一、环境安装
Pycharm安装:python开发工具
https://www.jetbrains.com/pycharm/download/#section=windows
Python安装: 面向对象的脚本语言
Selenium安装:用于Web应用程序测试的工具
pip install –U selenium
Pytest安装:自动化测试框架
pip install pytest
浏览器驱动安装:测试工具与浏览器的交互
http://npm.taobao.org/mirrors/chromedriver
(需要配置环境变量的记得配置一下环境变量)
二、运行原理
Web自动化是代码与浏览器之间进行交互,由代码发送命令来驱动浏览器执行相应的操作。
Selenium代码与浏览器驱动程序之间是通过http协议进行数据交互的。这种方式,不在乎客户端是什么样的形式,只要数据的格式和协议是服务端能够解析的就可以。
通信步骤:
1、 Webdriver启动浏览器驱动程序,并设置侦听端口号
2、Webdriver客户端与浏览器服务端建立连接
3、连接成功后,所有的操作(比如查找元素、点击等)都是客户端通过commandExecuter发送http请求到服务端,服务端根据收到的请求做相应的操作并返回结果。
selenium 原理:就是通过webdriver 给浏览器的驱动发送命令,打开浏览器,建立http通信请求 然后通过发送各种命令让浏览器进而执行各种操作(selenium 原理)
三、框架分层介绍
UI测试框架主要用了数据驱动,关键字封装和PO思想搭建的,PO的核心思想是测试用例=页面对象+测试数据的,分离了测试用例和测试对象。
根据PO的思想,框架分为以下六层:
一是common层,该层主要是basepage,其basepage中包含所有待测试的page的公共方法把每个要测试的对象封装在一个class类中所有的pageobject继承basepage;如点击,等待元素,输入,截图,获取文本内容上传下载等的一些关键词,还存放封装好的日志,配置文件,文件路径脚本,框架运行入口等文件,封装关键词是为了减少冗余;
二是pagelocator层,主要是存放以页面为单位的元素定位;
三是pageobject层,主要是存放按照页面封装的页面操作;
四是testcase层,主要是存放按照功能模块划分的用例;
五是testdata层,主要是存放测试数据;
六是output层,主要存放截图,日志,报告等输出的文件。
四、元素定位
Selenium 八种元素定位方法:
1、id定位: find_element_by_id()
2、name定位: find_element_by_name()
3、class定位:find_element_by_class_name()
4、tag定位:find_element_by_tag_name()
5、link定位:find_element_by_link_text()
6、partial_link定位:find_element_by_partial_link_text()
7、CSS定位:find_element_by_css_selector()
8、xpath定位:find_element_by_xpath()
xpath基本定位语法:

1、绝对定位
特点:1.以单斜杠/开头;2.从页面根元素(HTML标签)开始,严格按照元素在HTML页面中的位置和顺序向下查找
如:"/html/body/div[2]/div[1]/div/div[1]/div/form/span[1]/input"
2、相对定位
特点:1.以双斜杠//开头;2.不考虑元素在页面当中的绝对路径和位置;3.只考虑是否存在符合表达式的元素即可。
我们一般都使用相对定位来定位元素。下面来介绍下常用的相对定位表达式。
2.1使用标签名+节点属性定位
语法://标签名[@属性名=属性值]
如:"//input[@id='baidu']"
2.2.组合元素索引(下标)定位
如:"//input[@id='baidu'][2]"
2.3.通过部分属性值匹配
语法://标签名[contains(@属性名,部分属性值)]、//标签名[starts-with(@属性名,部分属性值)]、//标签名[ends-with(@属性名,部分属性值)]
a. starts-with
如: //input[starts-with(@id,'ctrl')]
解析:匹配以 ctrl开始的属性值
b. ends-with
如://input[ends-with(@id,'_userName')]
解析:匹配以 userName 结尾的属性值
c. contains()
如://input[contains(@id,'userName')]
解析:匹配含有 userName 属性值
2.4.使用文本内容匹配
函数:text()
语法:文本全部匹配://标签名[text()=文本内容]
文本部分匹配-包含://标签名[contains(text(),部分文本内容)]
如:"//a[text(),"退出"]"
如:"//a[contains(text(),"出")]
2.5、使用轴定位表达式(使用较多场景:页面显示为一个表格样式的数据列)
轴运算名称:
ancestor:祖先节点,包括父节点
parent:父节点
preceding:当前元素节点标签之前的所有节点(HTML页面之前的)
preceding-sibling:当前元素节点标签之前的所有兄弟节点(同级)
following:当前元素节点标签之后的所有节点
following-sibling:当前元素节点标签之后的所有兄弟节点(同级)
使用语法:轴名称::节点名称
前后的定位与之前一致,用/隔开即可。
定义一个类,类的名称用当前页面的名称+Page+Locator:
如登录页面:LoginPageLocator
然后根据需要写元素定位

