之前的章节,我们陆续的介绍了使用C#制作爬虫的基础知识,而且现在也应该比较了解如何制作一只简单的Web爬虫了。
本节,我们来做一个完整的爬虫系统,将之前的零散的东西串联起来,可以作为一个爬虫项目运作流程的初探,但实际项目中,还需要解决其他一些问题,我们后续章节也将继续深耕:)
先来看一下解决方案的整体结构: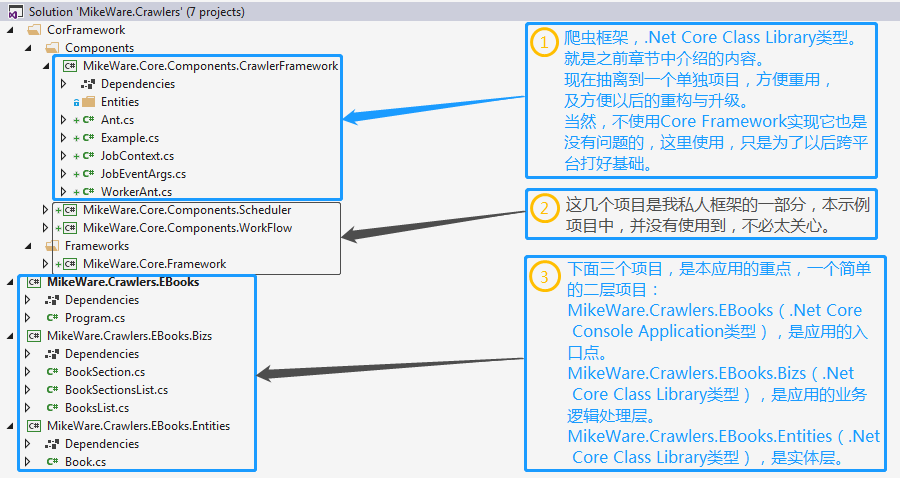
我们也希望我们的爬虫框架能够被应用到跨平台的项目中,所以,本项目采用了.Net Core Framework作为基础。
根据上图所示,项目结构还是很简单的。爬虫框架部分,与之前章节的内容并没有太大变动。本节主要是看一下在应用中,如何将一只小蚂蚁扩展到一群小蚂蚁。
本示例项目以采集某在线小说网站为例,特此对该小说网站说一声:如有得罪,敬请谅解、如有引流,敬请打赏:P
好了,步入正体,现来看看应用程序的入口(MikeWare.Crawler.EBooks)项目,是如何做的吧。


1 namespace MikeWare.Crawlers.EBooks 2 { 3 using MikeWare.Crawlers.EBooks.Bizs; 4 using MikeWare.Crawlers.EBooks.Entities; 5 using System; 6 7 class Program 8 { 9 static void Main(string[] args) 10 { 11 var lastUpdateTime = DateTime.MinValue; 12 13 BooksList.Start(1, lastUpdateTime); 14 15 Console.Read(); 16 } 17 } 18 }
这个项目很简单,就是用了项目初始的Program类,在Main方法中,构造了一个DateTime lastUpdateTime变量,然后就开始采集任务了。
关于lastUpdateTime变量,我们可以这么理解,就是在采集过程中,我们可能需要一遍又一遍的对数据源进行采集,以获取更新数据。在实际情境中,可能数据源的更新,并不是所有数据都在发生变化的,比如我们本例中的小说,小说的作者昨天写了一些章节,那么这些章节,在今天甚至这辈子都不会再发生变化了,所以,我们也没有必要每一次采集都将所有小说的章节都采集一遍,也就是我们只对有更新的小说感兴趣,那么如何区分新的数据与老的数据,这个要看数据源为我们提供了什么样的特征,从中寻找到一个或多个合适的特征来作为我们的标志位,本例呢,就是采用了小说的更新时间,这就是lastUpdateTime的由来,可以根据具体的情况,来自定义符合实际情况的标记位来达到采集增量的目的。
那么对于首次采集来讲,我们可能希望是将整个站点的所有小说都采集一遍,那么,这个时候,lastUpdateTime的初始值,就可以设定DateTime.MinValue,这样,即使再古老的小说,它的更新时间也不会早于这个标记位了,也就达到了采集全部小说的目的;那么对于再次采集,我们可以先统计上一次采集结果中,最近的更新时间,作为本次采集的lastUpdateTime。所以对于无论是首次采集还是再次采集来讲,逻辑可以合并为“获取上一次采集的最近更新时间”,而这个逻辑内部去判断,如果之前有采集记录,就返回最近的更新时间,如果没有,就返回DateTime.MinValue,这样就都统一起来了。
同时,本项目其实只是提供了一个采集任务的启动的触发点。我尽量将它作得很轻,这样可以方便移植,或许一个WinForm项目中的Button_Click事件或者一个WebApplication项目的Page_Load事件才是它的入口点,Anyway,Main方法中的内容,拷贝过去就好:)View部分暂不多说了。
接下来,我们简单介绍一下(MikeWare.Crawlers.EBooks.Entities)项目
1 namespace MikeWare.Crawlers.EBooks.Entities 2 { 3 using System; 4 using System.Collections.Generic; 5 6 public class Book 7 { 8 public int Id { get; set; } 9 public string Name { get; set; } 10 public string PhotoUrl { get; set; } 11 public Dictionary<int, string> Sections { get; set; } 12 public Dictionary<int, string> SectionContents { get; set; } 13 14 public string Author { get; set; } 15 public DateTime LastUpdateTime { get; set; } 16 } 17 }
这个项目也很简单,只提供了一个类(Book),这个类中,定义了一本书的ID、名字、封面图片的URL、作者、最近更新时间、章节内容等属性。用来描述一本书的基本特征。不过,我并没有采集一本书的评论及评分内容,一、数据源没有提供评论数据;二、我更希望实现我自己的评分评价系统,而不依赖于数据源的评分;这里只是想说明,实体的定义,是为了业务服务的,可以根据需要,去自定义;当然,如果希望数据完整,我们应该把评分等数据都采集过来做持久化,万一以后哪天又突然想用这部分数据了呢,再去重新采集一遍?呵呵……拍脑袋的事情总是防不胜防。
好了,接下来,开始介绍(MikeWare.Crawlers.EBooks.Bizs)项目
1 namespace MikeWare.Crawlers.EBooks.Bizs 2 { 3 using MikeWare.Core.Components.CrawlerFramework; 4 using System; 5 using System.Net; 6 using System.Text; 7 using System.Text.RegularExpressions; 8 using System.Threading; 9 using System.Threading.Tasks; 10 11 public class BooksList 12 { 13 private static Encoding encoding = new UTF8Encoding(false); 14 private static int total_page = -1; 15 private static Regex regex_list = new Regex(@"<li>[^<]+<div.*?更新:(?<updateTime>d+?-d+?-d+?)[^d].+?<a[^/]+?/Shtml(?<id>d+?).html.+?</li>", RegexOptions.Singleline); 16 private static Regex regex_page = new Regex(@"<div class=""tspage"">.+?<a href='/s/new/index_(?<totalPage>d+?).html'>尾页</a>.+?</div>", RegexOptions.Singleline); 17 18 public static void Start(int pageIndex, DateTime lastUpdateTime) 19 { 20 new WorkerAnt() 21 { 22 AntId = (uint)Math.Abs(DateTime.Now.ToString("yyyyMMddHHmmssfff").GetHashCode()), 23 OnJobStatusChanged = (sender, args) => 24 { 25 Console.WriteLine($"{args.EventAnt.AntId} said: {args.Context.JobName} entered status '{args.Context.JobStatus}'."); 26 switch (args.Context.JobStatus) 27 { 28 case TaskStatus.Created: 29 if (string.IsNullOrEmpty(args.Context.JobName)) 30 { 31 Console.WriteLine($"Can not execute a job with no name."); 32 args.Cancel = true; 33 } 34 else 35 Console.WriteLine($"{args.EventAnt.AntId} said: job {args.Context.JobName} created."); 36 break; 37 case TaskStatus.Running: 38 if (null != args.Context.Memory) 39 Console.WriteLine($"{args.EventAnt.AntId} said: {args.Context.JobName} already downloaded {args.Context.Memory.Length} bytes."); 40 break; 41 case TaskStatus.RanToCompletion: 42 if (null != args.Context.Buffer && 0 < args.Context.Buffer.Length) 43 Analize(args.Context.Buffer, pageIndex, lastUpdateTime); 44 if (null != args.Context.Watch) 45 Console.WriteLine("/* ********************** using {0}ms / request ******************** */" 46 + Environment.NewLine + Environment.NewLine, (args.Context.Watch.Elapsed.TotalMilliseconds / 100).ToString("000.00")); 47 break; 48 case TaskStatus.Faulted: 49 Console.WriteLine($"{args.EventAnt.AntId} said: job {args.Context.JobName} faulted because {args.Message}."); 50 break; 51 case TaskStatus.WaitingToRun: 52 case TaskStatus.WaitingForChildrenToComplete: 53 case TaskStatus.Canceled: 54 case TaskStatus.WaitingForActivation: 55 default:/* Do nothing on this even. */ 56 break; 57 } 58 }, 59 }.Work(new JobContext 60 { 61 JobName = "奇书网-最新电子书-列表", 62 Uri = $"http://www.xqishuta.com/s/new/index_{pageIndex}.html", 63 Method = WebRequestMethods.Http.Get, 64 }); 65 } 66 67 private static void Analize(byte[] data, int pageIndex, DateTime lastUpdateTime) 68 { 69 if (null == data || 0 == data.Length) 70 return; 71 72 var context = encoding.GetString(data); 73 var matches = regex_list.Matches(context); 74 if (null != matches && 0 < matches.Count) 75 { 76 var update_time = DateTime.MinValue; 77 var id = 0; 78 foreach (Match match in matches) 79 { 80 if (!DateTime.TryParse(match.Groups["updateTime"].Value, out update_time) 81 || !int.TryParse(match.Groups["id"].Value, out id)) continue; 82 83 if (update_time > lastUpdateTime) 84 { 85 Thread.Sleep(5); 86 BookSectionsList.Start(id); 87 } 88 else 89 return; 90 } 91 } 92 93 if (-1 == total_page) 94 { 95 var match = regex_page.Match(context); 96 if (null != match && match.Success && int.TryParse(match.Groups["totalPage"].Value, out total_page)) ; 97 98 } 99 100 if (pageIndex < total_page) 101 { 102 Thread.Sleep(5); 103 pageIndex++; 104 Start(pageIndex, lastUpdateTime); 105 } 106 } 107 } 108 }
这个逻辑处理类,实际上是整个采集任务的入口点,提供了几个私有变量和两个方法,我们挨个介绍一下:
