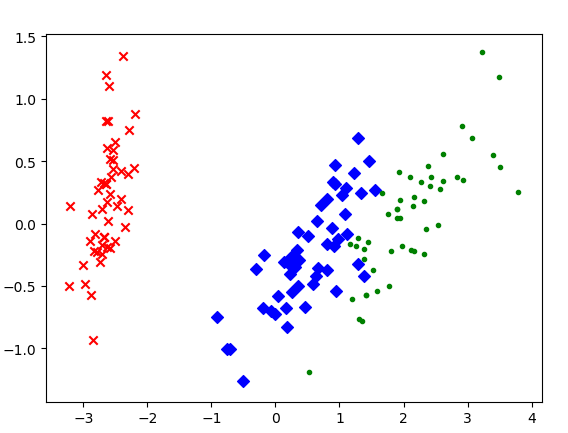
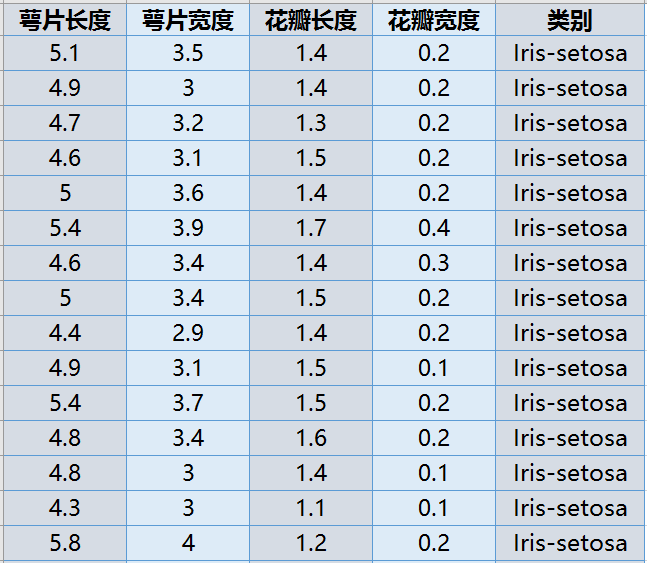
使用PCA方法对高维的鸢尾花数据(4维3类样本)进行降维分类,部分鸢尾花数据集如下:


#coding=utf-8 import matplotlib.pyplot as plt from sklearn.decomposition import PCA from sklearn.datasets import load_iris data = load_iris()#以字典形式加载鸢尾花数据集 y = data.target #使用y表示数据集中的标签 x = data.data #使用x表示数据集中的属性数据 #使用PCA 算法,设置降维后主成分数目为 2 #print(x,' ', y) pca = PCA(n_components=2) #对原始数据进行降维,保存在 reduced_X 中 reduced_X = pca.fit_transform(x) red_x, red_y = [], [] blue_x, blue_y = [], [] green_x, green_y = [], [] for i in range(len(reduced_X)): #标签为0时,2维标签数据保存到列表red_x,red_y中 if y[i] == 0: red_x.append(reduced_X[i][0]) red_y.append(reduced_X[i][1]) elif y[i] == 1: blue_x.append(reduced_X[i][0]) blue_y.append(reduced_X[i][1]) else: green_x.append(reduced_X[i][0]) green_y.append(reduced_X[i][1]) #第一、二、三类数据点可视化 plt.scatter(red_x, red_y, c='r', marker='x') plt.scatter(blue_x, blue_y, c='b', marker='D') plt.scatter(green_x, green_y, c='g', marker='.') plt.show()
结果如下: