之前看过TCN,稍微了解了一下语言模型,这篇论文也是对语言模型建模,但是由于对语言模型了解不深,一些常用数据处理方法,训练损失的计算包括残差都没有系统的看过,只是参考网上代码对论文做了粗浅的复现。开学以来通过看的几篇论文及复现基本掌握了tensorflow的基本使用,了解了“数据处理-模型构建-训练“的处理问题基本流程,但是随着看论文的增多发现理论基础严重薄弱,以后应该会一边补理论一边看论文...
一.论文简介
来源:没...没找到
题目:Language Modeling with Gated Convolutional Networks
原文链接:https://arxiv.org/pdf/1612.08083.pdf
参考代码:anantzoid/Language-Modeling-GatedCNN
之前语言模型的主流方法都是基于RNN,本篇论文提出了一种新颖的门控机制,结合CNN网络应用到语言模型。该网络包含多层,与经典语法形式相似,能分层次地分析输入,构建了增加粒度的句法树结构。与RNN逐个处理输入序列不同,CNN可以实现并行计算,大大加快训练速度。并且分层结构也简化了学习,与RNN的链结构相比,非线性计算数量减少,从而减轻了消失梯度问题。
二.网络架构
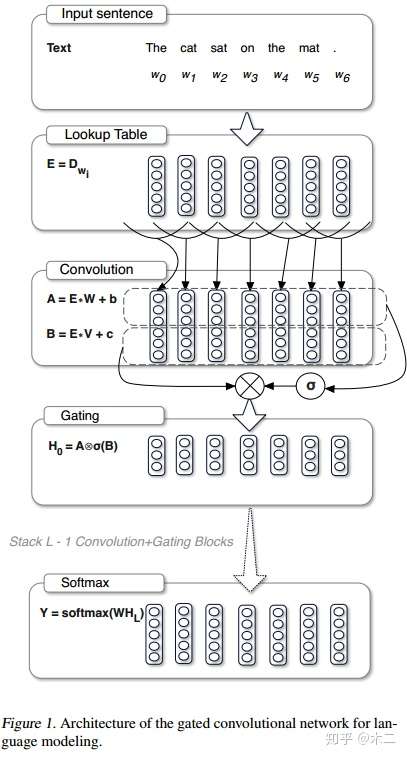
所谓的门限卷积,其核心在于为卷积的激活值添加一个门限开关,来决定其有多大的概率传到下一层去。下面一步步对上图进行解析。
1.将单词embedding到连续空间,即上图中的第二部分Lookup Table。这样,单词序列就能表现为矩阵了。
2.然后是卷积操作,与普通卷积不同,门限卷积在这里分为两部分,一部分是卷积激活值,即B,该处与普通卷积的不同在于没有用Tanh,而是直接线性,但会经过一个sigmoid运算符。另一部分是门限值,即A,A也是直接线性得到。在做卷积的时候,需要不让第i个输出值看到i以后的输入值。这是由语言模型的特性决定的,需要用i之前的信息来预测i。为了达到这样的效果,需要将输入层偏移k - 1个单位,其中k是卷积的宽度,偏移后开头空缺的部分就用0进行padding。
3.接下来是门限单元,A和sigmoid(B)进行element-wise的相乘,得到卷积后的结果。卷积单元和门限单元加起来形成一个卷积层(作者在具体实现里将卷积和门控单元放在一起,形成residual block)。
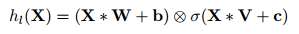
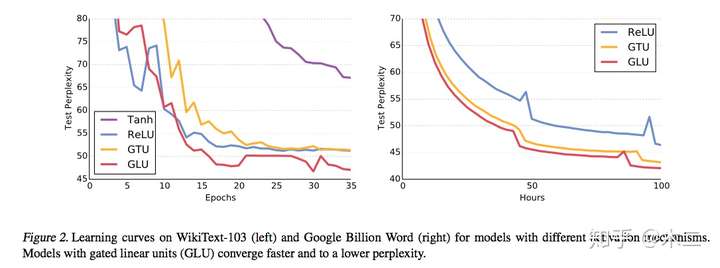
注意,LSTM中有input门和forget门两种,这两种缺一则会导致有些信息的缺失。而卷积中,作者经过实验,提出不需要forget gate。此外,作者对两种门控机制GTU和GLU做了比较:
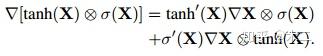 GTU
GTU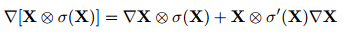 GLU
GLU
作者从梯度的角度对两种门控单元进行了分析,发现GTU会衰减的比较快,因为其梯度公式中包含两个衰减项。而GLU只有一个衰减项,可以较好地减轻梯度弥散。
