可能很多人都遇到过浮点数精度丢失的问题,下面以JavaScript为例。
1 - 0.9 = 0.09999999999999998
纳尼,不应该是0.1么,怎么变成0.09999999999999998呢?这就要从ECMAScript标准讲起了。
ECMAScript 并不像其他编程语言一样对数值类型进行比较具体的划分。ECMAScript 中并不区分整数和浮点数,也不区分不同长度的整数和浮点数。
ECMAScript 中的 Number 类型始终使用 64 位双精度浮点数来表示数值。这一方面使得处理起来变得简单,另外一方面也限制了可以表示的数值的范围。ECMAScript 中 Number 类型的值的个数是 264-253+3。个数后面的“+3”表示的是 Number 类型的 3 个特殊值,分别是 NaN、+Infinity 和 -Infinity。
NaN 的含义是“不是一个数字(Not-A-Number)”。在代码中可以直接通过“NaN”的方式来引用这个值。代码中与数值相关的计算的结果也可能是 NaN。一般来说,对于 ECMAScript 语言中的操作符,如果其中一个操作数为 NaN,那么计算结果为 NaN。当需要判断一个变量引用 a 是否为 NaN 时,只需要判断 a !== a 是否为 true 即可。+Infinity 和 -Infinity 分别表示正无穷大和负无穷大,可以在代码中直接引用,也可能是某些数值运算的结果。如运算“3 / 0”的结果是 Infinity。除了这 3 个特殊值之外,剩下的数值中一半是正数,一半是负数。数值 0 也有正数和负数两种形式,称为正 0 和负 0,分别用 +0 和 -0 来表示。
讲完了JavaScript的实现标准,现在来了解一下目前最通用的IEEE二进制浮点数算术标准(IEEE Standard for Binary Floating-Point Arithmetic,简称 IEEE 754 标准)。
IEEE 754 标准的主要起草者是加州大学伯克利分校数学系的 William Kahan 教 授,他帮助 Intel 公司设计了 8087 浮点处理器,并以此为基础形成了 IEEE 754 标 准, Kahan 教授也因此获得了 1987 年的图灵奖。Kahan教授的个人主页:https://people.eecs.berkeley.edu/~wkahan/
IEEE 754标准中关于浮点数的四种格式:
- 两种基本的浮点数:单精确度 (32 位字长) 和双精确度 (64 位字长)。其中单精度格式具有 24 位有效数字,而双精度格式具有 53 位有效数字,相对于十进制来说,分别是 7 位 (224 ≈ 107) 和 16 位 (253 ≈ 1016) 有效数字。
- 两种扩展的浮点数:单精度扩展和双精度扩展。此标准并未规定扩展格式的精度和大小,但它指定了最小精度和大小:单精度扩展需 43 位字长以上,双精确度扩展需 79 位字长以上 (64 位有效数字)。单精度扩展很 少使用,而对于双精确度扩展,不同的机器构架中有不同的规定,有的为80 位字长 (X86),有的为 128 位字长 (SPARC)。
这里我们只简单介绍单、双精度,其中重点介绍单精度,双精度与单精度原理是一样的,只是表示的位数长度不同。
浮点数的组成(sign 符号、exponent 指数、fraction 尾数):
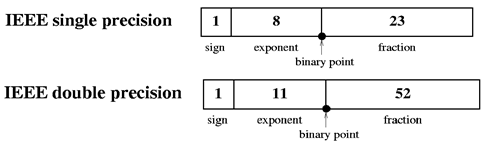
IEEE标准采用类似于科学计数法的方式表示浮点小数,即我们将每一个浮点数表示为 V = (-1)s * M * 2E 。
1)(-1)s表示符号位,当s=0,V为正数;当s=1,V为负数。
2)M 表示有效数字,1 ≤ M < 2。
3)2E 表示指数位。
从公式 V = (-1)s * M * 2E 我们可以得出:
1) 符号位:确定正、负。
2) 尾数的位数:确定精度。
3) 指数的位数:确定所能表示的数的范围。
所谓科学计数法,我举一个例子(左移/右移指数的多少位,我们知道在二进制中左移一位表示乘以2,右移一位表示除以2,当移动N位时就是2N,N可为正也可为负)。
18800000000 = 1.88 x 1010
0.000000000188 = 1.88 x 10 -10
64位的指数位长度为11,32位的指数长度位为8,所以64位双精度所能表示的范围远大于32位。
二进制浮点数是以符号数值表示法的格式存储 —— 最高有效位被指定为符号位(sign bit);“指数部分”,即次高有效的e个比特,存储指数部分;最后剩下的f个低有效位的比特,存储“有效数”(significand)的小数部分(在非规约形式下整数部分默认为0,其他情况下一律默认为1)。
指数偏移值(exponent bias),是指浮点数表示法中的指数域的编码值为指数的实际值加上某个固定的值,IEEE 754标准规定该固定值为 2e-1,其中的 e 为存储指数的比特的长度。单精度为8,双精度为11。所以单精度的固定偏移值是28-1 – 1 = 128 – 1 = 127,而双精度的固定偏移值是211-1 – 1 = 1024 – 1 = 1024。
指数实际的存储:指数的值可能为负数,如果采用补码表示的话,全体符号位S和Exp自身的符号位将导致不能简单的进行大小比较。正因为如此,指数部分通常采用一个无符号的正数值存储。单精度的指数部分是-126 ~ +127,加上固定偏移值127,指数值的大小从1 ~ 254(0和255是特殊值)。浮点小数计算时,指数值减去固定偏移值将是实际的指数大小。
采用指数的实际值加上固定的偏移值的办法表示浮点数的指数,好处是可以用长度为 e 个比特的无符号整数来表示所有的指数取值,这使得两个浮点数的指数大小的比较更为容易,实际上可以按照字典序比较两个浮点表示的大小。这种移码表示的指数部分,中文称作阶码。
针对阶码E的值,浮点数的值可以分为三种不同的类型:规格化数(正规数)、非规格化数(次正规数)、特殊值。
|
单精度格式位模式 |
值 |
|
0 < e < 255 |
(−1)s × 1. f × 2e−127 (正规数) |
|
e = 0, f ≠ 0 |
(−1)s × 0. f × 2−126 (次正规数) |
|
e = 0, f = 0 |
(−1)s × 0.0 (有符号的零) |
|
s = 0, e = 255, f = 0 |
+Infinity (正元穷大,特殊值) |
|
s = 1, e = 255, f = 0 |
+Infinity (负元穷大,特殊值) |
|
e = 255, f ≠ 0 |
NaN (非数、非确定值,特殊值) |

这么讲,还是有点晕,我们通过二个数字的示例来详细说明。
