方法一:将coredump文件放到服务器,再用toolchain的gdb查看
1.打开core功能,并设置生成的core文件的路径和文件名格式(都是临时修改,重启不会保存)
ulimit -c unlimited
echo "/tmp/core-%e-%p-%t" > /proc/sys/kernel/core_pattern
2.生成core文件
做完第一步后,重新拉起待监测的进程,使其crash
core-myClient-11415-1635469554
3.将生成的core文件导入到服务器上
如果是ftp传输,注意切换到binary传输模式,否则会在后面出现gdb不认识core文件
4.找到toolchain里的gdb,并读取nostrip的可执行档
./msdk-linux-gdb ~ /romfs_nostrip/bin/ myClient
5.读取刚刚生成的core file,目前这个是 strip的可执行档生成的
(gdb) core-file ~/core- myClient -11415-1635469554
结果如下
Core was generated by `/bin/myClient.
Program terminated with signal SIGSEGV, Segmentation fault.
#0 0x004a2c78 in set_ParameterValue (name=<error reading variable: Cannot access memory at address 0x3fec00>,
type=<error reading variable: Cannot access memory at address 0x3fec04>,
value=<error reading variable: Cannot access memory at address 0x3fec08>) at parameter_api.c:1926
1926 test_return = entity->info->op->setvalue(name, entity, type, value);
这样就可以定位到程序哪里出问题了。
方法二:借鉴客户的方法,直接编译user gdb,并放到板子当中运行
1.下载gdb 7.12 source code,并用我们的toolchain编译生成可执行档
2.将unstrip的myClient下载到板子中,修改为可执行并重新运行,等待crash出现,出现core dump file
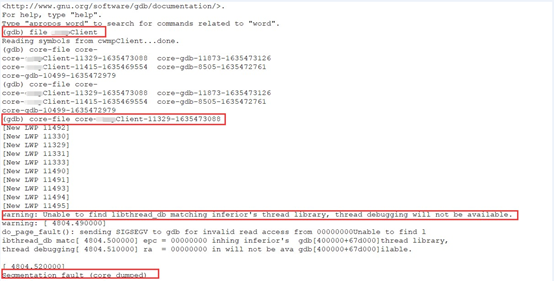
3.运行./gdb myClient -c core- myClient -11329-1635473088
目前这个方案只是理论上行的通,实践上存在一个问题,gdb虽然可以正常起来运行,不过加入core file的时候会出现gdb crash,
看warning: Unable to find libthread_db matching inferior's thread library, thread debugging will not be available.
应该是gdb运行依赖于libthread_db,而我们现在没有,或者版本不匹配
所以我们现在调试多线程的进程是不可以的