原文链接
1. 包的导入
import re
import math
import importlib
import spacy
import torch
import torch.nn as nn
from torch.autograd import Variable
!pip3 install https://github.com/explosion/spacy-models/releases/download/zh_core_web_sm-2.3.0/zh_core_web_sm-2.3.0.tar.gz
2. 使用 Spacy 构建分词器
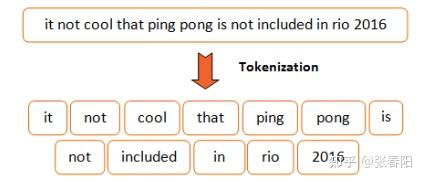
首先,我们要对输入的语句做分词,这里我使用 spacy 来完成这件事,你也可以选择你喜欢的工具来做。
class Tokenize(object):
def __init__(self, lang):
self.nlp = importlib.import_module(lang).load()
def tokenizer(self, sentence):
sentence = re.sub(
r"[\*\"“”\n\\…\+\-\/\=\(\)‘•:\[\]\|’\!;]", " ", str(sentence))
sentence = re.sub(r"[ ]+", " ", sentence)
sentence = re.sub(r"\!+", "!", sentence)
sentence = re.sub(r"\,+", ",", sentence)
sentence = re.sub(r"\?+", "?", sentence)
sentence = sentence.lower()
return [tok.text for tok in self.nlp.tokenizer(sentence) if tok.text != " "]
tokenize = Tokenize('zh_core_web_sm')
tokenize.tokenizer('你好,这里是中国。')
['你好', ',', '这里', '是', '中国', '。']
3. Input Embedding
3.1 Token Embedding
给语句分词后,我们就得到了一个个的 token,我们之前有说过,要对这些token做向量化的表示,这里我们使用 pytorch 中torch.nn.Embedding 让模型学习到这些向量。
class Embedding(nn.Module):
def __init__(self, vocab_size, d_model):
super().__init__()
self.d_model = d_model
self.embed = nn.Embedding(vocab_size, d_model)
def forward(self, x):
return self.embed(x)
3.2 Positional Encoder
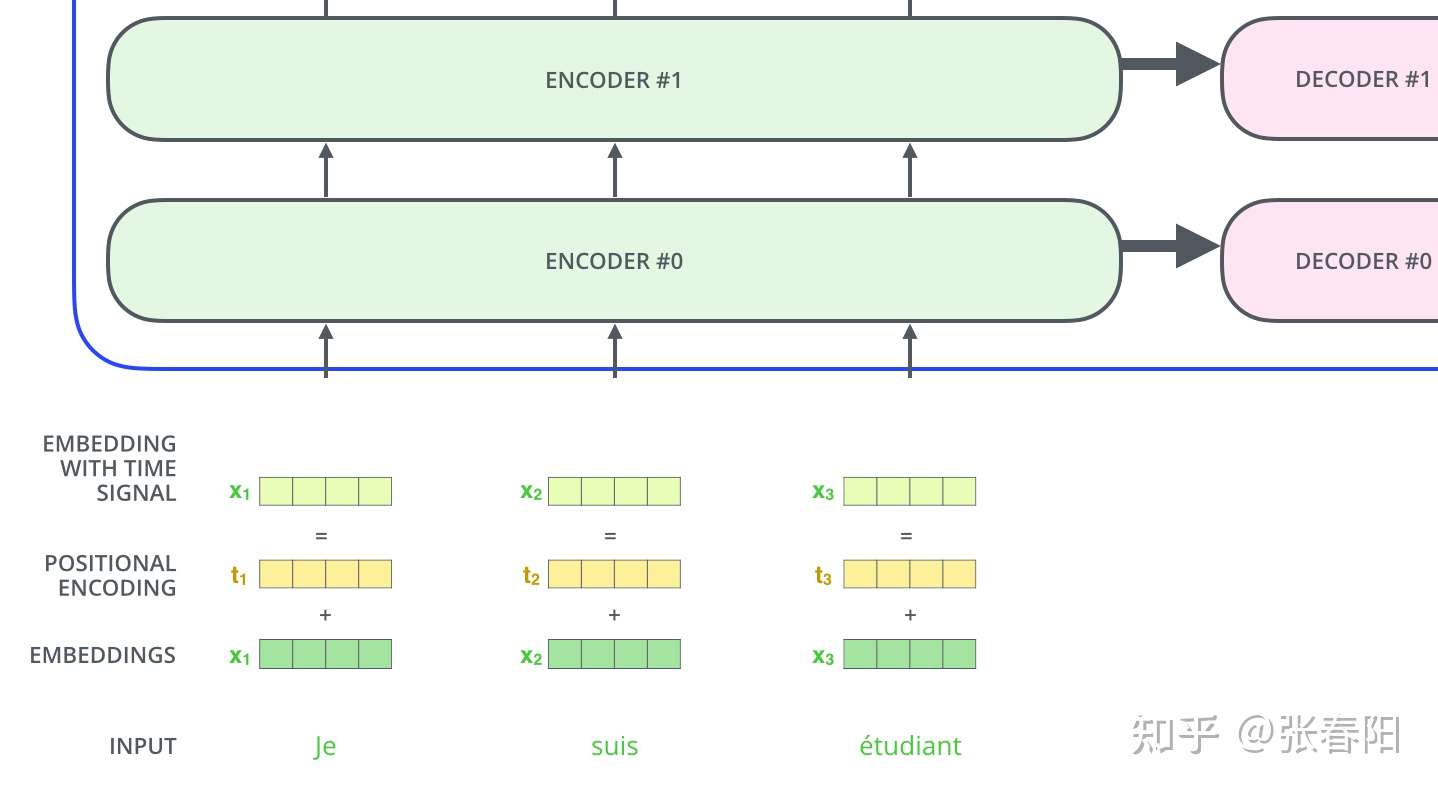
