-
配置环境要求:
- Centos7
- jdk 8
- Vmware 14 pro
- hadoop 3.1.1
-
Hadoop下载

-
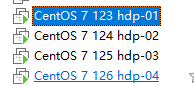
安装4台虚拟机,如图所示
-
-
克隆之后需要更改网卡选项,ip,mac地址,uuid

- 重启网卡:
-
为了方便使用,操作时使用的root账户
-
设置机器名称

-
再使用hostname命令,观察是否更改
类似的,更改其他三台机器hdp-02、hdp-03、hdp-04。
-
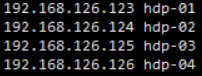
在任意一台机器Centos7上修改域名映射
- vi /etc/hosts
- 修改如下
-
使用scp命令发送其他克隆机上 scp /etc/hosts 192.168.126.124:/etc/
-
给四台机器生成密钥文件
 确认生成。
确认生成。- 把每一台机器的密钥都发送到hdp-01上(包括自己)

 将所有密钥都复制到每一台机器上
将所有密钥都复制到每一台机器上
-
在每一台机器上测试
- 无需密码则成功,保证四台机器之间可以免密登录

-
安装Hadoop
- 在usr目录下创建Hadoop目录,以保证Hadoop生态圈在该目录下。
- 使用xsell+xFTP传输文
-
解压缩Hadoop

-
配置java与hadoop环境变量
1 export JAVA_HOME=/usr/jdk/jdk1.8.0_131 2 export JRE_HOME=${JAVA_HOME}/jre 3 export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib 4 export PATH=${JAVA_HOME}/bin:$PATH 5 6 export HADOOP_HOME=/usr/hadoop/hadoop-3.1.1/ 7 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
注意:以上四台机器都需要配置环境变量
-
修改etc/hadoop中的配置文件
注:除了个别提示,其余文件只用修改hdp-01中的即可
- 修改core-site.xml
1 <configuration> 2 <property> 3 <name>fs.defaultFS</name>
<!-- 注意别的slave机需要识别master主机名,否则将不能与主机hdp-01沟通 -->
4 <value>hdfs://hdp-01:9000</value> 5 </property> 6 <property> 7 <name>hadoop.tmp.dir</name> 8 <!-- 以下为存放临时文件的路径 --> 9 <value>/opt/hadoop/hadoop-3.1.1/data/tmp</value> 10 </property> 11 </configuration> -
修改hadoop-env.sh
