一:学习内容
- 获取更改系统编码
- 判断字符的编码类型
- 文件存储和读取的编码
二:获取更改系统编码
1. 获取系统编码
import sys
print sys.getdefaultencoding()

2. 更改系统编码
#encoding=utf-8
import sys
reload(sys)
sys.setdefaultencoding('UTF-8')
print 1,sys.getdefaultencoding()
print 2,type(u"我")
print 3,type("我")
print 4,u"我"
print 5,"我"
print 6,u"我".encode('utf-8')
print 7,u"我".decode('utf-8')
print 8,"我".encode('utf-8').decode('utf-8')
print 9,"我".decode('utf-8').encode('gbk')
print 10,"我".encode('gbk')
运行结果为:

问题一:为什么要reload sys模块
在site.py文件里有这么一段代码:
if hasattr(sys, "setdefaultencoding"):
del sys.setdefaultencoding
在sys加载后,setdefaultencoding方法被删除了,所以我们要通过重新导入sys来设置系统编码。
问题二:为什么print 4,u"我"可以打印正常,print 5,"我"打印乱码
字符串的打印,python的逻辑为:如果是unicode字符串,则可以自动编码为终端所用编码,然后正确显示出来。所以u"我"实际上将"我"进行了decode成了unicode字符,然后python将unicode字符串自动化编码为gbk(我的cmd的编码)

而print 5,”我”,字符串编码为utf-8类型(文件保存的类型),输出到cmd为gbk类型的终端上,则无法显示。
问题三:为什么print 8,"我".encode('utf-8').decode('utf-8')可以打印正常,print 6,u"我".encode('utf-8')打印乱码
因为我是str类型,在encode前,python自动会用默认编码(setdefaultencoding)进行decode为unicode类型,但是如果默认编码为ascii,是不支持decode的。

可以看到文件里修改了默认编码为utf-8,所以"我".encode('utf-8').decode('utf-8')这句首先会decode('utf-8')为unicode类型,然后在encode('utf-8').decode('utf-8'),此时”我”已经变成了unicode类型,如果是unicode字符串,则可以自动编码为终端所用编码(这是问题一中提到的),这样就能输出到cmd终端了。
然后我们再说为什么print 6,u"我".encode('utf-8')会乱码呢,上面已经讲了在encode('utf-8')之前会decode('utf-8')为unicode类型,然后在执行.encode('utf-8'),此时”我”会被编码成utf-8,然后print输出到cmd的gbk终端,由于编码不统一,就会乱码。
三:判断字符的编码类型
1. chardet.detect(字符内容)
#encoding=utf-8
import chardet
import urllib
TestData = urllib.urlopen('http://www.baidu.com/').read()
print chardet.detect(TestData)

发现打印的字符编码类型为utf-8。
2. import chardet如果报错ImportError: No Module named chardet,则需要下载安装该模块,步骤为:
第一步:在https://pypi.python.org/pypi/chardet#downloads下载chardet-2.1.1.tar.gz

第二步:解压 chardet-2.1.1.tar.gz文件到Libsite-packages下
第三步:安装 chardet模块,进入到python的Libsite-packageschardet-2.3.0路径下,执行python setup.py install

这样就完成chardet模块安装了,此时你可以在去运行上面的文件。
四:文件存储和读取的编码
1. 计算机内存中,统一使用unicode编码,当需要保存到硬盘或需要传输的时候,就转换为UTF-8编码
2. 用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把unicode转换为UTF-8保存到文件

3. 浏览网页的时候,服务器会把动态生成的unicode内容转换为UTF-8在传输到浏览器
很多网页源码上会有类似<meta charset='utf-8'/>的信息,表示该网页正是用的UTF-8编码
小记:
a. 在utf-8文件中,则这个字符串就是utf-8编码的,它的编码取决与当前的文本编码。
b. GB2312文本的编码就是GB2312。
c. 在同一个文本中进行两种编码的输出等操作就必须进行编码的转换,先用decode将文本原来的编码转换成unicode,再用encode将编码转换成需要转换成的编码。
d. 实例练习:
手工创建一个文件如a.txt,以ansi编码保存即gbk,然后取出数据变成utf-8编码保存到b.txt文件中,查看b.txt文件编码为utf-8
#encoding=utf-8
f=open('C:\Users\yumeiling\Desktop\a.txt','r')
data=f.read()
temp = data.decode('gbk')
f.close()
f=open('C:\Users\yumeiling\Desktop\b.txt','w')
temps=temp.encode('utf-8')
f.write(temps) #写入utf-8字符,并进行保存
f.close()
运行结果为:查看b.txt文件
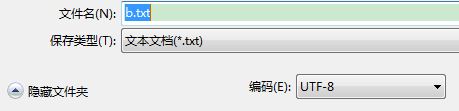
这样执行后,发现生成了b.txt文件,文件的编码为改成了utf-8编码。