机器学习中的评价指标--01
在机器学习中,性能指标(Metrics)是衡量一个模型好坏的关键,通过衡量模型输出y_predict 和 y_true之间的某种"距离"得出的。
性能指标往往是我们做模型时的最终目标,如准确率,召回率,敏感度等等,但是性能指标常常因为不可微分,无法作为优化的loss函数,因此采用如cross-entropy, rmse等“距离”可微函数作为优化目标,以期待在loss函数降低的时候,能够提高性能指标。而最终目标的性能指标则作为模型训练过程中,作为验证集做决定(early stoping或model selection)的主要依据,与训练结束后评估本次训练出的模型好坏的重要标准。
在机器学习的比赛中,有部分比赛也是用metrics作为排名的依据(当然也有使用loss排名)。
跑完分类模型(Logistic回归、决策树、神经网络等),我们经常面对一大堆模型评估的报表和指标,如ACC、ROC、AUC等,我们下面对各个评估指标逐一说明。
性能指标的分类
性能指标根据问题不同,主要分为:
| 学习分类 | 性能指标 |
|---|---|
| 分类 | Accuracy、precision、Recall、F1 Score、ROC Curve、PR Curve、AUC |
| 回归 | MAE、MSE、RMSE |
二分类性能指标(最经常使用)
首先一说到二分类性能指标,一般都会祭出混淆矩阵,我们这里给出混淆矩阵:
| 预测 1 | 预测 0 | 合计 | |
|---|---|---|---|
| 实际 1(P) | TP | FN | TP+FN |
| 实际 0(N) | FP | TN | FP+TN |
| 合计 | TP+FP | FN+TN | TP+FN+FP+TN |
这里解释一下上面列联表的意思:
T/F(True/False)表示预测是否正确,P/N(Positive/Negative)表示 预测的label而不是实际的label。
有了列联表就可以使用数学公式描述各个Metrics的含义了
准确率(Accuracy):
准确率是使用的最普遍的,也是最直观的性能指标,其定义如下:
(TP+TN)/(TP+FN+FP+TN)
意义是预测正确的sample占所有sample的比例,表示了一个分类器的区分能力,注意,这里的区分能力没有偏向于是正例还是负例,这也是Accuracy作为性能指标最大的问题所在.
假设是一个地震的分类器,0表示没有地震,1表示地震,由于地震概率非常小(通常是1e-x级别,姑且认为地震的概率是0.0001吧),因此,只要所有的例子来都猜是0,就能够是准确率(Accuracy)达到0.9999,使用Acc看来,这是一个好的分类器,而其实不然。对于地震的分类器,我们关心的是不是所有的正例全都被判别出来,至于一些时候,没有地震时,我们预测为1,只要在可接受范围内,那么,这个分类器就是一个好的分类器。
可以看到,对于数据不平衡或是当某一方数据漏掉(通常是把这样的例子作为正例)时会产生很大的代价的时候,我们需要更有效的指标作为补充。
精确率(Precision):
有时也叫查准率,定义如下:
TP/(TP+FP)
从定义中可以看出,精确率代表的是:在所有被分类为正例的样本中,真正是正例的比例。简单的来说,
“你说的1有多大概率是1!”, 就是这个道理。
这个指标常常被应用于推荐系统中,对某一个商品,以用户喜欢为1,不喜欢为0,使用查准率进行性能衡量。
在这个问题中,查准率可以理解成“网易云音乐每日推荐的20首歌曲中,我喜欢的歌曲所占的比例”
召回率(Recall):
也被称为查全率,在医学上常常被称作敏感度(Sensitive),定义如下:
TP/(TP+FN)
召回率的定义是,在所有实际为正例的样本中,被预测为正例的样本比例,简单说就是“总共这么多1,你预测对了多少?”
