一、定义:
NSDictionary(字典)是使用hash表来实现key和value映射和存储。
二、哈希表
1、定义:
哈希表本质是一个数组,数组中每一个元素称为一个桶bucket,bucket中存放的是键值对,整个数组叫做Buckets 或者 Bucket Array
2、特点:
空间复杂度有可能非常大,是以空间换时间的典型代表,时间复杂度趋近于 O(1)
3、hash表的过程图
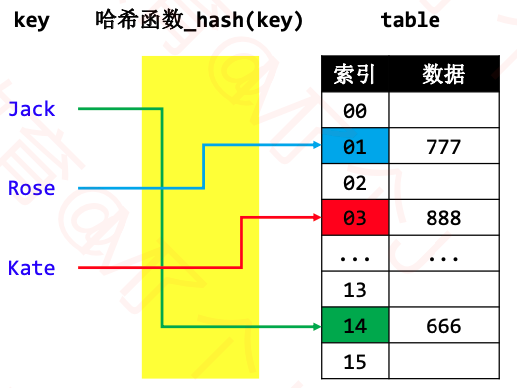
hash表存储过程简单介绍:
- 根据key值计算出它的hashCode为H;
- 假设表,箱子的个数是N,那么键值对应该放在下标为(H%N)的箱子中。
- 如果该箱子中已经有了键值对,就产生哈希冲突(转4)
解读过程:
1、用key通过哈希函数得到索引index (整个过程是 O(1))
2、根据index定位到数组元素,并拿到value (整个过程是 O(1))
4、哈希冲突
1、开放定址法:
按照一定的规则向其他地址探测,直到找到空桶(比如,线性向下,数值的平房向下1^2,2^2,3^2,4^2……)
2、再哈希法:设计多个哈希函数
3、链地址法:通过链表、二叉树等发生将同一个index的元素串起来

拉链法的优势
