基于二元模型的拼音输入法
前言
我曾经写过leetcode上一些经典的动态规划算法题的思路,都是停留在算法题的层面。这次提供一个入手简单的应用实例,基于二元模型的拼音输入法。
场景/问题
这个应用实例的场景很简单,提供一个拼音字符串(当然要用空格隔开),返回对应的汉字字符串(只允许输出一个,当然这里不太符合实际的拼音输入法程序,一般的拼音输入法程序都会给出若干个备选字符串)。如:输入bei jing you dian da xue ,输出 北京邮电大学。
背景
通常这种序列模型问题都可以使用隐马尔科夫模型或者马尔可夫决策过程来设计解决方案(这两种方案的实现实际上就是动态规划算法,然而我们一般不这么叫它们),也可以使用基于动态规划的DAG来解决(jieba所使用的基于动态规划的最大概率分词算法和这个有点像)。这里提供基于二元模型的解决方式,并且分别使用两种不同的策略来解决这个问题。
思路
有一个最简单的思路,找到一个庞大的语料库,统计每个拼音对应的每个字在该语料库中的出现频率,以频率近似为概率,从最大概率的角度出发,处理每个拼音的时候,只需选择该拼音下概率最大的字。但是这种方式有显而易见的问题,每个拼音间并非独立,即没有考虑语义,如果贪心的选择每个拼音下概率最大的字,必然会导致准确率的问题。举一个不太恰当的例子,比如he下概率最大的字为和,shui下概率最大的字为水,输入he shui,按照贪心选择的方式会输出 和水。这个结果不能说错,但是应该也不算是多么准确的结果……
二元模型
前面的那个思路并没有考虑拼音间的语义,实际上这种语义是该拼音对应的字符串带来的。这里我们考虑最简单的一种语义方式,二元语义模型,即考虑前一个字或者词确定了的情况下,现在这个字或者词最有可能出现的情况,依次考虑输入的拼音串中的每一个前后对,就是在求解一连串共现概率乘积的最大值,这么解释比较跳跃抽象,下面给出一个我认为比较清楚的例子。
比如输入:ji qi xue xi
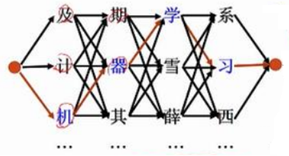
假设 ji 对应的所有汉字的集合为{及,计,机},qi对应的所有汉字的汉字集合为{期,器,其}
xue对应的所有汉字的集合为{学,雪,薛},qi对应的所有汉字的集合为{系,习,西}
(这里只是为了方便举例才写了这么有限几个字,请不要抬杠)
图中的每一个箭头表示一个共现概率,比如 机---->器 表示机先出现器后出现的共现概率,根据条件概率的计算公式有:
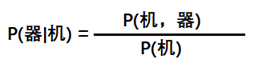
其中P(机)表示 机 的字频即出现频率。(当然这么表示实际上是有一点问题的,比如说:P(机,器)其实应该表示机和器同时出现的概率,包括 机前器后 和 器前机后,这里默认P(机,器)表示机前器后这样出现的概率。不过我个人认为这里这么表示无伤大雅,能看懂即可)
当考虑qi时,要分别考虑 期,器,其 3种情况。具体讲考虑qi选择 器 时,要通过查看P(器|机)*P(选择 机),P(器|计) *P(选择 计),P(器|及) *P(选择 及)来考虑 器 要接在 及,计,机 哪个字后面的可能性最大,三者的最大值即为P(选择 器),存储这个最大的概率值和对应的选择方案;当考虑xue时,要分别考虑 学,雪,薛 3种情况。具体讲考虑xue选择 学 时,要通过查看P(学|器) *P(选择 器),P(学|期) *P(选择 期),P(学|其) *P(选择 其)来考虑 学 要接在 期,器,其 哪个字后面的可能性最大,三者的最大值即为P(选择 学),存储这个最大的概率值和对应的选择方案;当考虑xi时,要分别考虑 系,习,西 3种情况。具体讲考虑xi选择 习 时,要通过查看P(习|学) *P(选择 学),P(习|雪) *P(选择 雪),P(习|薛) *P(选择 薛)来考虑 学 要接在 学,雪,薛 哪个字后面的可能性最大,三者的最大值即为P(选择 习),存储这个最大的概率值和对应的选择方案。当考虑完xi的所有情况后,整个拼音串的所有情况已经枚举完了,只需要看xi所有选择的概率,即P(选择 习),P(选择 系),P(选择 西),谁大选谁即可。如果P(选择 习)最大且对应的选择方案为[ 机 器 学 习 ],那我们就把 机 器 学 习 当作结果输出。
这里单独把首部拿出来分析,在这个例子中也就是ji中分别选择 及,计,机 的概率。在一般情况下,对于拼音输入法,输入的拼音串对应的汉字字符串,可能是一句完整的话,可能是一个完整的词,但也有可能既不是完整句子也不是完整词,而是形如 用手 这种中断的语段,如果只考虑字出现在句首或者词首的概率会影响算法的运行结果。当然如果你认为 用手 也算一个完整的词或句子,或者说中文语义中可以称为词汇或句子的语段太多了,实在没办法统计所有词的词首的概率(因为没有可行办法进行枚举)。对于这个问题,我个人更加倾向于,输入串想要得到的汉字字符串,更像是随机地从人脑海里的语料库中截取出的,从哪个位置开始截取并不十分确定(也许并不是随机的截取出的,但是也会出现我上面分析的这种情况,即首部并不是一个句首或者词首),所以干脆把首部这个字的字频作为它在这个算法中的共现概率,字频算是对三种情况的一种折中且最简单的解决方式。当然这个处理只是我个人对这个问题的理解,实际上这并不是一个完美的解决方法,因为字频作为统计了一个字出现在任何地方的量,自然也包括它出现在语段末尾的情况,不过这又是个值得讨论的问题,既然无法枚举所有的句子和词汇,又怎么能十分确定的说明某个字就一定会出现在末尾呢?看到这里你可能还会反驳说某个具体的语料库是可以确定词句的首末的。我对此表示,你完全可以试一试,对比一下哪种解决方案更好。
为了保证例子说明必要的完整性,我重复一下,如果按照我的解决方案,首部ji的三种情况,分别初始化为:P(选择 及) = P(及),P(选择 计) = P(计),P(选择 机) = P(机)
从我上述不厌其烦的对ji qi xue xi 这个例子较为完整的解决过程的叙述中,应该可以看出这个算法的运行过程实际上就是一个应用的动态规划过程,首先确定起始阶段(第一个拼音)所有备选方案(每个字的字频)的值,然后开始枚举后续每个阶段(后面的每个拼音)所有备选方案(以每个字为结尾的概率和对应的选择方案)。当枚举完所有的阶段后,从最后一个阶段中选择最佳方案即可。这个过程与一般的动态规划问题没什么区别(比如入门题装配线问题),最大的区别可能就在于,大部分的算法题只需要你把这个最大的概率输出,而一个实际应用更关心这个最大概率对应的选择方案,我们需要额外空间来存储方案,这里的实现因人而异,包括dp数组可以使用滚动数组,方案的存储也可以使用更加节省空间的设计。本篇随笔的结尾处我会提供一份没有经过空间优化的代码。
基于字的二元模型
上面一节的长篇大论实际上就是基于每个字的二元模型进行展开的。在理清了算法的流程后,就需要训练了。我个人认为这个当然算一个机器学习问题,因为有着太多的统计学习的东西在里面。我们回顾一下,以往的动态规划算法题,那些权重或者转移概率可是需要输入的,而这个例子中的这些共现概率和字频需要从收集的语料库中统计,这里需要额外写程序,不过这部分代码很好实现。有过有一些需要注意的点,首先有些字的字频可能为0,就是说这个字作为一个生僻字虽然在拼音汉字表中出现了,但是用于训练的语料库中并没有出现,其次有些前后字的组合共现次数为0。对于这两种情况,可以使用平滑方式进行处理
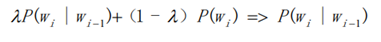
不过这样会引入一个超参数。我个人倾向于给这些0赋一个特别特别小的概率。还有动态规划的过程中涉及到概率的乘积,这些概率或者统计出来的频率都是相对较小的数,多个小数的乘积会影响精度,可以提前使用log函数处理,将求乘积转化为求和,这也是一个比较常见的技巧。
基于词的二元模型
基于字的语义还是缺了点东西,因为很多字虽然也是前后出现,可并不具有语义上的必然性,尽管某些关联不大的前后字组合的共现概率很低,但仍然可能会对结果产生影响。既然这样,我们以更具有语义的词来分析。
算法的大体过程不变,只是从考虑字到考虑词的转变。首先要枚举输入拼音串中,以每个拼音为结尾的所有词的集合。基于字的二元模型我们要考虑每个拼音下所有字的情况,而基于词的二元模型我们要考虑在该拼音串中以该拼音结尾的所有词的情况。
还用ji qi xue xi 来举例:假设ji对应的所有汉字的集合为{及,计,机},qi对应的所有汉字的汉字集合为{期,器,其} ,xue对应的所有汉字的集合为{学,雪,薛},qi对应的所有汉字的集合为{系,习,西}。词汇表为{机器学习,机器,学习,及其,及,计,机,期,器,其,学,雪,薛,系,习,西}。则ji对应的状态集合为{及,计,机},qi对应的状态集合为{及其,机器,期,器,其},xue对应的状态集合为{学,雪,薛},xi对应的状态集合为{系,习,西,学习,机器学习}。
起始阶段使用词频作为共现频率,P(选择 及) = P(及),P(选择 计) = P(计),P(选择 机) = P(机)。注意这里P(及)表示的是 及 这个词的词频,单字也算词。
当考虑qi时,要分别考虑{及其,机器,期,器,其}几种情况,这里就和基于字的二元模型有一定的区别了,比如考虑 及其 时,前面已经没有别的任何词了,这里的情况,有点像有些算法题中,dp[i] = sum[1,i]+dp[0]这种情况,就是已经顶格了,这时只需要将P(选择 及其) = P(及其)即可;考虑 机器 也是同样的情况;考虑 器 时,查看P(器|机)*P(选择 机),P(器|计) *P(选择 计),P(器|及) *P(选择 及),从中选择最大。这里就只描述这两种情况,这两种情况是整个算法枚举过程中会出现的唯二的两种情况,其他情况与其无异,可依此类推。
在训练时,除了拼音汉字表和语料库,还需要对语料库中的句子进行分词,还要组织一个词库,将词库中每个词的拼音组合标注出来。分词是为了统计词频和共现概率,标注拼音是为了建立词与拼音的关系(说白了你得知道拼音对应的词,比如ying xiong下一定有词汇英雄),只有单字词标注了拼音。这两个任务人来做费时费力,然而从逻辑上讲确实需要人来做,交给程序做会引入新的问题,尤其是分词任务其实和本实例涉及到的问题非常相似。但好在有jieba和pypinyin这两个第三方库,它们在分词和注音上的表现已与人类的表现无异,为了节省时间可以使用这两个库进行处理,把处理结果当成是人为处理的结果(反正程序做和人为做的结果差不多)。然后再去统计词频和共现概率。需要注意的问题和基于字的二元模型一样,这里不再赘述。
表现
由于是建立在统计学习基础上的算法,所以程序的实际表现跟选择的语料库息息相关,说白了谁的组合概率大就选择谁。我选择的语料库是sina新闻,所以正式的表达更多,口头表达要少一些,因此对于一些常见于新闻报刊的词汇或者句子都可以准确的输出,而对于日常表达的句子表现可能要差一些。下面提供了三组表现对比,来说明训练的结果,并简单分析。