4.经过多个这样的卷积层之后,再将其输入到softmax中,得到最后的预测。作者提出,在最后的softmax层,普通的softmax会因为词表巨大而非常低效。因而选用adaptive softmax。adaptive softmax可以为高频词分配更多的空间而给低频次分配比较少的空间。
三.实验
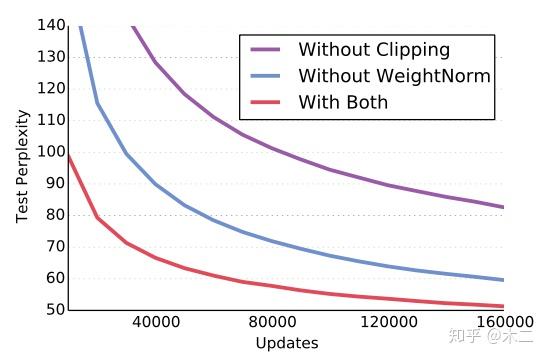
使用Google Billion Word和WikiText-103两种数据集,将perplexity作为衡量结果。使用Nesterov’s momentum算法来训练,momentum设为0.99,作者还使用了weight normalization和gradient clipping来加速收敛。
实验结果如下:
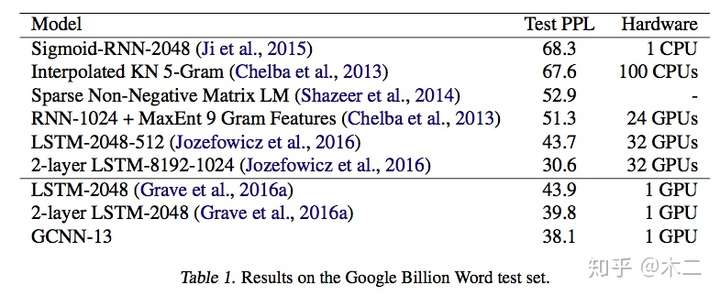
性能测试:
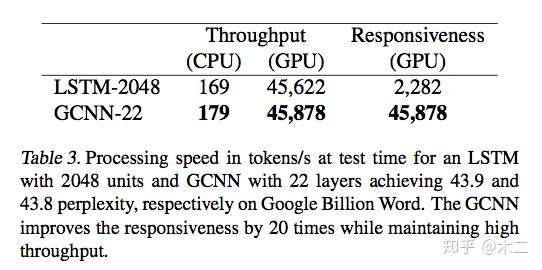
作者使用Throughput和Responsiveness作为衡量标准,Throughput是指在并行化条件下最大输出,Responsiveness是指序列化的处理输入。由表可知,CNN本身的处理速度非常快。而LSTM在并行化后也能拥有很高的速度。究其原因,是在cuDNN中对LSTM有特别的优化,而对1-D convolution却没有。但即便如此,CNN仍然完胜。
门限测试:
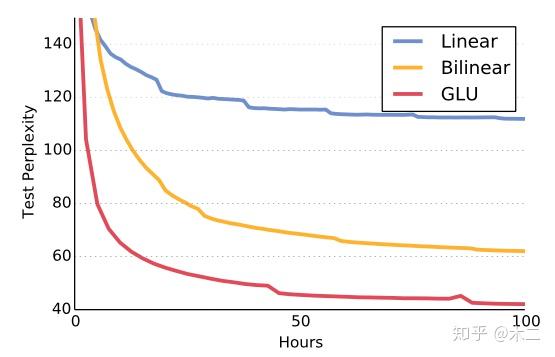
非线性模型测试:
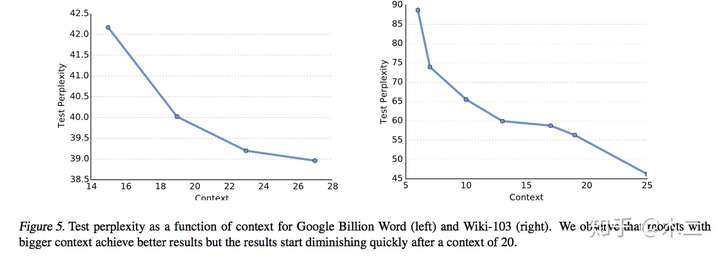
context size测试:
训练测试:
四.总结
这篇文章提出了一种基于卷积神经网络的新颖的门限机制,将其应用到语言模型。与循环神经网络相比,卷积神经网络局部性的特点使得其可以在词序列中进行并行训练,提高了处理的速度,并且分层结构也简化了学习,与RNN的链结构相比,非线性计算数量减少,从而减轻了消失梯度问题,加快了模型的收敛速度。
问题:
主要是针对参考代码的实现有一些疑问。
论文中作者提到,在做卷积的时候,需要不让第i个输出值看到i以后的输入值。这是由语言模型的特性决定的,需要用i之前的信息来预测i。为了达到这样的效果,需要将输入层偏移k - 1个单位,其中k是卷积的宽度,偏移后开头空缺的部分就用0进行padding。代码作者实现的时候在句子开头增加了(k/2)个padding,然后在卷积的时候采用“SAME”模式,这与原文中处理方式不同,并且我认为这样处理是有问题的,这个问题这里有提到,后面对残差部分的修改比较符合我的认知。其次对于代码作者对数据进行分割的方法,在embedding层加mask的方法都不是很理解,不知道针对语言模型问题,数据处理和卷积一般都是怎么操作的,以后慢慢熟悉...
参考:
Language Modeling with Gated Convolutional Networks(句子建模之门控CNN)--模型简介篇
《Language Modeling with Gated Convolutional Networks》阅读笔记