前文中,我们有说过,要把 token 在句子中的顺序也加入到模型中,让模型进行学习。这里我们使用的是 position encodings 的方法。
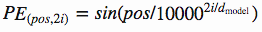
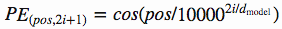
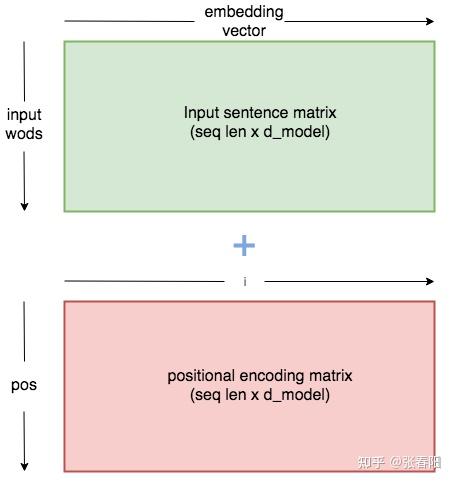
class PositionalEncoder(nn.Module):
def __init__(self, d_model, max_seq_len = 80):
super().__init__()
self.d_model = d_model
# 根据pos和i创建一个常量pe矩阵
pe = torch.zeros(max_seq_len, d_model)
for pos in range(max_seq_len):
for i in range(0, d_model, 2):
pe[pos, i] = \
math.sin(pos / (10000 ** ((2 * i)/d_model)))
pe[pos, i + 1] = \
math.cos(pos / (10000 ** ((2 * (i + 1))/d_model)))
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
# 让 embeddings vector 相对大一些
x = x * math.sqrt(self.d_model)
# 增加位置常量到 embedding 中
seq_len = x.size(1)
x = x + Variable(self.pe[:,:seq_len], \
requires_grad=False).cuda()
return x
4. Transformer Block
有了输入,我们接下来就要开始构建 Transformer Block 了,Transformer Block 主要是有以下4个部分构成的:
self-attention layer
normalization layer
feed forward layer
another normalization layer
它们之间使用残差网络进行连接,详细在上文同一个图下有描述,这里就不再赘述了。
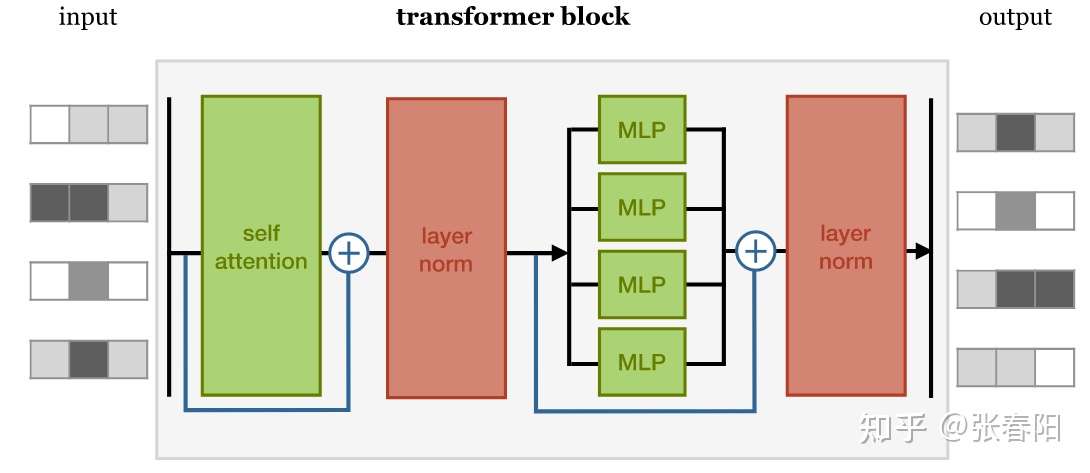
Attention 和 Self-attention 在前面的两篇文章中有详细的描述,不太了解的话,可以跳过去看看。
Transformer 一篇就够了(一): Self-attenstion
Transformer 一篇就够了(二): Transformer中的Self-attenstion
4.1 Attention

def attention(q, k, v, d_k, mask=None, dropout=None):
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)
# mask掉那些为了padding长度增加的token,让其通过softmax计算后为0
if mask is not None:
mask = mask.unsqueeze(1)
scores = scores.masked_fill(mask == 0, -1e9)
scores = F.softmax(scores, dim=-1)
if dropout is not None:
scores = dropout(scores)
output = torch.matmul(scores, v)
return output
这个 attention 的代码中,使用 mask 的机制,这里主要的意思是因为在去给文本做 batch化的过程中,需要序列都是等长的,不足的部分需要 padding。但是这些 padding 的部分,我们并不想在计算的过程中起作用,所以使用 mask 机制,将这些值设置成一个非常大的负值,这样才能让 softmax 后的结果为0。关于 mask 机制,在 Transformer 中有 attention、encoder 和 decoder 中,有不同的应用,我会在后面的文章中进行解释。

4.2 MultiHeadAttention
多头的注意力机制,用来识别数据之间的不同联系,前文中的第二篇也已经聊过了。
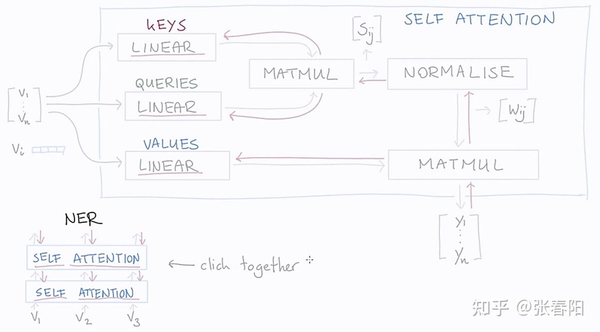
class MultiHeadAttention(nn.Module):
def __init__(self, heads, d_model, dropout = 0.1):
super().__init__()
self.d_model = d_model
self.d_k = d_model // heads
self.h = heads
self.q_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self.out = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
bs = q.size(0)
# perform linear operation and split into N heads
k = self.k_linear(k).view(bs, -1, self.h, self.d_k)
q = self.q_linear(q).view(bs, -1, self.h, self.d_k)
v = self.v_linear(v).view(bs, -1, self.h, self.d_k)
# transpose to get dimensions bs * N * sl * d_model
k = k.transpose(1,2)
q = q.transpose(1,2)
v = v.transpose(1,2)
# calculate attention using function we will define next
scores = attention(q, k, v, self.d_k, mask, self.dropout)
# concatenate heads and put through final linear layer
concat = scores.transpose(1,2).contiguous()\
.view(bs, -1, self.d_model)
output = self.out(concat)
return output
4.3 Norm Layer
这里使用 Layer Norm 来使得梯度更加的平稳,关于为什么选择 Layer Norm 而不是选择其他的方法,有篇论文对此做了一些研究,Rethinking Batch Normalization in Transformers,对这个有兴趣的可以看看这篇文章。
class NormLayer(nn.Module):
def __init__(self, d_model, eps = 1e-6):
super().__init__()
self.size = d_model
# create two learnable parameters to calibrate normalisation
self.alpha = nn.Parameter(torch.ones(self.size))
self.bias = nn.Parameter(torch.zeros(self.size))
self.eps = eps
def forward(self, x):
norm = self.alpha * (x - x.mean(dim=-1, keepdim=True)) \
/ (x.std(dim=-1, keepdim=True) + self.eps) + self.bias
return norm
4.4 Feed Forward Layer
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff=2048, dropout = 0.1):
super().__init__()
# We set d_ff as a default to 2048
self.linear_1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear_2 = nn.Linear(d_ff, d_model)
def forward(self, x):
x = self.dropout(F.relu(self.linear_1(x)))
x = self.linear_2(x)
5. Encoder
Encoder 就是将上面讲解的内容,按照下图堆叠起来,完成将源编码到中间编码的转换。
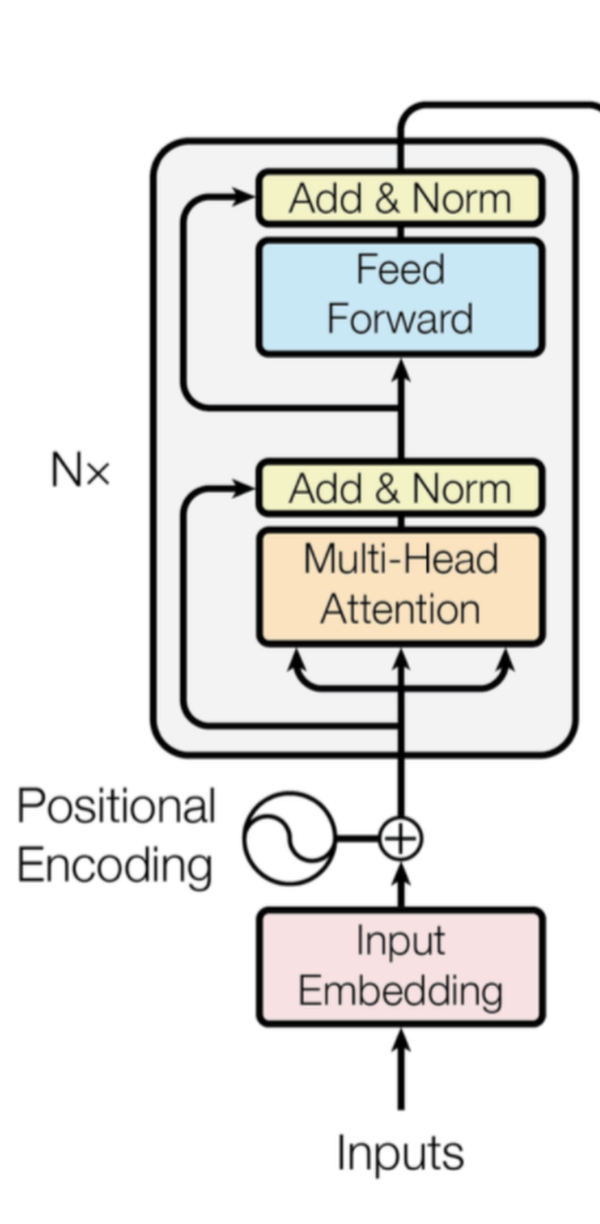
def get_clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
class Encoder(nn.Module):
def __init__(self, vocab_size, d_model, N, heads, dropout):
super().__init__()
self.N = N
self.embed = Embedder(vocab_size, d_model)
self.pe = PositionalEncoder(d_model, dropout=dropout)
self.layers = get_clones(EncoderLayer(d_model, heads, dropout), N)
self.norm = Norm(d_model)
def forward(self, src, mask):
x = self.embed(src)
x = self.pe(x)
for i in range(self.N):
x = self.layers[i](x, mask)
return self.norm(x)
6. Decoder
Decoder部分和 Encoder 的部分非常的相似,它主要是把 Encoder 生成的中间编码,转换为目标编码。后面我会在具体的任务中,来分析它和 Encoder 的不同。
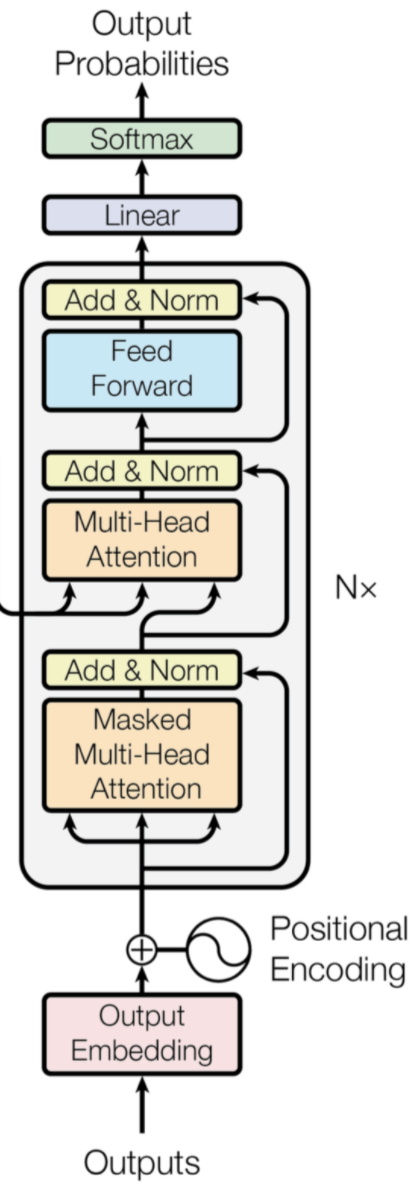
class Decoder(nn.Module):
def __init__(self, vocab_size, d_model, N, heads, dropout):
super().__init__()
self.N = N
self.embed = Embedder(vocab_size, d_model)
self.pe = PositionalEncoder(d_model, dropout=dropout)
self.layers = get_clones(DecoderLayer(d_model, heads, dropout), N)
self.norm = Norm(d_model)
def forward(self, trg, e_outputs, src_mask, trg_mask):
x = self.embed(trg)
x = self.pe(x)
for i in range(self.N):
x = self.layers[i](x, e_outputs, src_mask, trg_mask)
return self.norm(x)
7. Transformer
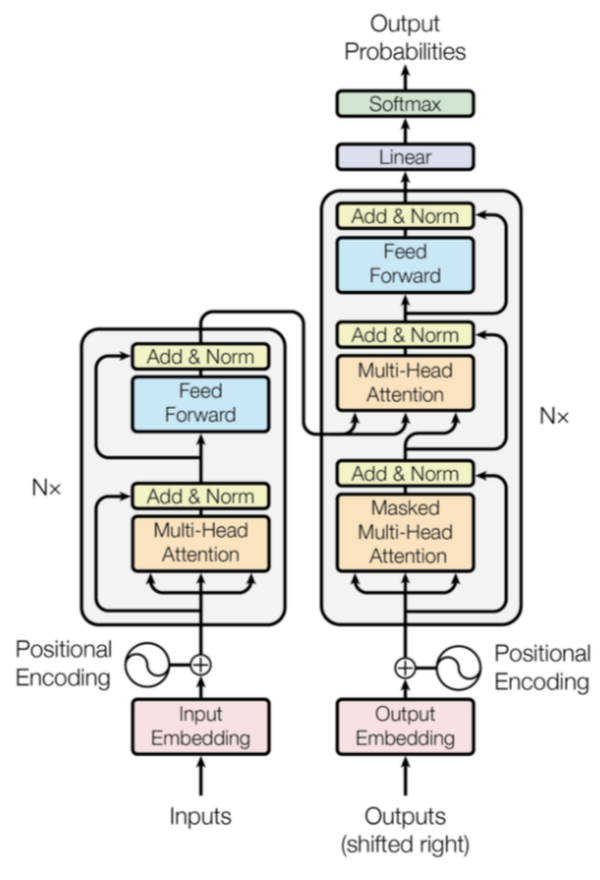
class Transformer(nn.Module):
def __init__(self, src_vocab, trg_vocab, d_model, N, heads, dropout):
super().__init__()
self.encoder = Encoder(src_vocab, d_model, N, heads, dropout)
self.decoder = Decoder(trg_vocab, d_model, N, heads, dropout)
self.out = nn.Linear(d_model, trg_vocab)
def forward(self, src, trg, src_mask, trg_mask):
e_outputs = self.encoder(src, src_mask)
d_output = self.decoder(trg, e_outputs, src_mask, trg_mask)
output = self.out(d_output)
return output