从王者荣耀看设计模式(解释器模式)
一.简介
为了方便玩家沟通,王者荣耀允许玩家在游戏的同时录入语音,然后系统自动解释录入的语音,转换为字符串显示在玩家聊天的区域─━ _ ─━✧
二.模式动机
在某些情况下,为了更好得描述某些特定类型的问题,可以创建一个新的语言,这个语言有自己的表达式和结构,即语法规则,而且可以根据需要灵活的增加新的语法规则。解释器模式描述了如何构成一个简单的语言解释器。主要应用在使用面向对象语言开发的编译器中。在本实例中,模拟玩家的语音输入,将%解释为"",'#'解释为逗号,'@'解释为句号
三.解释器模式
解释器模式(Interpreter Pattern):定义语言的文法,并且建立一个解释器;来解释该语言中的句子。这里的"语言"意思是使用规定格式和语法的代码,它是一种类行为型模式
解释器模式的使用场景:
在以下情况下可以使用解释器模式:
■ 可以将一个需要解释执行的语言中的句子表示为一个抽象语法树
■ 一些重复出现的问题可以用一种简单的语言来进行表达
■ 简单的文法
■ 效率不是关键问题。使用解释器模式的执行效率并不高
解释器模式通用类图

解释器模式涉及的角色:
解释器模式包含以下角色:
(1)抽象表达式(Expression)角色:声明一个所有的具体表达式角色都需要实现的抽象接口。这个接口主要是一个interpret()方法,称做解释操作。
(2)终结符表达式(Terminal Expression)角色:实现了抽象表达式角色所要求的接口,主要是一个interpret()方法;文法中的每一个终结符都有一个具体终结表达式与之相对应。比如有一个简单的公式R=R1+R2,在里面R1和R2就是终结符,对应的解析R1和R2的解释器就是终结符表达式。
(3)非终结符表达式(Nonterminal Expression)角色:文法中的每一条规则都需要一个具体的非终结符表达式,非终结符表达式一般是文法中的运算符或者其他关键字,比如公式R=R1+R2中,“+"就是非终结符,解析“+”的解释器就是一个非终结符表达式。
(4)环境(Context)角色:这个角色的任务一般是用来存放文法中各个终结符所对应的具体值,比如R=R1+R2,我们给R1赋值100,给R2赋值200。这些信息需要存放到环境角色中,很多情况下我们使用Map来充当环境角色就足够了
解释器模式优点:
解释器模式的优点
1、易于改变和扩展文法。因为该模式使用类表示文法,所以可以使用继承改变或扩展该文法。
2、每条文法规则都可以是一个类,所以可以很方便的实现一个简单的语言。
3、易于实现文法的定义。在抽象语法树中每一个表达式节点类的实现方式都是相似的,这些类的代码编写都不会特别复杂,还可以通过一些工具自动生成节点类代码。
4、增加新的解释表达式较为方便。如果用户需要增加新的解释表达式只需要对应增加一个新的终结符表达式或非终结符表达式类,原有表达式类代码无须修改,符合“开闭原则”。
解释器模式缺点:
1、对于复杂文法难以维护。在解释器模式中,每一条规则至少需要定义一个类,因此如果一个语言包含太多文法规则,类的个数将会急剧增加,导致系统难以管理和维护,此时可以考虑使用语法分析程序等方式来取代解释器模式。
2、执行效率较低。由于在解释器模式中使用了大量的循环和递归调用,因此在解释较为复杂的句子时其速度很慢,而且代码的调试过程也比较麻烦
四.结构图
五.设计类图

用一段字符串模拟语音,定义一种解析文法,将客户端输入的模拟语音字符串解释为目标字符串并显示
六.代码实现
创建抽象表达式类(Node类)
package com.practice.node;
/*
* 创建抽象表达式类,它声明了抽象解释方法interpret(),在其子类中将提供该方法的实现
*/
public interface Node {
public String interpret();
}
终结符表达式类(StringNode类)
package com.practice.node;
/*
* 创建终结符表达式类(字符串类节点)
* StringNode是终结符表达式类,对应终结符的操作
* 实现了在抽象表达式中声明的interpret()方法
*/
public class StringNode implements Node {
private String sound;
public StringNode(String sound) {
this.sound = sound;
}
@Override
public String interpret() {
return this.sound;
}
}
抽象非终结符表达式类(SymbolNode类)
package com.practice.node;
/*
* 创建抽象非终结符类表达式,它包含了所有非终止符表达式的共有数据和行为
* 在本实例中,由于所有的非终止符都对应左右两个操作部分,因此在该类中
* 定义了left和right两个Node类型的对象
*/
public abstract class SymbolNode implements Node {
protected Node left;
protected Node right;
public SymbolNode(Node left,Node right) {
this.left = left;
this.right= right;
}
}
非符号终结符类(PauNode类)
package com.practice.node;
/*
* 定义非终结符,当语音中有'%'.会解析为""
*/
public class PauNode extends SymbolNode {
public PauNode(Node left, Node right) {
super(left, right);
}
@Override
public String interpret() {
return super.left.interpret() + "";
}
}
非符号终结符类(CommmaNode类)
package com.practice.node;
/*
* 定义非终结符,当语音中有'#'.会解析为","
*/
public class CommaNode extends SymbolNode {
public CommaNode(Node left, Node right) {
super(left, right);
}
@Override
public String interpret() {
return "," + super.left.interpret();
}
}
非符号终结符类(CommmaNode类)
package com.practice.node;
/*
* 定义非终结符,当语音中有'@'.会解析为"。"
*/
public class StopNode extends SymbolNode {
public StopNode(Node left, Node right) {
super(left, right);
}
@Override
public String interpret() {
return "。" + super.left.interpret();
}
}
环境类(Interpreter类)
package com.practice.interpreter;
import java.util.Stack;
import com.practice.node.CommaNode;
import com.practice.node.Node;
import com.practice.node.PauNode;
import com.practice.node.StopNode;
import com.practice.node.StringNode;
/*
* 解释器封装类Interpreter(核心类)
*/
public class Interpreter {
@SuppressWarnings("unused")
//需要解释的字符串
private String speechSound;
@SuppressWarnings("unused")
private Node node;
private String sound="";
//将字符串按照特定文法解释,定义了一个抽象树的结构,left保存终结符,right嵌套保存非终结符
public void Explain(String speechSound) {
Node left = null, right = null;
//使用栈结构存取数据
Stack<Object> stack = new Stack<Object>();
char[] speechArray = speechSound.toCharArray();
//System.out.println(speechArray[0]);
for (int i = 0; i < speechArray.length; i++) {
//需要解释的字符串中有'%'解释为""
if (speechArray[i] == '%') {
left = (Node) stack.pop();
String val = String.valueOf(speechArray[i]);
right = new StringNode(val);
stack.push(new PauNode(left, right));
}
//需要解释的字符串中有'#'解释为","
else if (speechArray[i] == '#') {
left = (Node) stack.pop();
//System.out.println("left:"+left.interpret());
String val = String.valueOf(speechArray[i]);
right = new StringNode(val);
stack.push(new CommaNode(left, right));
}
//需要解释的字符串中有'@'解释为"。"
else if (speechArray[i] == '@') {
left = (Node) stack.pop();
String val = String.valueOf(speechArray[i]);
right = new StringNode(val);
stack.push(new StopNode(left, right));
} else {
if (left != null && right != null) {
left = (Node) stack.pop();
//System.out.println("left:"+left.interpret());
sound = left.interpret();
}
stack.push(new StringNode(String.valueOf(speechArray[i]+sound)));
}
}
this.node = (Node) stack.pop();
}
//逆转解析过的字符串(栈结构先入后出)
public static String reverse(String s) {
int length = s.length();
String reverse = "";
for (int i = 0; i < length; i++)
reverse = s.charAt(i) + reverse;
return reverse;
}
public String toSound() {
//调用node.interpret会递归调用内部多个对象的interpret方法
return reverse(node.interpret());
}
}
工具类读取XML文件内容(XMLUtilInter类)
package com.practice.Client;
import java.io.File;
import javax.xml.parsers.*;
import org.w3c.dom.*;
public class XMLUtilInter {
//该方法用于从XML配置文件中提取具体类类名。并返回一个实例对象
public static String getSpeechSound() {
try {
//创建文档对象
DocumentBuilderFactory dFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = dFactory.newDocumentBuilder();
Document doc;
doc = builder.parse(new File("src\com\practice\Client\config.xml"));
//获取包含类名的文本节点
NodeList nl = doc.getElementsByTagName("speechSound");
Node classNode = nl.item(0).getFirstChild();
String sound = classNode.getNodeValue();
return sound;
}catch(Exception e) {
e.printStackTrace();
return null;
}
}
}
测试类(Client类)
package com.practice.Client;
import java.awt.BorderLayout;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JTextArea;
import com.practice.interpreter.Interpreter;
/*
* 创建客户测试类
* 点击GUI中解释按钮显示经过解释器解释的用户的语音(模拟)
* @param speechSound:从xml文件中的语音
* @param explainSound:经解释器解析为字符串
*/
public class Client {
public static void main(String[] args) {
//创建解释器窗口
JFrame jf = new JFrame("解释器");
jf.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
JButton btn = new JButton("解释");
btn.setSize(100, 30);
JTextArea jat = new JTextArea();
jat.setSize(300, 200);
String speechSound;
//从配置文件config.xml中读取用户的语音
speechSound = (String) XMLUtilInter.getSpeechSound();
String explainSound;
//将解释器实例化
Interpreter interpreter = new Interpreter();
//解释器解释语音
interpreter.Explain(speechSound);
explainSound = interpreter.toSound();
//按钮事件显示语音内容
btn.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
jat.setText("狄仁杰:"+ explainSound);
}
});
jf.setLayout(new BorderLayout());
jf.setLocation(600,200);
jf.setSize(300,300);
jf.add(jat,BorderLayout.CENTER);
jf.add(btn,BorderLayout.SOUTH);
jf.setVisible(true);
}
}
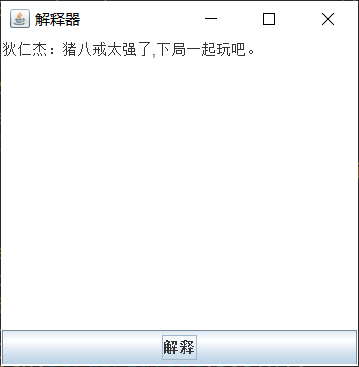
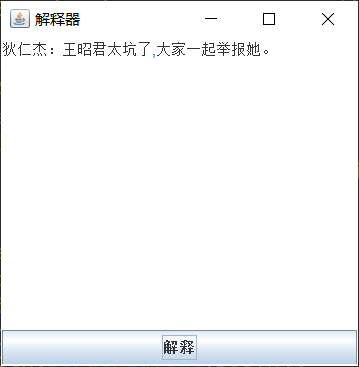
运行结果
配置文件(config.xml)
<?xml version="1.0" encoding="UTF-8"?>
<config>
<speechSound>王%昭%君%太%坑%了#大%家%一%>起%举%报%她@</speechSound>
</config>
<?xml version="1.0" encoding="UTF-8"?>
<config>
<speechSound>猪%八%戒%太%强%了#下%局%一%起%玩%吧@</speechSound>
</config>