比如:liang hui zai bei jing zhao kai,两版程序都可以准确地输出:两会在北京召开。这并不意外,因为这就是新闻稿中的常见语句,统计阶段确实学习到了这些特征。
比如:jin tian hui jia bi jiao wan 基于字的二元模型输出:今天回家比较完,有一定的偏差,而基于词的二元模型可以准确输出:今天回家比较晚。这句话就比较贴近日常生活,基于字的二元模型由于只是单纯考虑前后字的共现关系,语义的特征捕获的不够明确,容易出现偏差。同时据统计,在我使用的整个语料库中,比较完整 出现的次数比 比较晚 出现的次数要多出不少,这种最大概率的选择也影响了程序的输出,可见统计学习方法容易受训练数据的影响,数据的分布可以左右结果。而基于词的二元模型可以更多地考虑语义信息,可以抑制单字的影响。比较完整这个语段,按照语义应该分为 比较 和 完整 两个词,而不能像基于词的二元模型那样简单的将每个字拆解,显然如果进行简单的单字拆解是不符合语义的。同样,比较晚这个语段,按照语义划分为比较 和 晚 显然更加合适。这个例子可以充分展示出基于词的二元模型是要比基于字的二元模型要强大的。
比如:he xue bi,两版程序的表现都不佳,均没有输出理想答案 喝雪碧。这个主要是因为语料库中确实缺少这样的语料,无法学习到这些特征,对于没见过的组合,程序的输出也只是会根据最大概率的方式进行选择,这必然不会取得理想结果。
总结/展望
二元模型的解决方式我认为应该算是隐马尔科夫模型的范畴内,基于字的模型由于无法捕获和学习到更多的语义信息所以其表现是不如基于词的模型强大的。进一步可以考虑三元甚至四元模型,但我个人认为增元获得的表现提升不一定会很理想,比如在目前的语料中,无论三元字模型还是四元字模型对于 jin tian hui jia bi jiao wan这个例子还是没什么办法的,同理三元词也拿he xue bi 这样的例子没辙。更加具有语义多样性的语料库对于训练和学习特征非常关键。当然这实际上也可以当作是一个机器翻译问题,直接使用TransFormer等Seq2Seq的SOTA模型我认为也没有什么不可。
代码/重头戏
非常感谢你能够坚持看到这里,以下是我的代码。关于统计部分的代码我没有提供。代码实现的细节和风格可能不太符合你的胃口,请见谅。
1 #基于字的二元模型,动态规划的部分我已经在正文部分描述的自认为很详细了,所以没有编写备注 2 3 import numpy as np; 4 import json; 5 import sys; 6 7 def process(pins,params): 8 c_freq = params['c_freq']; 9 freq = params['freq']; 10 pin2idx = params['pin2idx']; 11 idx2token = params['idx2token']; 12 pinlst = params['pinlst']; 13 seqlst = []; 14 for pin in pins: 15 seqlst.append(pin2idx[pin]); 16 dp = []; 17 mem = []; 18 seq0_score = []; 19 seq0_mem = []; 20 for i in pinlst[seqlst[0]]: 21 seq0_score.append(freq[i]); 22 seq0_mem.append([[i]]); 23 dp.append(seq0_score); 24 mem.append(seq0_mem); 25 for zt in range(1,len(seqlst)): 26 cur = seqlst[zt]; 27 pre = seqlst[zt-1]; 28 dp_temp = []; 29 mem_temp = []; 30 for i in pinlst[cur]: 31 maxn = -float('inf'); 32 temp = []; 33 for j in range(len(pinlst[pre])): 34 if maxn<dp[zt-1][j]+c_freq[pinlst[pre][j],i]: 35 maxn = dp[zt-1][j]+c_freq[pinlst[pre][j],i]; 36 temp.clear(); 37 temp.append(j); 38 elif maxn == dp[zt-1][j]+c_freq[pinlst[pre][j],i]: 39 temp.append(j); 40 dp_temp.append(maxn); 41 mem_tt = []; 42 for pos in temp: 43 for lst in mem[zt-1][pos]: 44 mem_tt.append(lst+[i]); 45 mem_temp.append(mem_tt); 46 dp.append(dp_temp); 47 mem.append(mem_temp); 48 ans = ''; 49 maxn = -float('inf'); 50 temp = []; 51 for pos,val in enumerate(dp[len(seqlst)-1]): 52 if maxn<val: 53 maxn = val; 54 temp.clear(); 55 temp.append(pos); 56 elif maxn == val: 57 temp.append(pos); 58 for idx in mem[len(seqlst)-1][temp[0]][0]: 59 ans = ans+idx2token[idx]; 60 return ans; 61 62 def read_batch(path): 63 ret = []; 64 f = open(path,'r',encoding='utf-8'); 65 line = f.readline(); 66 while line: 67 ret.append(line.replace(' ', '').split(' ')); 68 line = f.readline(); 69 f.close(); 70 return ret; 71 72 def batch_process(seq_pins,params): 73 ans = []; 74 for pins in seq_pins: 75 ans.append(process(pins,params)); 76 return ans; 77 78 def initialize(): 79 print('开始读取模型...'); 80 f = open('params.json', 'r', encoding='utf-8'); 81 params = json.load(f); 82 f.close(); 83 freq = np.load('freq-debug-v2.npy'); 84 c_freq = np.load('c_freq-debug-v2.npy'); 85 params['freq'] = freq; 86 params['c_freq'] = c_freq; 87 print('模型读取结束!'); 88 return params; 89 90 91 def pin2token(path='input-test.txt'): 92 seq_pins = read_batch(path); 93 params = initialize(); 94 return batch_process(seq_pins,params);
1 #基于词的二元模型,总之我就是没有写注释。。。 2 3 import numpy as np; 4 import json; 5 import sys; 6 7 def process(pins,params): 8 pin2idx = params['pin2idx']; 9 word2idx = params['word2idx']; 10 freq = params['freq']; 11 c_freq = params['c_freq']; 12 cw2idx = params['cw2idx']; 13 pinlst = params['pinlst']; 14 idx2word = params['idx2word']; 15 dp = []; 16 mem = []; 17 state = []; 18 state_map = []; 19 lower = -100; 20 for pos1 in range(len(pins)): 21 stat = []; 22 stat_map = {}; 23 for pos2 in range(0,pos1+1): 24 idx = isWord(pos2,pos1,pins,pin2idx); 25 if idx!=-1: 26 for st in pinlst[idx]: 27 stat.append([idx2word[st],pos2]); 28 stat_map[idx2word[st]] = len(stat)-1; 29 state.append(stat); 30 state_map.append(stat_map); 31 for pos1 in range(len(pins)): 32 dp_temp = []; 33 mem_temp = []; 34 for word2,pos in state[pos1]: 35 maxn = -float('inf'); 36 lst = []; 37 if pos!=0: 38 for word1,_ in state[pos-1]: 39 if word1 in cw2idx and word2 in cw2idx[word1]: 40 tp = cw2idx[word1][word2]; 41 xp = state_map[pos-1][word1]; 42 if maxn < dp[pos-1][xp] + c_freq[tp]: 43 maxn = dp[pos-1][xp] + c_freq[tp]; 44 lst.clear(); 45 for t_lst in mem[pos-1][xp]: 46 lst.append(t_lst+[word2]); 47 elif maxn == dp[pos-1][state_map[pos-1][word1]] + c_freq[tp]: 48 for t_lst in