第一个示例:263.3,先拆解一下:263.3 => 整数 263 + 小数0.3
正式开始推算前,先介绍三种十进制转二进制的三种方法:除基取余法、减权定位法、乘基取整法。
三种方法来自中科大《计算机组成原理 | 第6章 计算机的运算方法》的相关资料,这里只介绍除基取余法,因为我们接下来计算的就是用的这个方法。
除基取余法:把给定的数除以基数,取余数作为最低位的系数,然后继续将商部分除以基数,余数作为次低位系数,重复操作,直至商为0。
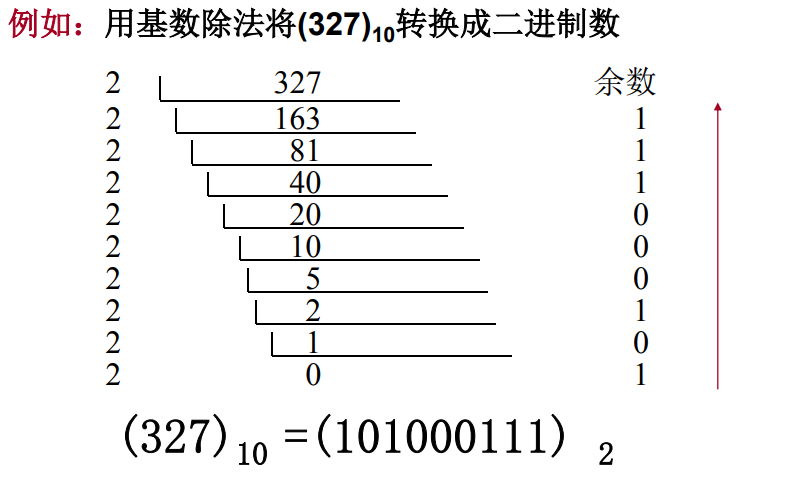
以下推导过程我在纸上写出来了。
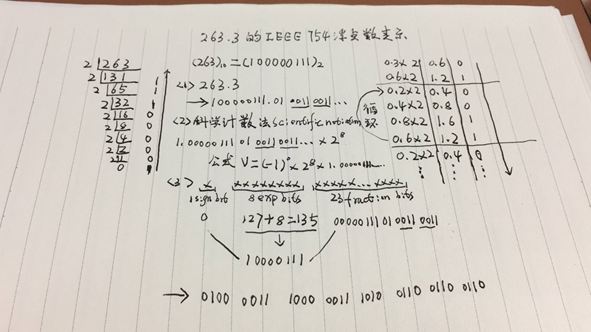
计算结果与官网的进行对比如下。IEEE 754 Floating Point Converter>>
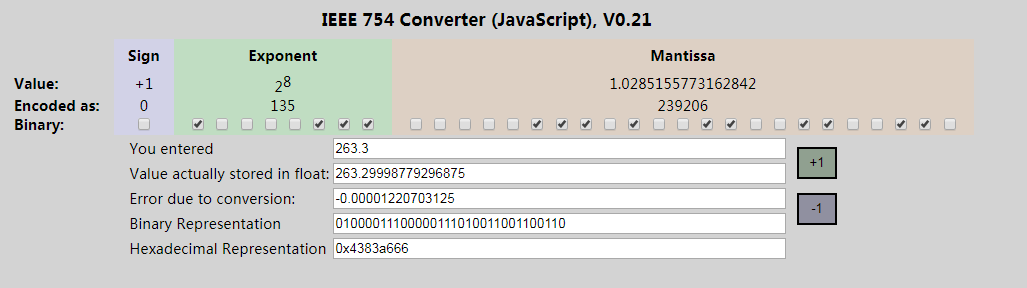
最终的二进制表示:"0100,0011,1000,0011,1010,0110,0110,0110"
同理45.45也可以这样进行计算。(45)10 = (101101)2
45.45 –> 101101.0111001100…(1100循环)
可以使用toString查看十进制转二进制的结果,与上面计算出来的结果进行对比。
Number(45.45).toString(2)
"101101.0111001100110011001100110011001100110011001101"
套公式:V = (-1)s * M * 2E
S = 0 (0)
E = 5 (127 + 5 = 132 –> 10000100)
M = 011010111001100… (1100循环)
最终的二进制表示:"0100,0010,0011,0101,1100,1100,1100,1101"
注意最后一位,变成了1101,进行了舍入操作,上面的263.3也进行了舍入操作。
舍入的规则是怎么定义的呢,我查了很多资料,暂时还没有弄的特别清楚。我搜索到这样一份PPT,供大家参考,其它资料其实与这个说法类似,清华大学的《浮点数误差与误差复杂度》
因为表示方法限制了浮点数的范围和精度,浮点运算只能近似地表示实数运算。IEEE 浮点数格式定义了四种不同的的舍入方式:
1) 向偶数舍入(默认,不是四舍五入)
2) 向零舍入 (取整)
3) 向上舍入 (ceil)
4) 向下舍入 (floor)
向0(截断)舍入:C/C++的类型转换。(int) 1.324 = 1,(int) -1.324 = -1;
向负无穷大(向下)舍入:C/C++函数floor()。例如:floor(1.324) = 1,floor(-1.324) = -2。
向正无穷大(向上)舍入:C/C++函数ceil()。ceil(1.324) = 2。Ceil(-1.324) = -1;



正是因为舍入的存在,误差的存就就成了必然,精确只是偶然的。做数据算法,惟一能做的就是误差不积累。
关于浮点数,还有一些知识点是没有讲的,例如浮点异常:无效运算、被零除、上溢、下溢和不精确,以及相关的一些运算示例。
参考资料:
IEEE-754 Floating Point Converter
Decimal to IEEE 754 Floating Point Representation