效果图:
EpidemicSituation.py
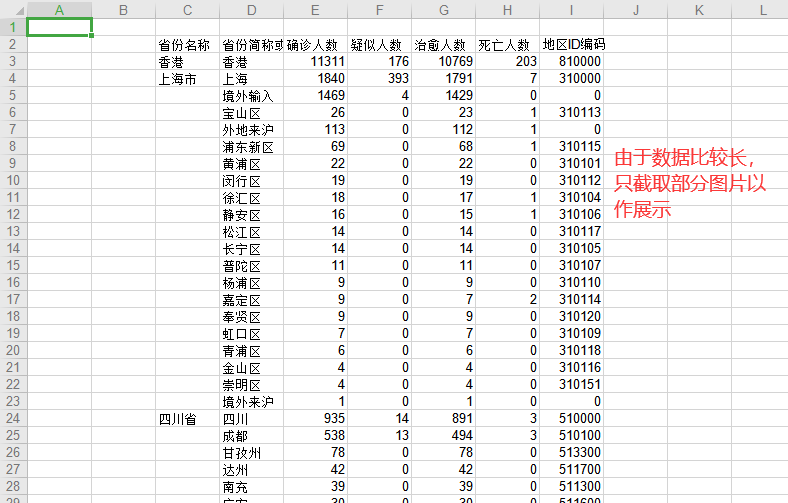
1 import requests,os 2 import re 3 import xlwt 4 import time 5 import json 6 7 class get_yq_info: 8 9 def get_data_html(self): 10 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1'} 11 response = requests.get('https://ncov.dxy.cn/ncovh5/view/pneumonia?from=timeline&isappinstalled=0', headers=headers, timeout=3) 12 # 请求页面 13 14 response = str(response.content, 'utf-8') 15 # 中文重新编码 16 return response 17 #返回了HTML数据 18 19 def get_data_dictype(self): 20 areas_type_dic_raw = re.findall('try { window.getAreaStat = (.*?)}catch(e)',self.get_data_html()) 21 areas_type_dic = json.loads(areas_type_dic_raw[0]) 22 return areas_type_dic 23 #返回经过json转换过的字典化的数据 24 25 def save_data_to_excle(self): 26 self.make_dir() 27 #调用方法检查数据目录是否存在,不存在则创建数据文件夹 28 count = 2 29 #数据写入行数记录 30 newworkbook = xlwt.Workbook() 31 worksheet = newworkbook.add_sheet('all_data') 32 # 打开工作簿,创建工作表 33 34 worksheet.write(1, 2, '省份名称') 35 worksheet.write(1, 3, '省份简称或城市名称') 36 worksheet.write(1, 4, '确诊人数') 37 worksheet.write(1, 5, '疑似人数') 38 worksheet.write(1, 6, '治愈人数') 39 worksheet.write(1, 7, '死亡人数') 40 worksheet.write(1, 8, '地区ID编码') 41 #写入数据列标签 42 43 for province_data in self.get_data_dictype(): 44 provincename = province_data['provinceName'] 45 provinceshortName = province_data['provinceShortName'] 46 p_confirmedcount = province_data['confirmedCount'] 47 p_suspectedcount = province_data['suspectedCount'] 48 p_curedcount = province_data['curedCount'] 49 p_deadcount = province_data['deadCount'] 50 p_locationid = province_data['locationId'] 51 #用循环获取省级以及该省以下城市的数据 52 53 worksheet.write(count, 2, provincename) 54 worksheet.write(count, 3, provinceshortName) 55 worksheet.write(count, 4, p_confirmedcount) 56 worksheet.write(count, 5, p_suspectedcount) 57 worksheet.write(count, 6, p_curedcount) 58 worksheet.write(count, 7, p_deadcount) 59 worksheet.write(count, 8, p_locationid) 60 #在工作表里写入省级数据 61 62 count += 1 63 #此处为写入行数累加,province部分循环 64 65 for citiy_data in province_data['cities']: 66 cityname = citiy_data['cityName'] 67 c_confirmedcount = citiy_data['confirmedCount'] 68 c_suspectedcount = citiy_data['suspectedCount'] 69 c_curedcount = citiy_data['curedCount'] 70 c_deadcount = citiy_data['deadCount'] 71 c_locationid = citiy_data['locationId'] 72 #该部分获取某个省下某城市的数据 73 74 worksheet.write(count, 3, cityname) 75 worksheet.write(count, 4, c_confirmedcount) 76 worksheet.write(count, 5, c_suspectedcount) 77 worksheet.write(count, 6, c_curedcount) 78 worksheet.write(count, 7, c_deadcount) 79 worksheet.write(count, 8, c_locationid) 80 #该部分在工作表里写入某城市的数据 81 82 count += 1 83 #此处为写入行数累加,cities部分循环 84 current_time = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()) 85 newworkbook.save('E:人数采集3.0实时采集v3.0-%s.xls' % (current_time)) 86 print('======数据爬取成功======') 87 88 def make_dir(self): 89 file_path = 'E:/人数采集3.0/' 90 if not os.path.exists(file_path): 91 os.makedirs(file_path) 92 print('======数据文件夹不存在=======') 93 print('======数据文件夹创建成功======') 94 print('======创建目录为%s======'%(file_path)) 95 else: 96 print('======数据保存在目录:%s======' % (file_path)) 97 #检查并创建数据目录 98 99 def exe_task(self): 100 times = int(input('执行采集次数:')) 101 interval_time = round(float(input('每次执行间隔时间(分钟)')),1) 102 #round 方法保留一位小数 103 interval_time_min = interval_time * 60 104 105 for i in range(times): 106 get_yq_info().save_data_to_excle() 107 time.sleep(interval_time_min) 108 109 #执行完整采集任务 110 111 get_yq_info().exe_task()
执行: