1、
索引就是在数据库上创建的一个数据结构,在给某一个字段创建索引后,在根据该字段进行查询的时候会在这个数据结构中进行查询,以提高查询速度。索引通常是B树、B+树、B-树这种数据结构。比如对于一条查询语句:select * from order where price == 9,最简单也是最耗时的方法就是对price一条一条的进行查询,找出那些等于9的记录,而如果给price加上索引的话,就可以使用索引来快速的查找记录。例如使用下面这个简单的B树结构的索引来查找9,从根节点开始,只需要比较三次就找到它了,因为索引上保存了所在记录的指针,所以可以方便的找到所在记录的其他需要的值(也有的说是索引上保存了对应的主键值,使用这个主键值通过聚集索引来查找需要的数据)。
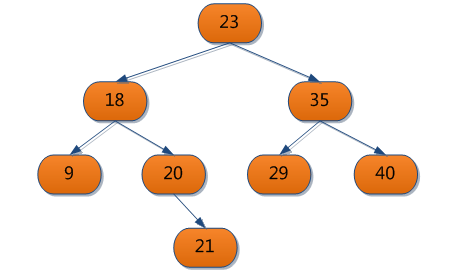
2、
我们平时建表的时候都会为表加上主键, 在某些关系数据库中, 如果建表时不指定主键,数据库会拒绝建表的语句执行。 事实上,一个没加主键的表,它的数据是无序的放置在磁盘存储器上,一行一行的排列的很整齐, 跟我们认知中的“表”很接近。如果给表加上了主键,那么表在磁盘上的存储结构就由整齐排列的结构转变成了树状结构,如下图所示,换句话说,就是整个表就变成了一个索引。没错, 再说一遍, 整个表变成了一个索引,也就是所谓的”聚集索引“。这就是为什么一个表中只能有一个主键, 即一个表中只能有一个“聚集索引”,因为主键的作用就是把 [表] 的数据格式转换成「索引(平衡树)」的格式放置。除了主键所使用的聚集索引外,我们平时经常提起和使用的常规索引都是非聚集索引。

3、
我们在前面了解到索引的结构是B树,当树在增加、删除的时候,会触发页的拆分或合并,这种频繁的操作会产生索引碎片,造成索引不连续,当索引碎片曾多时,是会影响查询效率的。因此要定期的清理索引碎片,一般的方法就是重建索引。
4、
使用create index来创建索引,格式为:create index 索引名 on 表名(字段名):
create index pub_id_idx on titles([pub_id]);--在表titles中pub_id列上建立索引,索引名为pub_id_idx
如果想要创建唯一索引(索引所在的字段不能有重复的值)的话使用create unique index:
create unique index title_id_idx on titles([title_id]);--建立值唯一索引
索引中数据默认是升序排列的(所以查询得到的数据也是升序排列的),如果想要指定降序则在字段名后加desc:
create index price_idx on titles([price] desc);--建立降序索引
使用drop index来删除索引:
drop index titles.price_idx;--删除索引
如果索引建立的字段就是select中需要的字段的话(比如下面的UserName字段),那么就不需要去数据库表中读取select需要的数据了,因为可以直接从索引中读到数据,这种索引又称为覆盖索引。
create index name_idx on User([UserName]);
select UserName from User where UserName = 'Rain';
一个索引还可以建在两个或多个字段之上, 此时这两个字段的内容都会被同步至索引之中,这称为复合索引或组合索引。当一个查询会有多个查询条件的时候可以建立复合索引:
create index name_age_idx on User([UserName], [Age]);
Select UserName from [User] where UserName='Ryan' and Age=12;
create index price_pages_idx on titles([price], [pages] desc);
select [book_name], [price], [pages] from titles order by [price], [pages] desc;--按price升序排序,若price相等,再按pages降序排序
5、
为表设置索引付出的代价是:一是增加了数据库的存储空间,二是在插入、修改、删除数据时会额外花费一些时间,因为这时候索引也要随之变动。
一般我们应该在下面的字段上创建索引:
在查询非常频繁的列上。
在经常需要排序的列上,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
在经常需要根据范围进行搜索的列上,因为索引已经排序,其指定的范围是连续的。
在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度。
不应该创建索引的字段:
当修改性能要求远高于检索性能要求时,不应该创建索引。
尽量在唯一性高的字段上创建索引,不要在性别这种唯一性很低的字段上创建索引。
建立索引的字段不应该太大,最好是数值,对于那些定义为text, image和bit数据类型的列不应该增加索引,这是因为,这些列的数据量要么相当大,要么取值相当少。
转载及参考出处:
http://www.cnblogs.com/anding/p/3254674.html
http://www.cnblogs.com/aspwebchh/p/6652855.html
http://blog.csdn.net/weiliangliang111/article/details/51333169
http://blog.csdn.net/kennyrose/article/details/7532032