1 export JAVA_HOME=/usr/jdk/jdk1.8.0_131注:该步骤需要四台都配置
-
修改hdfs-site.xml
1 <configuration> 2 <property> 3 <name>dfs.namenode.http-address</name> 4 <!-- hserver1 修改为你的机器名或者ip --> 5 <value>hdp-01:50070</value> 6 </property> 7 <property> 8 <name>dfs.namenode.name.dir</name> 9 <value>/hadoop/name</value> 10 </property> 11 <property> 12 <name>dfs.replication</name> 13 <!-- 备份次数 --> 14 <value>1</value> 15 </property> 16 <property> 17 <name>dfs.datanode.data.dir</name> 18 <value>/hadoop/data</value> 19 </property> 20 21 22 </configuration>
-
修改mapred-site.xml
1 <configuration> 2 <property> 3 <name>mapreduce.framework.name</name> 4 <value>yarn</value> 5 </property> 6 </configuration>
-
修改 workers
1 hdp-01 2 hdp-02 3 hdp-03 4 hdp-04
-
修改yarn-site.xml文件
1 <configuration> 2 3 <!-- Site specific YARN configuration properties --> 4 <property> 5 <name>yarn.resourcemanager.hostname</name> 6 <value>hdp-01</value> 7 </property> 8 <property> 9 <name>yarn.nodemanager.aux-services</name> 10 <value>mapreduce_shuffle</value> 11 </property> 12 <property> 13 <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> 14 <value>org.apache.hadoop.mapred.ShuffleHandler</value> 15 </property> 16 <property> 17 <name>yarn.nodemanager.resource.cpu-vcores</name> 18 <value>1</value> 19 </property> 20 21 </configuration>
注:可以把整个/usr/hadoop目录所有文件复制到其余三个机器上 还是通过scp 嫌麻烦的可以先整一台机器,然后再克隆
-
启动Hadoop
-
在namenode上初始化
因为hdp-01是namenode,hdp-02、hdp=03和hdp-04都是datanode,所以只需要对hdp-01进行初始化操作,也就是对hdfs进行格式化。
执行初始化脚本,也就是执行命令:hdfs namenode -format
等待一会后,不报错返回 “Exiting with status 0” 为成功,“Exiting with status 1”为失败
-
在namenode上执行启动命令
直接执行start-all.sh 观察是否报错,如报错执行一下内容
$ vim sbin/start-dfs.sh
$ vim sbin/stop-dfs.sh在空白位置加入
1 HDFS_DATANODE_USER=root 2 3 HADOOP_SECURE_DN_USER=hdfs 4 5 HDFS_NAMENODE_USER=root 6 7 HDFS_SECONDARYNAMENODE_USER=root
$ vim sbin/start-yarn.sh
$ vim sbin/stop-yarn.sh在空白位置加入
1 YARN_RESOURCEMANAGER_USER=root 2 3 HADOOP_SECURE_DN_USER=yarn 4 5 YARN_NODEMANAGER_USER=root
$ vim start-all.sh
$ vim stop-all.sh
1 TANODE_USER=root 2 HDFS_DATANODE_SECURE_USER=hdfs 3 HDFS_NAMENODE_USER=root 4 HDFS_SECONDARYNAMENODE_USER=root 5 YARN_RESOURCEMANAGER_USER=root 6 HADOOP_SECURE_DN_USER=yarn 7 YARN_NODEMANAGER_USER=root
配置完毕后执行start-all.sh
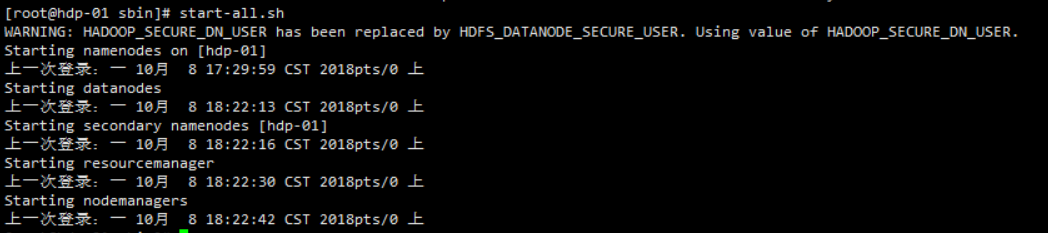
运行jps
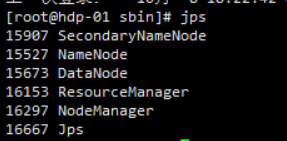
显示6个进程说明配置成功
- 去浏览器检测一下 http://hdp-01:50070
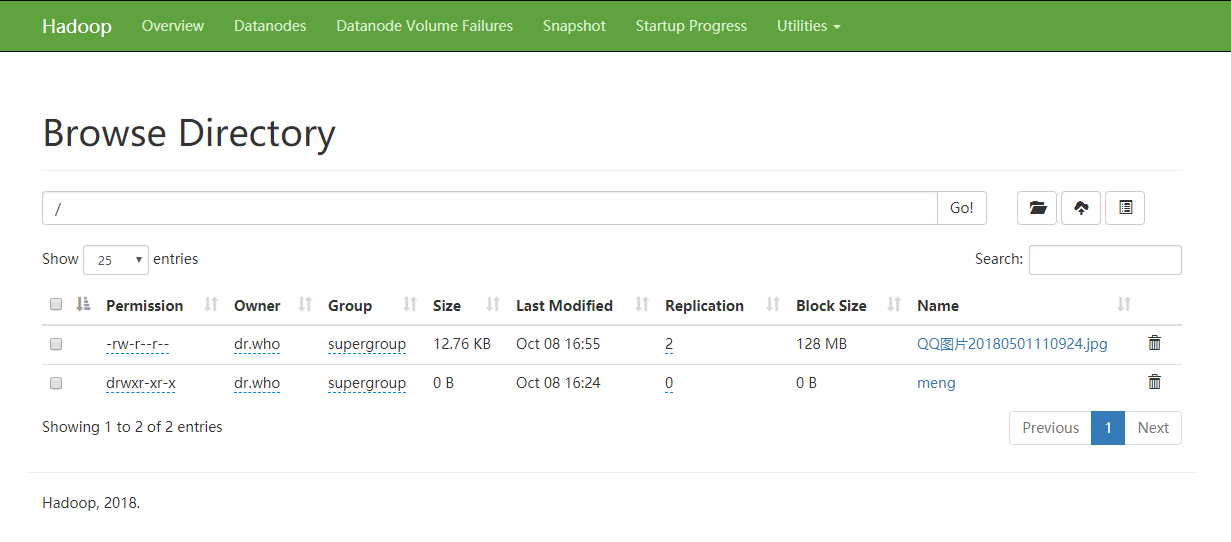
创建目录 上传不成功需要授权
hdfs dfs -chmod -R a+wr hdfs://hdp-01:9000/
-
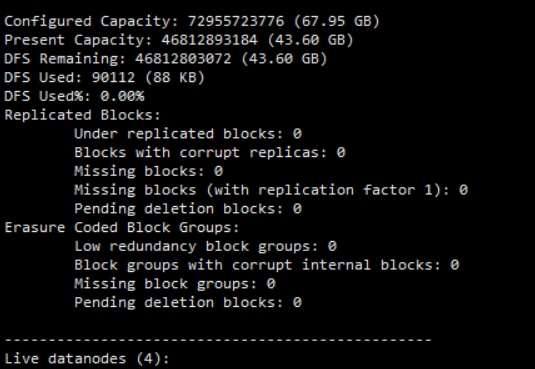
//查看容量
hadoop fs -df -h /
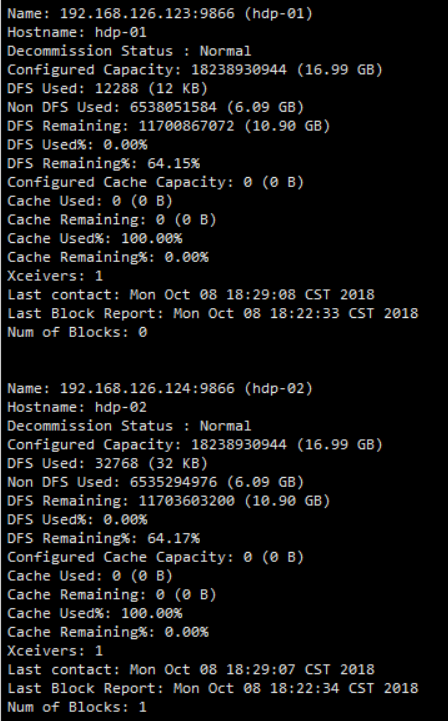
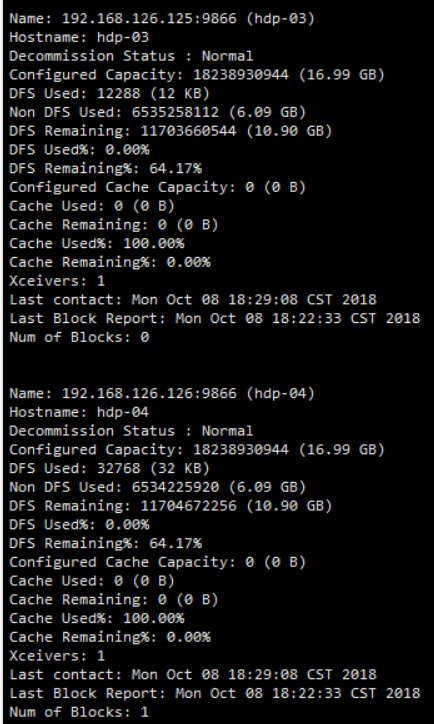
- 查看各个机器状态报告
hadoop dfsadmin -report