Redis共有五种数据类型的键:字符串、哈希(散列)、列表、集合、有序集合。前面说过,Redis存储中没有整形类型。
1、字符串
字符串类型是其它4种类型的基础,如列表类型实际上是以列表的形式组织的字符串。字符串类型还可以存储二进制数据、JSON化的对象、图片。
相关的命令有 SET/GET、INCR、DECR(类似INCR,不过是递减)。比如我们要存储一篇文章的数据,有标题、正文、发布时间等内容,我们可以将文章各个内容使用一个字符串键类型来存储,也可以将文章的多个内存存到一个字符串键类型来存储。比如我们可以使用序列化方法(如JS中的JSON.stringify)将这些元素转换成一个字符串,获取文章的时候使用反序列化方法来解析文章的各个内容:
writingID = INCR writing.ID //每增加一篇文章,就使用INCR命令使writing.ID加一,所以writing.ID可以作为文章的ID SET writing : writingID:content strSerializedContent //将序列化后的文章内容保存到一个字符串类型的键中 //=========================================================================== strSerializedContent = GET writing : writingID:content //获取序列化的文章内容 pageView = INCR writing : writingID:page.view; //递增文章的访问数量
因为字符串类型键可以存储二进制数据,所以也可以使用MessagePack将文章内容序列化成二进制数据后保存。MessagePack转换后的数据类似JSON,但它在存储时做了很多优化,使用二进制数据,比JSON数据更小、更快。JSON中也可以使用二进制数据,比如JSON中也可以序列化图片数据 (使用base64编码)。而对于rpc序列化需求,使用protobuf会比MessagePack性能更高。
其它的命令有:GETSET:获得键的旧值并设置键的新值,没有旧值的话返回nil。如GETSET foo 100。
INCRBY / INCRBYFLOAT:增加指定的整数/浮点数,如INCRBY key -2。
APPEND: 向尾部追加值, 如APPEND foo "hello"。
STRLEN:获取字符串长度,如 STRLEN foo;
MGET/MSET:同时设置/获得多个键,如 MSET ke1 100 key2 200.
GETBIT / SETBIT:获得/设置指定位置二进制值,如SETBIT foo 5 0.
BITCOUNT: 获得值是1的二进制位数
BITOP: 进行AND、OR、XOR、NOT位运算,如BITOP OR res foo1 foo2(运算结果放到键res中)。
BITPOS: 获得0或1出现的第一个位置,如BITPOS foo 1。
利用位操作可以非常紧凑的存储布尔值,比如记录100万个用户性别的话,只需要100多K的空间,而且GETBIT和SETBIT的时间复杂度都是O(1),所以读取和设置二进制位的性能很高。
2、哈希(散列)
散列是一种字典类型,即map类型,而且map的值类型只能是字符串(列表、集合、有序集合的元素类型同样只能是字符串),添加,删除,查找元素的复杂度都是 O(1)。一个map最多能存储232 - 1 个键值对。
相关的命令有:
HSET/HGET: 赋值/取值,如 HSET car price 100000。HSET的时候,如果是插入(字段不存在)的话,返回1,更新(字段已存在)的话,返回0。
HMSET/HMGET: 多个字段赋值/取值,如 HSET car price 100000 name BMW。
HGETALL: 获得所有字段,如 HGETALL car。
HEXISTS:判断指定字段是否存在,存在返回1,否则返回0,如 HEXISTS car colour。
HSETNX:字段不存在时才赋值。
HINCRBY: 类似INCRBY,增加指定字段值的数值。
HDEL: 删除指定字段。
HKEYS/HVALS: 获得所有的字段名/字段值,如 HKEYS car。
HLEN:获得字段数量,如HLEN car。
3、列表
列表即list类型,其内部是一个双向链表,所以向列表两端添加元素的时间复杂度为O(1),获取越接近两端的元素速度越快,查找元素、向指定元素前/后插入元素的话时间复杂度为O(n)。一个list也是最多能存储232 - 1 个元素。
相关的命令:
LPUSH/RPUSH:向列表的左端/右端添加元素,支持添加多个元素,如LPUSH numbers 1 2。
LPOP/RPOP:从列表左边/右边删除一个元素并返回删除的元素值,如LPOP numbers。
LSET/LINDEX:设置/获得指定索引的值,如 LSET numbers 1 5,LINDEX numbers 1,LINDEX numbers -1为获得列表倒数第一个元素(最右边的第一个数),LINDEX numbers -2为获得倒数第二个元素。
LINSERT:向列表指定元素前/后(BEFORE/AFTER)插入元素,返回插入后列表的大小,如LINSERT numbers AFTER 7 3为向元素值为7的后面插入3。
LLEN:获得列表的元素个数。
LRANGE:获得列表指定范围的值,如LRANGE numbers 0 2表示获取前三个元素,注意列表的0位置的元素指定是最左边开始的元素。负数表示最右边开始的第几个数,比如LRANGE numbers 0 -1 表示获得从第一位到右边开始第一位的元素,即为获得所有元素。
LREM:删除列表中指定的元素,如 LREM numbers 2 5 为删除从左边开始前两个值为5的元素,LREM numbers -2 5 为删除从右边开始前两个值为5的元素,LREM numbers 0 5 为删除所有值为5的元素。
LTRIM:删除指定范围之外的所有元素,如LTRIM numbers 0 1。
RPOPLPUSH:从一个列表的最右边弹出一个元素,放到另一个列表的最左边,并返回这个元素的值,如RPOPLPUSH numbers1 numbers2。其中两个列表可以是同一个列表,利用这一特性,使用RPOPLPUSH命令可以不断的将队尾元素移到队首, 比如我们现在要对多个网站进行不间断的轮询监控,即从第一个网站到最后一个网站检查完后,再从第一个网站开始检测,那么就可以将这些网站放到一个队列中,然后反复调用RPOPLPUSH获得网站后进行检测处理,而且其它客户端还可以不断的向这个队列添加新的网站以供我们处理。
4、集合
集合即set类型,由于set相当于是值为空的map,所以向集合中添加、删除元素,判断某个元素是否存在的查找等操作的时间复杂度为O(1)。一个set也是最多能存储232 - 1 个元素。
对应的命令有:
SADD/SREM:增加/删除一个或多个元素,返回增加或删除的个数,如SADD foo a。
SISMEMBER:判断元素是否在集合中,如SISMEMBER foo a。
SMEMBERS:获得所有元素,如SMEMBERS foo。
SCARD:获元素个数,如SCARD foo。
SDIFF/SINTER/SUNION:求差集/合集/并集,如SDIFF foo1 foo2 表示获得foo1中所有元素,但不包含在foo2中也存在的元素。
SDIFFSTORE/SINTERSTORE/SUNIONSTORE:求差集/合集/并集后,将结果保存在一个键中。
SRANDMEMBER:从集合中随机获得一个元素,如SRANDMEMBER foo表示随机获取一个元素,SRANDMEMBER foo 2表示随机获得两个值不重复的元素,SRANDMEMBER foo -2表示随机获得两个值可能重复的元素。
SPOP:随机弹出一个元素,如SPOP foo。
5、有序集合
有序集合即sorted set,它使用set和跳跃表(skip list)实现,其元素增加了一个称为“分数”的属性,有序集合根据这个分数大小来对元素排序,默认是升序,而且允许出现元素值相同的元素(分数值必然不同)。添加和删除都需要修改skiplist,所以复杂度为O(log(n)),查找元素的话直接使用的hash,其复杂度为O(1)。当有序集合大小小于64的时候,其实是采用的zip list的设计,其时间复杂度为O(n)。
相关命令:
ZADD:增加或更新元素的分数,返回新增元素的个数(不包含更新的个数)。如ZADD foo 90 tom 100 leon为增加tom和leon两个元素,其分数分别为90和100。分数还可以是浮点类型(+inf表示正无穷,-inf表示负无穷)。
ZSCORE:获得元素的分数,如ZSCORE foo tom。
ZINCRBY:增加元素的分数,返回增加后的分数,如ZINCRBY foo 10 tom为给tom元素增加10分。
ZCARD:获得集合中元素的数量,如ZCARD foo。
ZCOUNT:获得指定分数范围内的元素个数,如ZCOUNT foo 60 100为获得分数为60到100(包含)元素个数,ZCOUNT foo (60 +inf。
ZREM:删除一个或多个元素,如ZREM foo tom leon。
ZREMRANGEBYRANK:删除指定排序范围的元素,如ZREMRANGEBYRANK foo 0 2为删除前3个元素。
ZREMRANGEBYSCORE:删除指定分数范围内的元素,如ZREMRANGEBYSCORE foo 60 100。
ZRANK:获得指定元素在集合内的排序位置,所以分数最小的元素排名为0,如ZRANK foo tom。
ZREVRANK:与ZRANK不同的是从右边开始计数,所以分数最大的元素排名为0。
ZRANGE:获得指定范围的元素,如ZRANGE foo 0 2为获得前三个元素,ZRANGE foo 0 -1为获得所有元素,ZRANGE foo -3 -1表示获得从集合尾端开始的三个元素,ZRANGE foo 0 -1 WITHSCORES为除了获得元素外还包括其分数。ZRANGE命令的时间复杂度为O(log(n) + m) (m为命令返回元素的个数)。
ZREVRANGE:与ZRANGE不同的是返回的结果是倒序排序的,如ZREVRANGE foo 0 1 为获得最后的2个元素,且倒序排列, ZREVRANGE foo 0 -1为获得所有元素,且倒序排列。
ZRANGEBYSCORE:获得指定分数范围内的元素,如ZRANGEBYSCORE foo 80 100为获得分数值在80和100中的所有元素,即[80, 100],ZRANGEBYSCORE foo 80 (100 为获得分数值在80和100中的所有元素,但不包括100,即[80, 100),ZRANGEBYSCORE foo 80 +inf表示获得分数值在80及其以上的所有元素,ZRANGEBYSCORE foo 80 100 WITHSCORE表示获得分数值在80和100中的所有元素及其分数。
ZRANGEBYSCORE...LIMIT...:获得指定分数范围内,指定个数的元素,如 ZRANGEBYSCORE foo 60 +inf LIMIT 1 3 为获得60分(包含)以上,从第二个人开始的前三个人。ZRANGEBYSCORE foo -inf 100 LIMIT 0 3 为获得最小分到100分的范围内,从第一个人开始的前三个人。
ZREVRANGEBYSCORE:与ZRANGEBYSCORE不同的是返回的结果是按照分数倒序排序的,如ZREVRANGEBYSCORE foo +inf -inf 为获得所有元素,并且倒序排序。ZREVRANGEBYSCORE foo 100 -inf LIMIT 0 3为获得分数100以下的,从右开始数第一个元素到第三个元素,倒序排列。
ZINTERSTORE:对两个有序集合的交集进行计算,如ZINTERSTORE setResult 5 set1 set2 AGGREGATE SUM为将set1和se2的交集元素的分数进行sum运算,结果保存在setResult中,其中的5是set1或set2的大小(取最大的),,AGGREGATE SUM可以省略。ZINTERSTORE setResult 5 set1 set2 AGGREGATE MIN/MAX 为将set1和se2的交集元素的取分数最小/大的到setResult。还可以设置每个集合的权重,每个集合在计算前元素的分数会先乘上该权重。
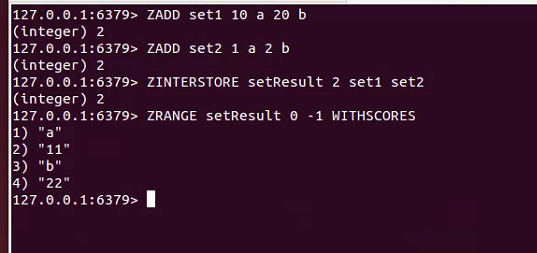
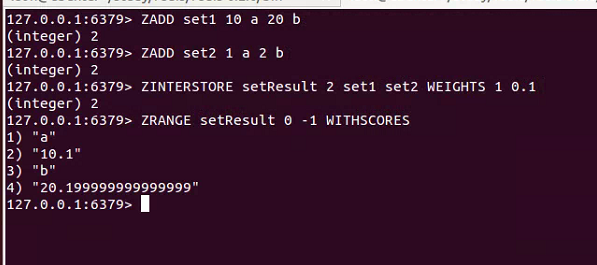
ZUNIONSTORE:对两个有序集合的并集进行计算。
软件中的查询功能经常有下拉列表提示,比如输入a的话列表就会按照匹配和字典顺序来展示ab、abc、ad,我们可以将下拉列表的内容的内容放到一个有序集合里,集合中所有元素的分数都为0,这样集合中元素都会按照字典顺序类排序。
软件中的在线好友列表可以通过集合的交集来实现:所有在线用户存在一个集合中,用户的所有好友存在一个集合中,两个集合的交集即为用户所有的在线好友。
6、内部编码方式
Redis中的键都是使用redisObject结构体保存的,如下所示,其中encoding为键的编码方式,即存储方式。每种数据类型都有两种编码方式,有的编码方式注重效率,有的编码方式注重节约空间,如散列类型当其元素很少的时候,Redis会使用一种更为紧凑但性能稍差(时间复杂度O(n))的数据结构来保存。OBJECT ENCODING命令可以查看一个键的编码方式,如OBJECT ENCODING foo。
typedef struct redisObject { unsigned type:4; //键值数据类型,0 string/ 1 list/ 2 set/ 3 zset/ 4 hash unsigned notused:2; //未使用 unsigned encoding:4; //编码方式 unsigned lru:22; //最后一次使用此对象的时间等信息 int refcount; //该键值被引用的数量 void* ptr; //数据地址 }robj;
1) 字符串
①、ptr指向一个sdshdr类型的对象,所以SET foo 123的话,foo键占用的空间为sizeof(redisObject) + sizeof(sdshdr) + sizeof("123") 为27个字节。这种编码方式encoding值为REDIS_ENCODING_RAW。
struct sdshdr { int len; //字符串长度 int free; //buf中剩余空间 char buf[]; //字符串内容 };
②、ptr指向一个sdshdr类型的对象,而且这个sdshdr对象就保存在ptr的下一个地址,这种内存连续的保存方式可以使内存操作更加便利。当键值的内容不超过39个字节的时候Redis会采用这种方式保存,当对采用这种编码方式的键值修改的时候,Redis会将其转换为REDIS_ENCODING_RAW。这种编码方式encoding值为REDIS_ENCODING_EMBSTR。
③、ptr指向一个long类型,当键值可以使用一个64位有符号整数表示的时候,Redis会使用这种编码方式,如SET foo 123,foo键占用的空间为sizeof(redisObject) + sizeof(long)为16。encoding值为REDIS_ENCODING_INT。
redisObject中的refcount为该键值被引用的个数,这表示该键值是可以被共享的,如Redis启动后会预先创建10000个redisObject对象来分别保存0到9999,当我们使用这些数字的时候不必再额外创建,以节省内存。需要注意的是当通过配置文件修改了maxmemroy后,Redis就不会使用共享对象了。
2)散列
散列的编码方式也可以通过配置文件来设置:当散列中元素个数小于配置文件中hash-max-ziplist-entries参数值,且每个元素的key和value的长度都小于hash-max-ziplist-value参数值的时候,ptr指向的是一个压缩列表ziplist(REDIS_ENCODING_ZIPLIST),否则使用的是一个哈希表(REDIS_ENCODING_HT)。当使用哈希表的时候,key和value是字符串类型,所以也是使用redisObject来存储的,也会使用上面所说的内存优化方案。当使用ziplist的时候查找元素的时间复杂度为O(n),插入和删除的话需要移动后面元素的位置,时间复杂度最坏为O(n2)。
ziplist结构如下所示,其中的元素包含四个部分,第一部分保存前一个元素的大小以实现倒序查找,当前一个元素小于254个字节时占用1个字节,否则占用5个字节。第四部分为元素的值,如果元素可以转换成数字的话,那就会使用相应的数字类型来存储。当元素的大小小于等于63个字节的时候,第二部分的值为ZIP_STR_06B(二进制为00),占用2位的大小,第三部分占用大小为6位(可表示0-63),当元素的大小小于等于16383个字节时,第二部分的值为ZIP_STR_14B(二进制为01),占用2位的大小,第三部分占用14位(可表示0-16383),当元素的大小大于16383个字节时,第二部分的值为ZIP_STR_32B(二进制为1000 0000),占用8位一个字节,第三部分占用大小为32位四个字节(可表示0-2^32-1)。
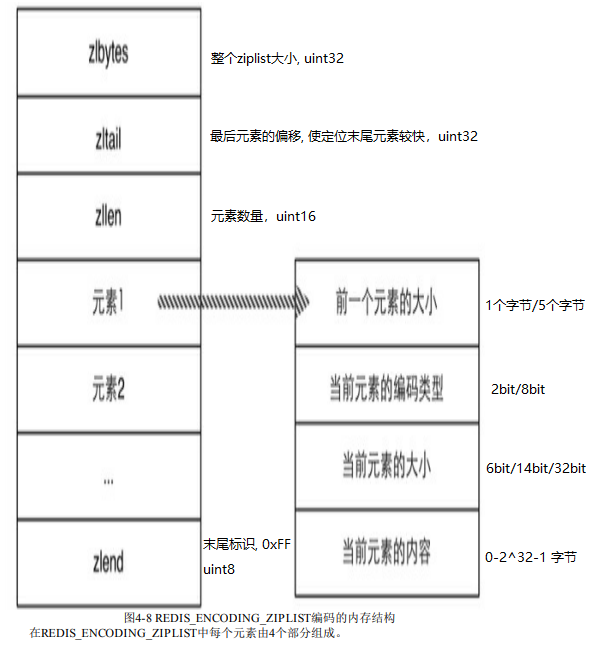
3)列表
同样可以通过配置文件的 hash-max-ziplist-entries和hash-max-ziplist-value来设置ptr指向一个linkdList或ziplist。linkdList下,链表中的的每个元素也是使用redisObject存储的,所以元素值会使用字符串键的优化方式。ziplist同散列中的一样,获取两端的元素较快。
最新版本的Redis中将quicklist代替了ziplist,它是linkedList和ziplist的结合体,如下所示,它将整个linkdList分成若干个ziplist,从而使添加删除列表元素的时候效率更高:
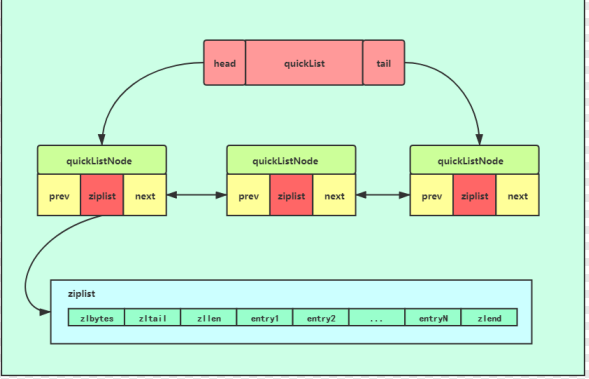
4)集合
当集合中所有元素都是整数且集合大小小于配置文件中set-max-inset-entries设置大小时候,ptr指向的是一个intset,否则编码使用hash。intset类似C++中的set一样是有序排列的,查找元素的时间复杂度为O(log2n),添加或者删除元素会调整后面元素的位置或长度,性能较差。
如下为intset的存储结构,默认encoding为INSET_ENC_INT16,表示使用两个字节来存储元素,2个字节占不下的时候再使用4个字节或8个字节来存储。当集合的存储结构使用hash后,即使以后集合中元素都变成了整数也不会再使用intset,否则每次删除的时候都要判断其它元素是否是整数,这样hash的删除效率就变成了O(n)。
typedef struct intset { uint32 encoding; uint32 length; uint8 contents[]; }intset;
5)有序集合
类似散列,有序集合也可以通过配置文件来定义使用REDIS_ENCODING_SKIPLIST和REDIS_ENCODING_ZIPLIST的时机。REDIS_ENCODING_SKIPLIST编码使用一个hash和一个skiplist,hash表为元素值和元素分数键值对,可以实现ZSCORE等命令的O(1)效率,skiplist有序存放元素分数和元素值的键值对,以实现有序集合中元素值按分数排序。使用REDIS_ENCODING_SKIPLIST编码的时候,元素的键值也是使用redisObject,所以元素值会使用字符串键的优化方式,元素的分数使用double保存。使用REDIS_ENCODING_ZIPLIST的时候,采用" ... 元素1的值 | 元素1的分数 | 元素2的值 | 元素2的分数 ..."的方式存储。