// 提供了页面解析的编码设定; private static Encoding encoding = new UTF8Encoding(false); // 这个页面是一个可以翻页的列表页面,所以,我们有必要知道这个列表,一共有多少页; private static int total_page = -1; // 一个正则表达式,获取列表的每一项的数据; private static Regex regex_list = new Regex(@"……"); // 一个正则表达式,获取翻页中最后一页的页码的数据; private static Regex regex_page = new Regex(@"……");
这些变量被定义为私有静态变量,首先的考虑是当这个处理类被重复调用时,尽量避免不必要的内存分配。当然,像encoding这样的变量,可能整个站点都是统一的,没有必要在每个处理类中都单独声明一个,这里只是为了能够使每一个类尽量完整,免得大家在阅读的时候还要跳转到别的类去查看encoding的定义;
关于正则表达式,这里不做过多说明,不是本书的重点;
接下来,是本类中的Start方法,这个方法需要两个参数,一个是前面说过的lastUpdateTime,另一个就是Url中需要的页码:pageIndex;这个方法在View层被触发,开始启动了整个采集任务,View层传递过来的pageIndex为1;
case TaskStatus.RanToCompletion: if (null != args.Context.Buffer && 0 < args.Context.Buffer.Length) Analize(args.Context.Buffer, pageIndex, lastUpdateTime); if (null != args.Context.Watch) Console.WriteLine("/* ********************** using {0}ms / request ******************** */" + Environment.NewLine + Environment.NewLine, (args.Context.Watch.Elapsed.TotalMilliseconds / 100).ToString("000.00")); break;
上面代码段指示了,当任务完成时,调用了Analize(xxx,yyy,zzz)方法。
接下来,本类的另一个方法(Analize),它的声明如下:
private static void Analize(byte[] data, int pageIndex, DateTime lastUpdateTime)
这里需要说明的是第一个参数data,它是一个字节数组,我们为什么没有在采集完成时,直接将数据转化为文本然后传递给Analize方法?这里,我们需要分开两部分来看待,Start方法,我们可以看作是一个采集器,而Analize方法可以看作是一个分析器,采集器呢,本身不知道也不需要知道它采集的是个什么东西,它只管采集,数据尽管交给分析器去处理,这样任务单一;分析器呢,是针对某一个任务而定制的,比如这个列表页,我们的分析工作,就是针对列表页的特性进行分析,数据怎么抽取,流程怎么流转,这,可以说都是预知的,隐含的条件,就是它要分析的内容是文本,也是提前就已知的;那么,我们切换到另一个场景,如果我们采集的是一个图片或者压缩包文件,采集器硬要把它转换为文本,这种做法是错误的,而分析器,它是已经知道了它的目的,在分析处理的过程中,它的逻辑就是如何处理这样的文件,所以接收一个字节数组来做后续的处理,也是没有问题的。
这也是为什么要拆分为Start和Analize两个方法,两个方法合并到一起,都写在Start里行不行呢,肯定行啊,可是行是行,但是不好。因为我在这里,只是提出了采集器和分析器的概念,当面向更为复杂的业务时,还会有诸如存储器、调度器等等实际需要的组件。那么,都写在Start里?显然,不是一个很好的决策。
好了,我们继续来分析Analize方法的内部实现,逻辑也不算复杂,主要有两个分支:
- 当我们获取到小说列表了以后,就遍历列表,如果这部小说的最近更新时间符合我们的lastUpdateTime限制,则得到这部小说的Id,并调用BookSectionsList.Start(id),继而进行下一步的采集,否则,就返回了,不再继续采集后续小说及列表页面;
- 当列表页的页码仍小于总页码的时候,递增pageIndex,调用Start方法,进行翻页采集;
这就是BookList类的工作了,基本完成。
另外的两个类,工作原理与BookList的一致,由采集器与分析器组成:
- BookSectionsList:采集一部小说的章节列表;
- BookSection:采集具体到某一章节的内容;
OK,这样,我们就完成了一个简单的爬虫应用,预览一下效果总是迫不及待的。
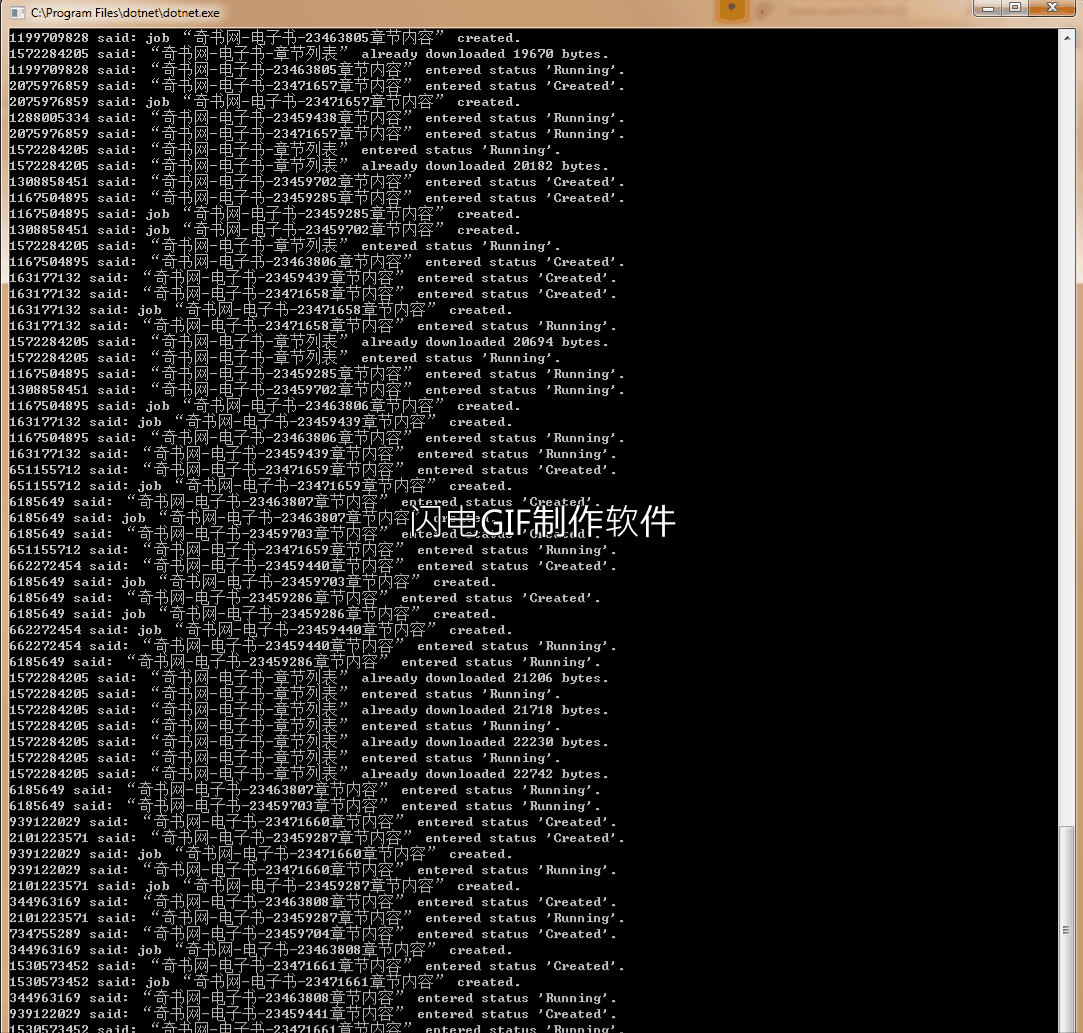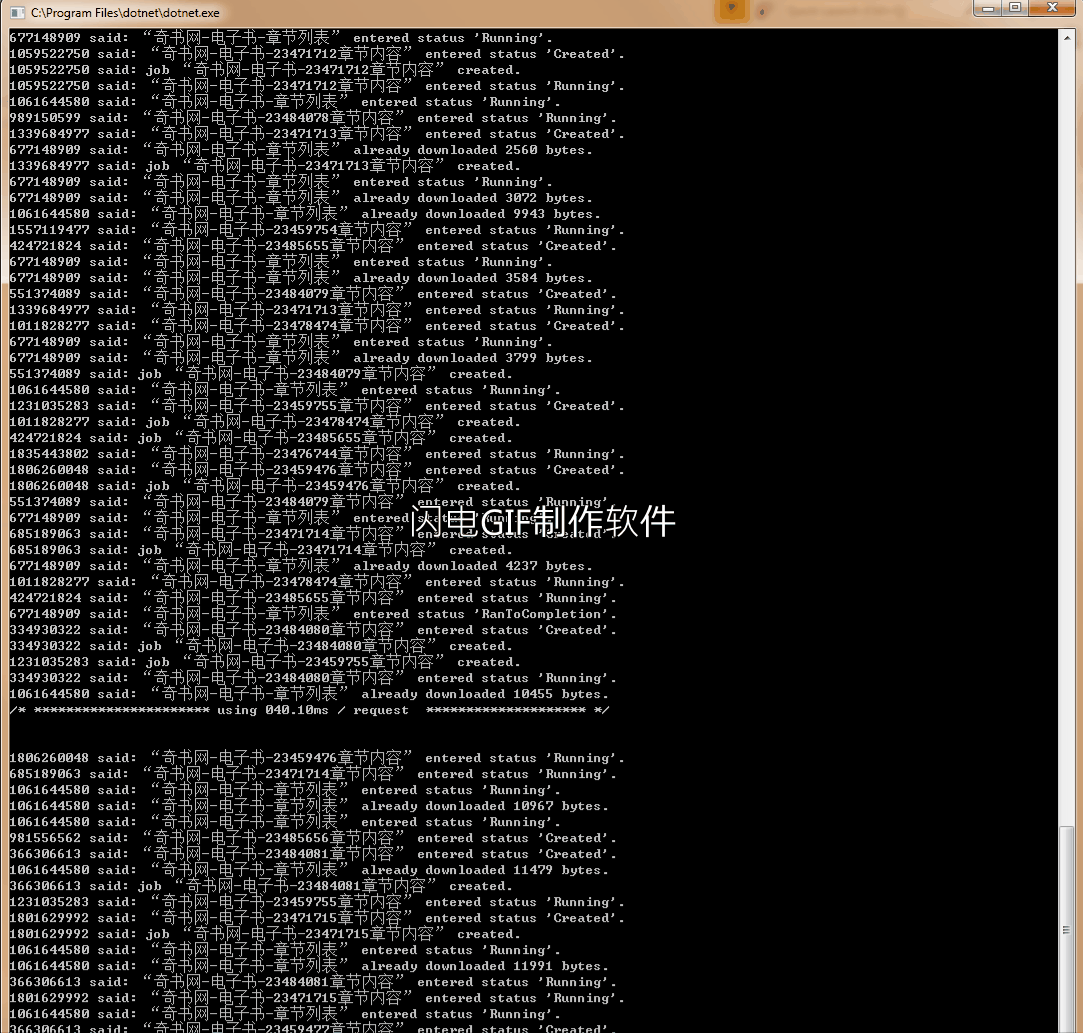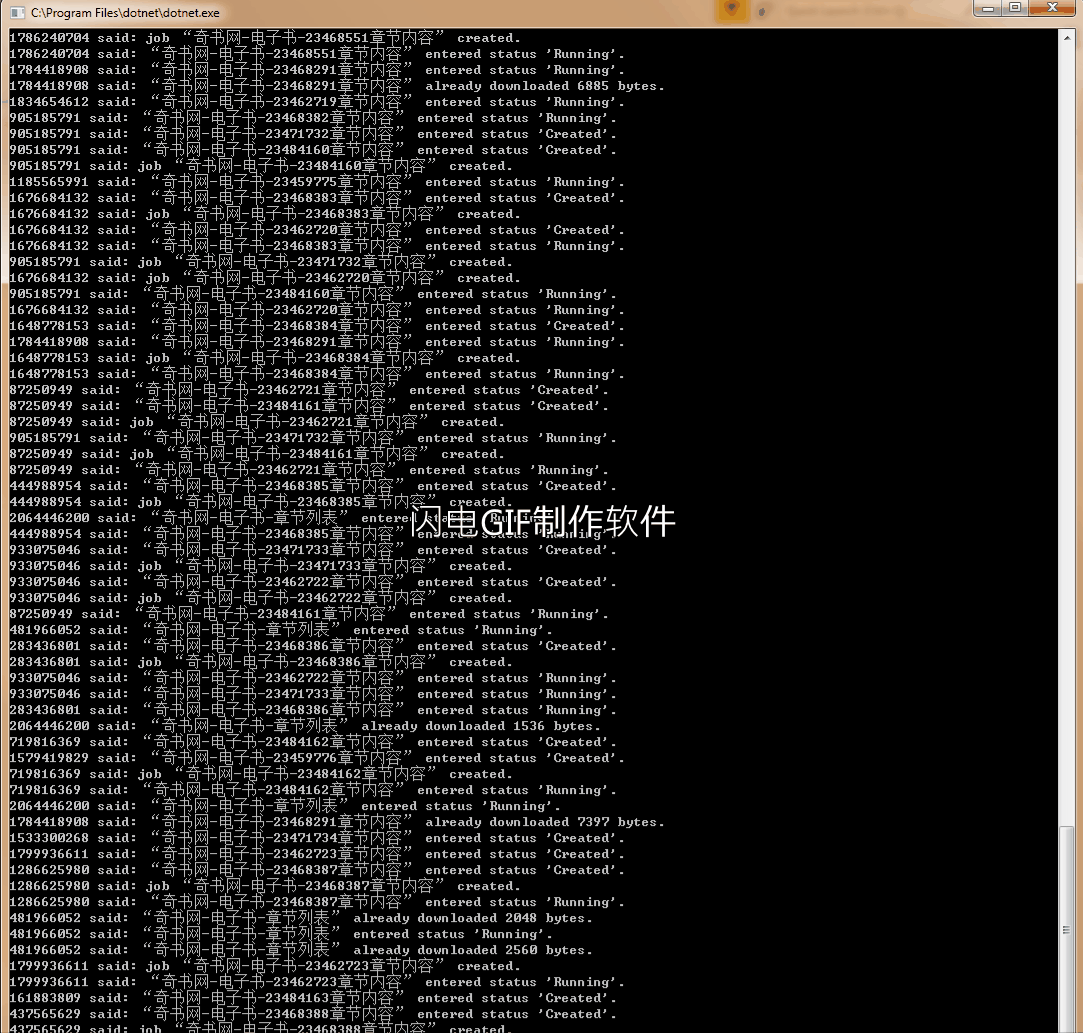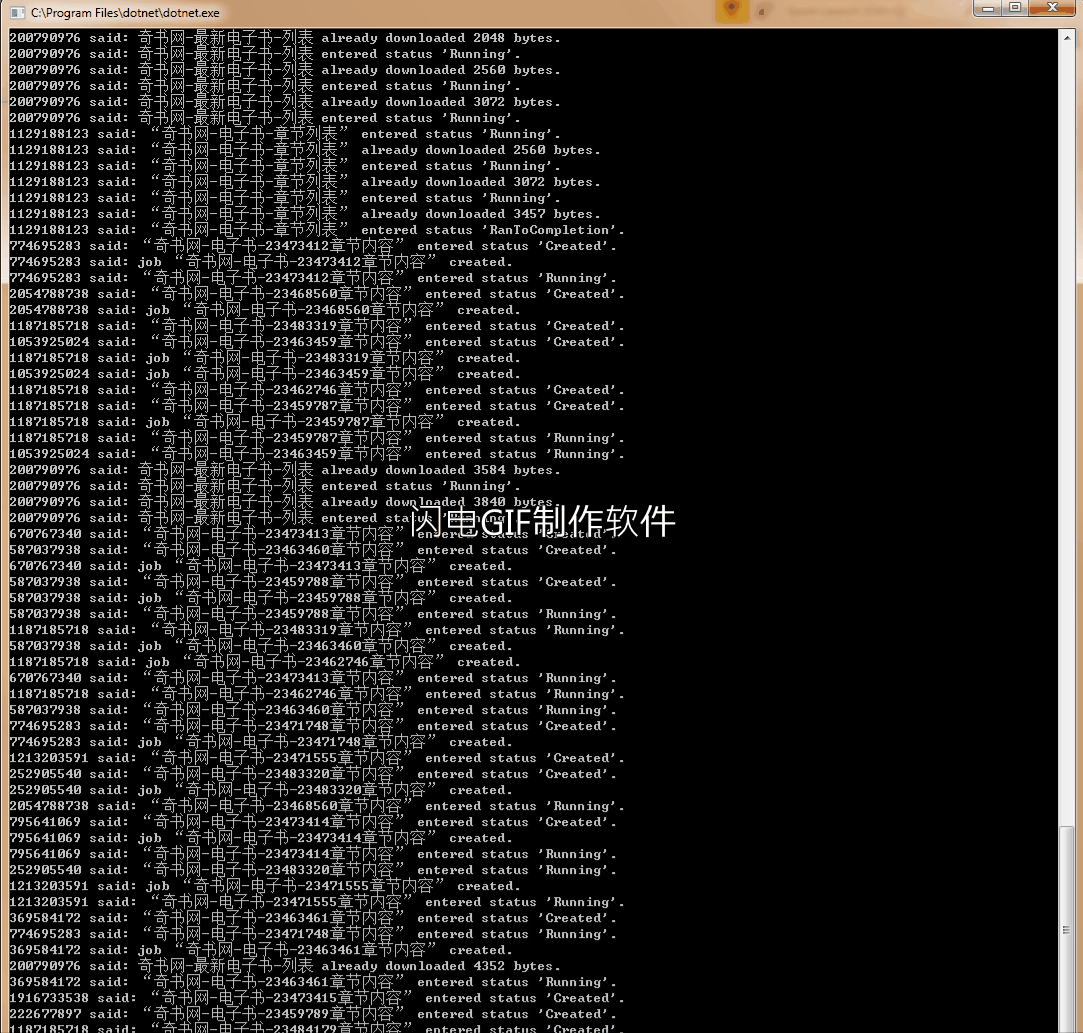
声明:本示例仅做为示例项目发布,并不赞成直接使用。
另:本示例还是有许多不足之处,比如,运行1分钟之后,会出现很多错误,比如,超时、目标主机积极拒绝、没有做异常处理等;这里就涉及到了爬虫框架的后续内容:反爬策略及应对,敬请期待后续章节;
喜欢本系列丛书的朋友,可以点击链接加入QQ交流群(994761602)【C# 破境之道】
方便各位在有疑问的时候可以及时给我个反馈。同时,也算是给各位志同道合的朋友提供一个交流的平台。
需要源码的童鞋,也可以在群文件中获取最新源代码。