在医学领域(包括刚才说的地震),常把患病(发生地震)这样的高风险类别作为正类,当漏掉正类的代价非常高,像是漏诊可能导致病人的延迟治疗,或是地震了没有预测出来将会产生巨大的人员伤亡时,召回率就派上用场了。
在医学中,必须极力降低漏诊率,而误诊相对于误诊(把负例判为正例)相对于漏诊的重要性就低了很多。
特异性(Specificity):
特异性,定义如下:
SP=TN/(FP+TN)
特异性的语义为:实际为负的样本中,有多大概率被预测出来,这个定义和召回率非常像,二者区别只是对象不同,召回率是针对正例,而特异性针对的是负例。可以简单把特异性理解成“负例查全率”。
特异性在医疗中也被认为是一个重要指标,为什么呢,因为特异性低也就是“误诊率高”,举一个极端例子,一个分类器把所有的样本都判定成患病,此时敏感度为1,但是有特异性却很低。因此,在医学领域,特异性和敏感度是需要同时考量的。
F1 分数(F1 Score)
又称平衡F分数(balanced F Score),它被定义为精确率和召回率的调和平均数。
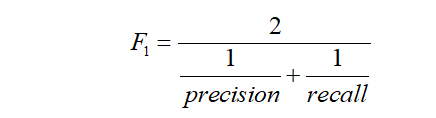
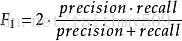
更一般的,我们定义
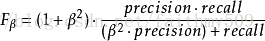
除了 F1分数之外, F2分数和F0.5分数在统计学中也得到大量的应用。其中,
F2分数中,召回率的权重高于准确率,而F0.5分数中,准确率的权重高于召回率。
物理意义
人们通常使用准确率和召回率这两个指标,来评价二分类模型的分析效果。
但是当这两个指标发生冲突时,我们很难在模型之间进行比较。比如,我们有如下两个模型A、B,A模型的召回率高于B模型,但是B模型的准确率高于A模型,A和B这两个模型的综合性能,哪一个更优呢?
| 准确率 | 召回率 | |
|---|---|---|
| A | 0.8 | 0.9 |
| B | 0.9 | 0.8 |
为了解决这个问题,人们提出了Fβ分数。
Fβ的物理意义就是将准确率和召回率这两个分值合并为一个分值,在合并的过程中,召回率的权重是准确率的β倍. F1分数认为召回率和准确率同等重要, F2分数认为召回率的重要程度是准确率的2倍,而F0.5分数认为召回率的重要程度是准确率的一半。
ROC曲线:
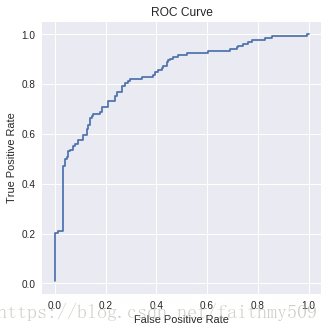
ROC曲线的全称叫做Receiver Operating Characteristic,常常被用来判别一个分类器的好坏程度,以下是一个ROC的例子:
首先看一下x轴坐标是False positive rate,即假正例率,其定义如下:
FPR=FP/(FP+TN)
这个指标乍一看比较奇怪,但是仔细对比一下公式可以发现,FPR=1−SP,假正例率代表的是负例中没有查出来的概率,简单说是“总共有这么多0,分类器没有查出来多少”而没有查出来的,自然就都被分为1了,那么这些0就被误诊了,因此,FPR代表的其实是“误诊率”。
被误诊的人数/所有健康的人数
就是他想表达的意思。
再看一下y轴是True positive rate真正例率,定义是:
TPR=TP/(TP+FN)
回头看一下,其实就是召回率(敏感度)啦~
ok,现在明白了,ROC的x轴是误诊率,y轴是漏诊率。可是一个分类器只可能得到一个数字,为什么会得出上图画出的那条曲线呢?
在一个二分类模型中,假设采用逻辑回归分类器,其给出针对每个实例为正例的概率,那么通过设定一个阈值如 0.6,概率大于等于 0.6 的为正例,小于 0.6 的为负例。对应的就可以算出一组(FPR,TPR),在平面中得到对应坐标点。随着阈值的逐渐减小,越来越多的实例被划分为正例,但是这些正例中同样也掺杂着真正的负例,即 TPR 和 FPR 会同时增大。阈值最大时,对应坐标点为(0,0),阈值最小时,对应坐标点(1,1)。
原来,画出ROC的曲线的方法不只是计算一次误诊率和漏诊率,按照以下方式进行:
- 将分类器预测为正例的概率从小到大排序
- 把每两个样本间的概率作为阈值,小于该阈值的分为负例,大于的分为正例
- 分别计算TPR和FPR
- 转2
- 当所有阈值都被枚举完之后,获得一组(TPR, FPR)的坐标点,将他们画出来。结束
这就是ROC曲线的画法,sklearn中已经对大量以上所说的性能指标做了实现,以下是ROC曲线在sklearn中如何调用
点击查看代码
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
p_rate = model.get_prob(X) #计算分类器把样本分为正例的概率
fpr, tpr, thresh = roc_curve(y_true, p_rate)
plt.figure(figsize=(5, 5))
plt.title('ROC Curve')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.grid(True)
plt.plot(fpr, tpr)
plt.savefig('roc.png')
AUC 值的计算
AUC (Area Under Curve) 被定义为 ROC 曲线下的面积,显然这个面积的数值不会大于 1。又由于 ROC 曲线一般都处于 y=x 这条直线的上方,所以 AUC 的取值范围一般在 0.5 和 1 之间。使用 AUC 值作为评价标准是因为很多时候 ROC 曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应 AUC 更大的分类器效果更好。
AUC 的计算有两种方式,梯形法和 ROC AUCH 法,都是以逼近法求近似值,具体见wikipedia。
AUC 意味着什么
那么 AUC 值的含义是什么呢?根据(Fawcett, 2006),AUC 的值的含义是:
The AUC value is equivalent to the probability that a randomly chosen positive example is ranked higher than a randomly chosen negative example.
这句话有些绕,我尝试解释一下:首先 AUC 值是一个概率值,当你随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的 Score 值将这个正样本排在负样本前面的概率就是 AUC 值。当然,AUC 值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。
从 AUC 判断分类器(预测模型)优劣的标准:
- AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
- AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
- AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
三种 AUC 值示例:
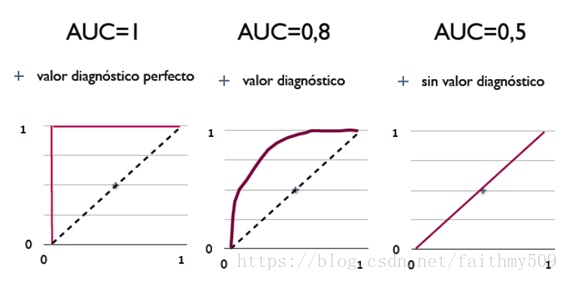
简单说:AUC 值越大的分类器,正确率越高。
为什么使用 ROC 曲线
既然已经这么多评价标准,为什么还要使用 ROC 和 AUC 呢?因为 ROC 曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC 曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。下图是 ROC 曲线和Precision-Recall曲线的对比:
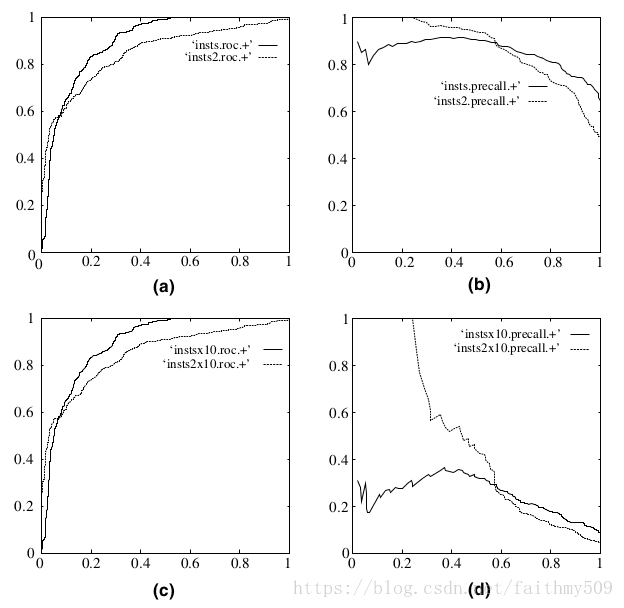
在上图中,(a)和(c)为 ROC 曲线,(b)和(d)为 Precision-Recall 曲线。(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,(c)和(d)是将测试集中负样本的数量增加到原来的 10 倍后,分类器的结果。可以明显的看出,ROC 曲线基本保持原貌,而 Precision-Recall 曲线则变化较大。