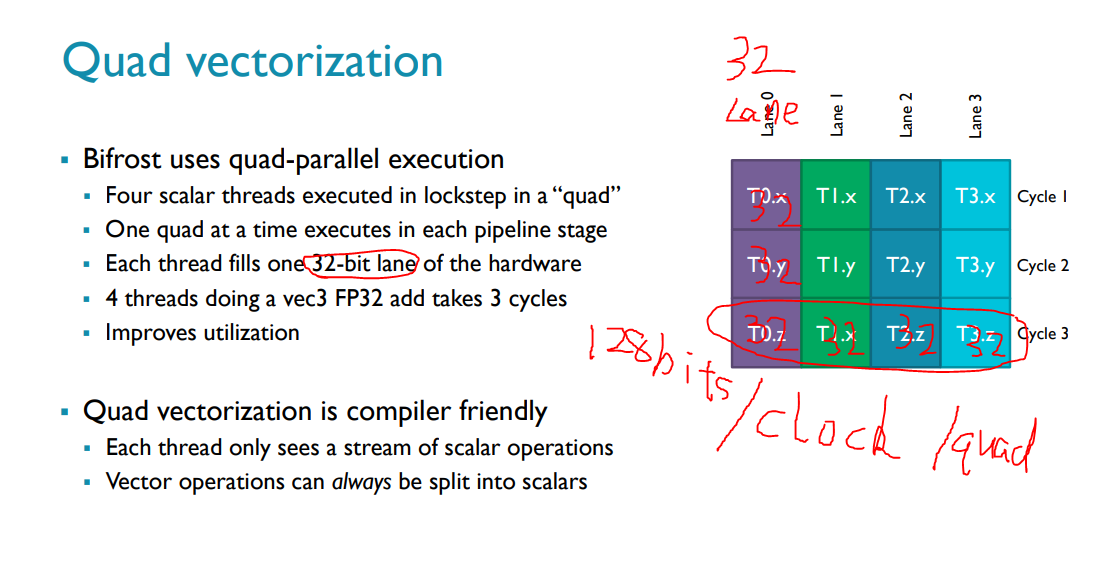
这种quardthread 更好的并行 T0 T1 T2 T3
一个quard 128bits 一个clock 就是横着一排
无论vector几都可以就这样往上排
=========
quad对应warp
是一组thread 4个一组这里叫quad
=======
The Execution Engines: Thread State
ZS/Blend unit
所有tile memory access 在这里
- https://www.khronos.org/registry/gles/extensions/EXT/EXT_shader_pixel_local_storage.txt
- https://www.khronos.org/registry/gles/extensions/ARM/ARM_shader_framebuffer_fetch.txt
- and the merged sub-pass functionality in Vulkan.
Varying unit
varying interpolator
插值用的 varying的access在load store unit(LS pipe) 它有cache
128bits/quard/clock
fp16 vector4 一个quard需要2clock (16x4=)
Load store unit
vertex attribute fetch,
varying fetch,
buffer accesses,
and thread stack accesses.
他有一个16K L1cache 公用L2cache
64bytes cache line/clock
quard thread 128bits 被优化到一个clock(4thread)
bifrost这里 把对memory 的访问分成三个units
load/store cache access, varying interpolation, tile-buffer accesses
midgard 这里就一个 unit
这种改变 增加了 三部分的并行 减小资源竞争 缓解LSpipe压力
texture unit --16K L1cache /core, 公用L2 ,双线性一个clock/texel
三线性 2 clock/texel 因为 需要mipmap 两级bilinear filer
volumetric 3d texture 两倍cycle of 2d
16bits/color channel 需要更多cycles/pixel
but Bifrost 采样 depth16 和depth24时做了优化 1cycle/texel 比midgard快一倍
======================