与开放定址线性探测法相比,拉链法有以下几个优势:- ①、拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,所以平均查找长度较短;- ②、因为拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前没法肯定表长的状况;- ③、开放定址线性探测发为减小冲突,要求负载因子较小,故当结点规模较大时会浪费不少空间。④、在用拉链法构造的散列表中,删除结点的操做易于实现。只要简单地删去链表上相应的结点便可。而对开放定址线性探测发构造的散列表,删除结点不能简单地将被删结 点的空间置为空,不然将截断在它以后填入散列表的同义词结点的查找路径。这是由于各类开放定址线性探测法中,空地址单元(即开放地址)都是查找失败的条件。所以在用开放定址线性探测发处理冲突的散列表上执行删除操做,只能在被删结点上作删除标记,而不能真正删除结点。
拉链法的缺点
指针须要额外的空间,故当结点规模较小时,开放定址线性探测法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可以使负载因子变小,这又减小了开放定址线性探测法中的冲突,从而提升平均查找速度。
开放定址线性探测法缺点
- - 一、容易产生堆积问题;
- - 二、不适于大规模的数据存储;
- - 三、散列函数的设计对冲突会有很大的影响;
- - 四、结点规模很大时会浪费不少空间;
总结:当可以预估表时,并且规模较小时 优先选择开放定址线性探测法。

NSDictionary的官方文档
解释一:是使用NSMapTable实现的,采用拉链法解决哈希冲突
解释二:是对_CFDictionary的封装,解决哈希冲突使用的是开放定址线性探测法

从上面的数据结构可以看出内部使用了两个指针数组分别保存keys和values。采用的是 连续方式 存储键值对。拉链法会将key和value包装成一个结果存储(链表结点),而上面的结构拥有keys和values两个数组(开放寻址线性探测法解决哈希冲突的用的就是两个数组),说明两个数据是被分开存储的,而不是拉链法。
根据数据结构,猜测解决哈希冲突是用开放定址法。
这样把一些不连续的key-value值插入到了能建立起关系的hash表中,当我们查找的时候,key根据哈希值算出来索引,直接index访问 hash表keys和hash表values,这样查询速度就可以和连续线性存储的数据一样接近O(1)了,只是占用空间有点大,性能就很强悍。
如果删除的时候,也会根据_maker标记逻辑上的删除,除非NSDictionary(NSDictionary本体的hash值就是count)内存被移除。
验证:
1、hashCode相等,但 isEqual 不等,模拟哈希冲突
结果: 由于打印出来的value和存储的顺序相同,推断出是线性解决冲突
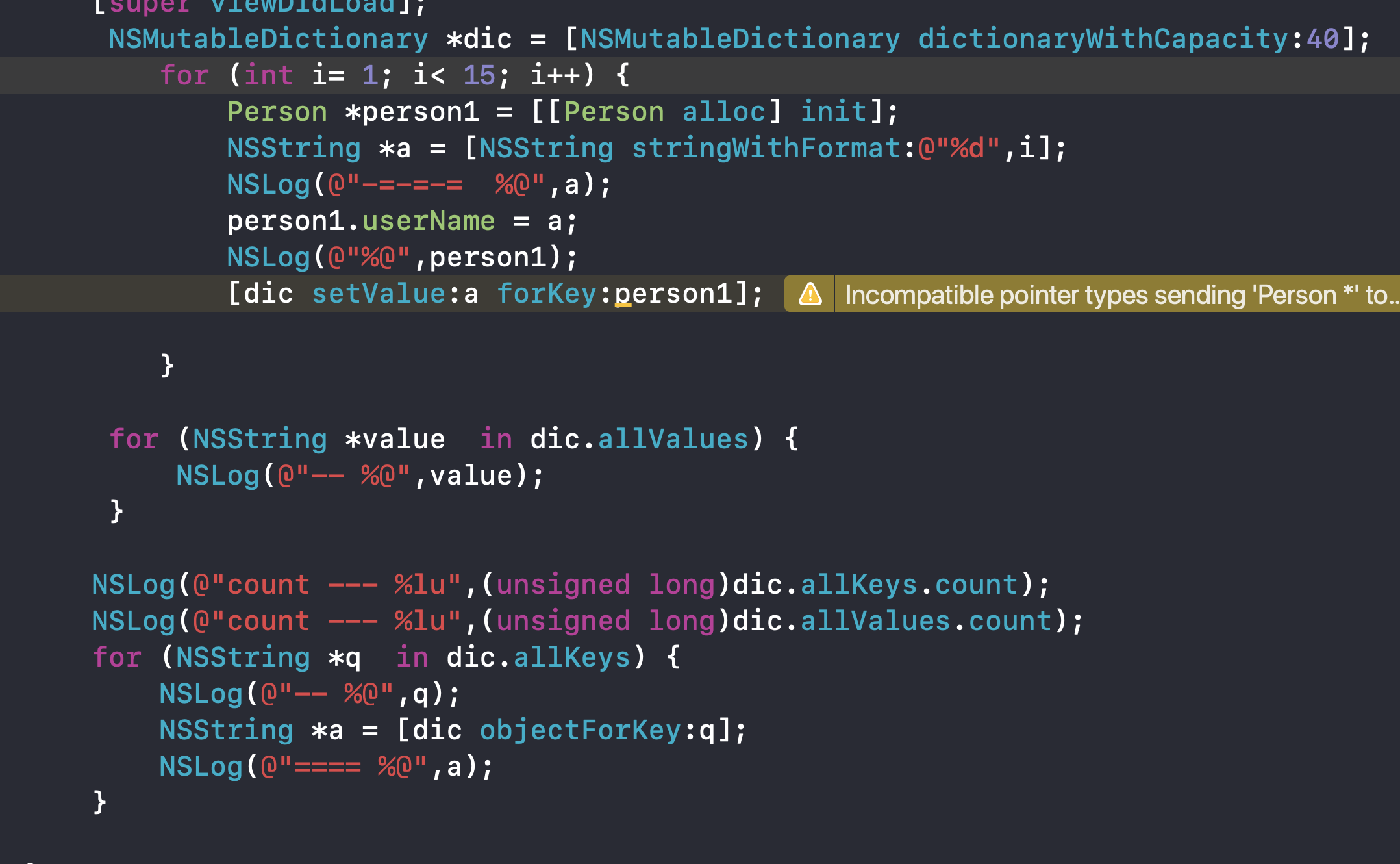
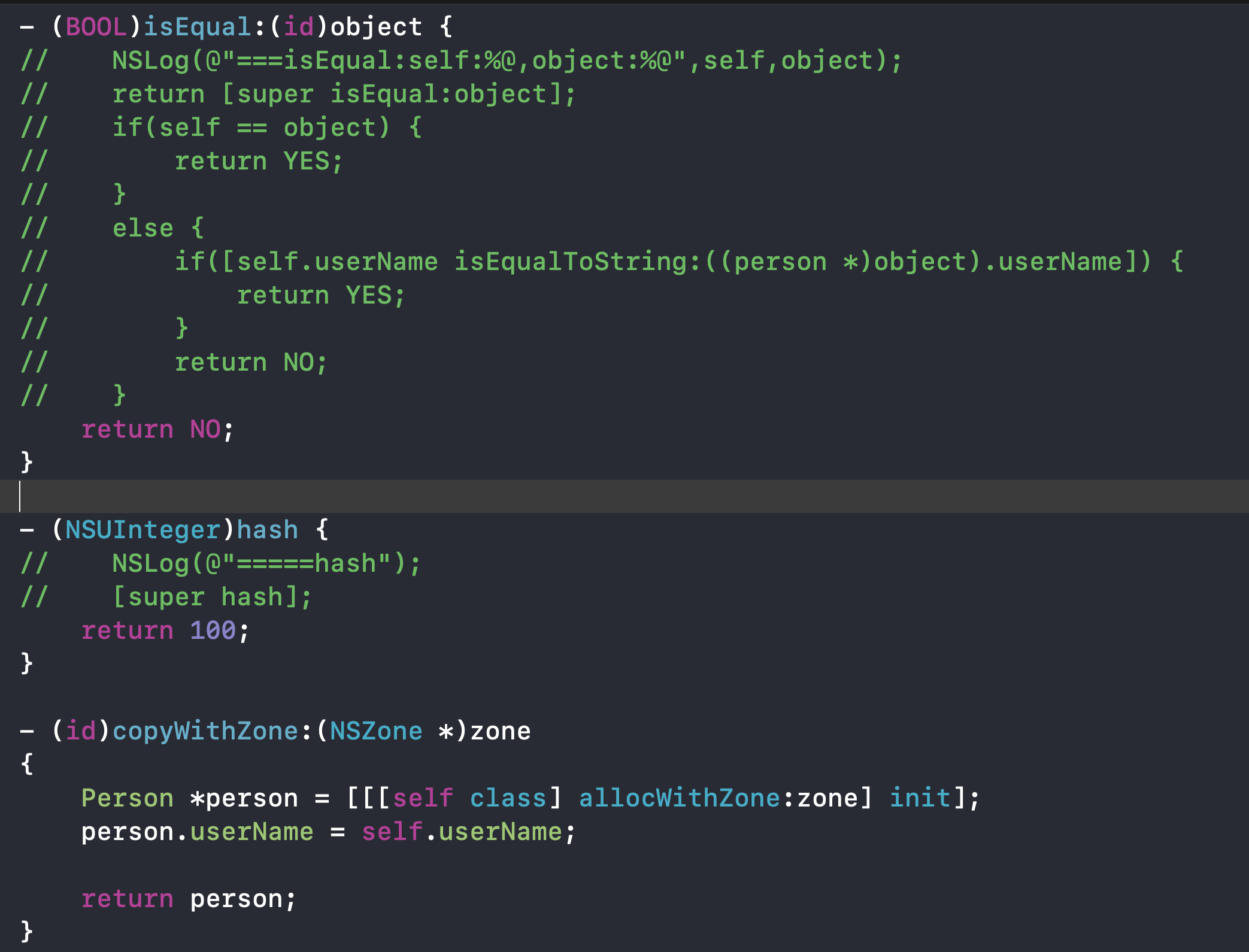
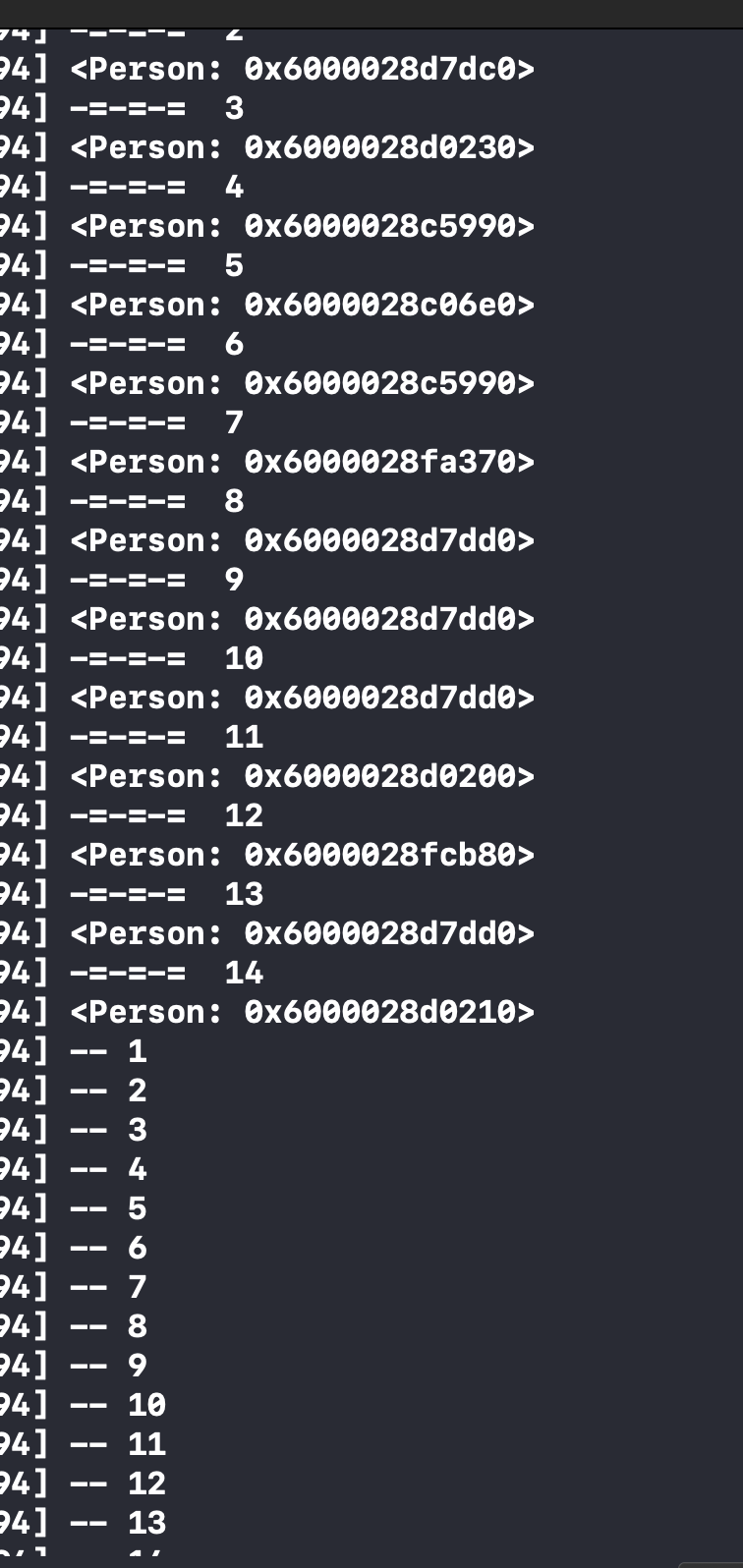
结论:由于验证效果,模拟哈希冲突,打印出value和存储数据顺序是完全一样的,任务NSDictionary用的是开放定址线性探测法。
三、优化点:
1、哈希函数
设计一个优秀的哈希算法总结了须要满足几点要求:
- 从哈希值不能反向推导出原始数据(因此哈希算法也叫单向哈希算法);
- 对输入数据很是敏感,哪怕原始数据只修改了一个 Bit,最后获得的哈希值也大不相同;
- 散列冲突的几率要很小,对于不一样的原始数据,哈希值相同的几率很是小;
- 哈希算法的执行效率要尽可能高效,针对较长的文本,也能快速地计算出哈希值。
1、java的哈希函数的步骤(用key拿到index)
A、先生成key的哈希值P(必须是整数)
B、让key的哈希值P和哈希表的容量大小N做取模运算,生成一个索引值index
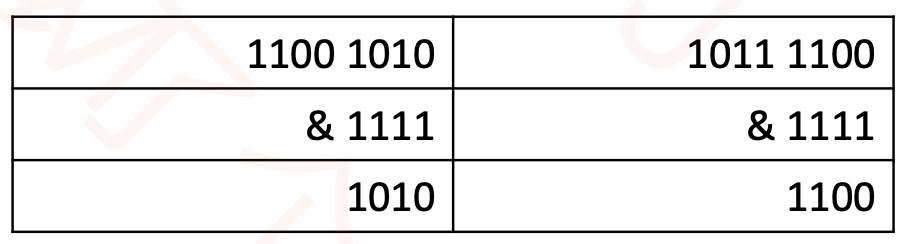
这里取模运算用&代替%运算(前提:数组长度设计为2^n (2的幂))

优化成

这个table.length - 1 转换 就是11111,任何事和都是111的做&运算,都得 0-table.length - 1 中,就等到了 余数。
在java中 Long,Double类型是用数据的前32bit 和 其 后 32bit 做 ^ (与或运算)。(因为 坚持对象所有内容都参与哈希值计算原则 )