五、元素操作
定义一个类,类的名称用当前页面的名称+Page:
如登录页面:LoginPage
然后根据需要写每个操作

六、用例编写
在编写自动化测试用例过程中应该遵守以下几点原则:
1、一个用例为一个完整的场景,从用户登录系统到最终退出并关闭浏览器。
2、一个用例只验证一个功能点,不要试图在用户登录系统后把所有的功能都验证一遍。
3、尽量少的编写逆向逻辑用例。一方面因为逆向逻辑的用例很多(例如,手号输错有几十种情况);另一方面自动化脚本本身比较脆弱,对于复杂的逆向逻辑用例实现麻烦且容易出错。
4、用例与用例之间尽量避免产生依赖。
5、一条用例完成测试之后需要对测试场景进行还原,以免影响其它用例的执行。
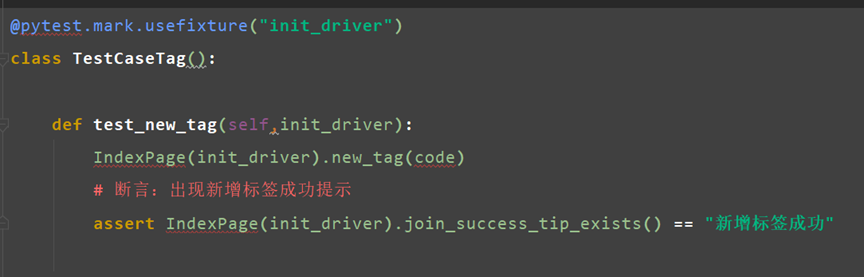
定义一个类,类的名称以Testk开头+当前操作的名称:
如登录页面:TestLogin
然后根据需要写每个步骤
七、测试报告
Allure报告:
下载版本:https://github.com/allure-framework/allure2/releases
下载完成之后,解压到 pytest 目录中。然后设置环境变量,简单一点就是进入 \allure\bin 目录执行 allure.bat 。cmd 输入 allure 查看环境变量是否设置成功
下载 allure-pytest 插件,用来生成 Allure 测试报告所需要的数据
@allure 装饰器中的一些功能点:
@allure.epic("epic对大Story的一个描述性标签,敏捷里面的概念,定义史诗,往下是 feature ")
@allure.feature("功能点的描述,理解成模块,如成本中心模块,往下是 story ")
@allure.story("用户故事的描述,如成本中心增删改查操作")
@allure.title("用例标题,如新增成本中心")
@allure.description("用例内容的描述,如测试【新增成本中心】功能,正向场景验证")
@allure.severity('用例等级,如critical')
生成报告命令:allure generate report/ -o report/html
--clean参数用来清空已有的报告,避免覆盖时出错
allure generate report/ -o report/allure --clean
在执行时会找到你的report路径下的.xml文件进行解析,生成最终报告到report/html文件夹下