mem[pos-1][state_map[pos-1][word1]]: 49 lst.append(t_lst+[word2]); 50 else: 51 if maxn < dp[pos-1][state_map[pos-1][word1]] + lower: 52 xp = state_map[pos - 1][word1]; 53 maxn = dp[pos-1][xp] + lower; 54 lst.clear(); 55 for t_lst in mem[pos-1][xp]: 56 lst.append(t_lst+[word2]); 57 elif maxn == dp[pos-1][state_map[pos-1][word1]] + lower: 58 for t_lst in mem[pos-1][state_map[pos-1][word1]]: 59 lst.append(t_lst+[word2]); 60 else: 61 if maxn < freq[word2idx[word2]]: 62 maxn = freq[word2idx[word2]]; 63 lst.clear(); 64 lst.append([word2]); 65 elif maxn == freq[word2idx[word2]]: 66 lst.append([word2]); 67 dp_temp.append(maxn); 68 mem_temp.append(lst); 69 dp.append(dp_temp); 70 mem.append(mem_temp); 71 maxn = -float('inf'); 72 temp = []; 73 for pos,val in enumerate(dp[len(pins)-1]): 74 if val > maxn: 75 maxn = val; 76 temp.clear(); 77 temp.append(pos); 78 elif val==maxn: 79 temp.append(pos); 80 words = mem[len(pins)-1][temp[0]][0]; 81 ans = ''; 82 for word in words: 83 ans = ans+word; 84 return ans; 85 86 def isWord(start,end,pins,pin2idx): 87 ans = pins[start]; 88 for i in range(start+1,end+1): 89 ans = ans+' '+pins[i]; 90 if ans in pin2idx: 91 return pin2idx[ans]; 92 else: 93 return -1; 94 95 96 97 def read_batch(path): 98 ret = []; 99 f = open(path,'r',encoding='utf-8'); 100 line = f.readline(); 101 while line: 102 ret.append(line.replace(' ', '').split(' ')); 103 line = f.readline(); 104 f.close(); 105 return ret; 106 107 def batch_process(seq_pins,params): 108 ans = []; 109 for pins in seq_pins: 110 ans.append(process(pins,params)); 111 return ans; 112 113 def initialize(): 114 print('开始读取模型...'); 115 f = open('p.json', 'r', encoding='utf-8'); 116 params = json.load(f); 117 f.close(); 118 w_freq = np.load('w_freq-debug-v2.npy'); 119 cw_freq = np.load('cw_freq.npy'); 120 params['freq'] = w_freq; 121 params['c_freq'] = cw_freq; 122 f = open('cw_freq-debug.json', 'r', encoding='utf-8'); 123 params['cw2idx'] = json.load(f)['cw_freq-debug']; 124 print('模型读取结束!'); 125 return params; 126 127 def pin2token(path='input-test.txt'): 128 seq_pins = read_batch(path); 129 params = initialize(); 130 return batch_process(seq_pins,params);
后记
这篇随笔中可以有诸多错别字或者表达不流畅、不严谨之处,敬请谅解。
如果你看了这篇流水账感觉很不爽,谢谢你能够看完,但请不要私信我。
如果你看了这篇流水账感觉很有意思,认为可以交个朋友,可以私信我。
如果你看了这篇流水账感觉很有帮助,谢谢你的认可,如果需要语料库和统计好的权重数据,可以私信我。