举个例子:

再 以1234为例子
1234 = 1 * 10^3 + 2 * 10 ^2 + 3 * 10^2 + 4
= [( ( 1 * 10 + 2 ) * 10 + c ) * 10 + 4 ]
java中把10 设置为31,(31*i 可以优化成 【(i << 5)- i 】 )

对31的解释:
31是一个寄素数,素数和其他数相乘的结果比其他方式更容易产生唯一性,减少哈希冲突,最终选择31是经过观测分布结果后的选择。
注意:
如果想自定义对象哈希值时,注意需要hashCode和equals两个函数都重写
需要把对象的所有属性都用到计算哈希值,这样可以减小哈希冲突
2、哈希扩容:
背景:当存储的元素个数越来越多,在hash表长度不变的前提下,发生哈希冲突的概率就会变大,查找性能就变低了。所以当负载因子达到一定的值,hash表会进行自动扩容。
负载因子(load factor):总键值对数量 / 箱子个数
扩容方法:
负载因子是哈希表的一个重要属性,用来衡量哈希表的空/满程度,负载因子越大,意味着哈希表越满,越容易致使冲突,性能也就越低。因此当负载因子大于某个常数(也许是0.75)时,哈希表将自动扩容。哈希表扩容时,通常会建立两倍于原来的数组长度。所以即便key的哈希值没有变化,对数组个数取余的结果会随着数组个数的扩容发生变化,所以键值对的位置都有可能发生变化,这个过程也成为重哈希(rehash)。
3、哈希表在OC中应用:
