使用Jsoup解析HTML
那么我们就必须用到HttpClient先获取到html
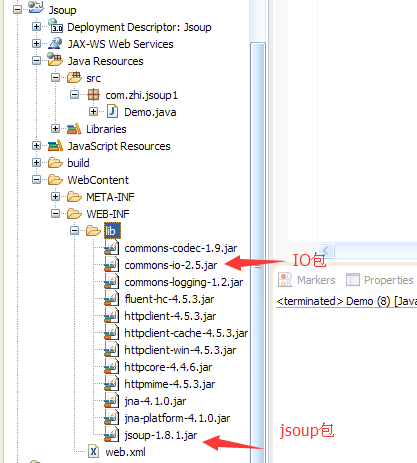
同样我们引入HttpClient相关jar包
以及commonIO的jar包
我们把httpClient的基本代码写上,然后解析网页 得到文档对象
我们获取title和制定id的文档对象
代码实例:
package com.zhi.jsoup1;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Demo {
public static void main(String[] args) throws Exception {
CloseableHttpClient httpClient=HttpClients.createDefault(); //1、创建实例
HttpGet httpGet=new HttpGet("https://home.cnblogs.com/u/mengxinrenyu/"); //2、创建实例
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0");
CloseableHttpResponse httpResponse=httpClient.execute(httpGet); //3、执行
HttpEntity entity=httpResponse.getEntity(); //4、获取实体
String content=EntityUtils.toString(entity, "utf-8"); //5、获取网页内容
httpResponse.close();
httpClient.close();
Document doc=Jsoup.parse(content); // 解析网页 得到文档对象
Elements elements=doc.getElementsByTag("title"); // 获取tag是title的所有DOM元素
Element element=elements.get(0); // 获取第1个元素
String title=element.text(); // 返回元素的文本
System.out.println("标题:"+title);
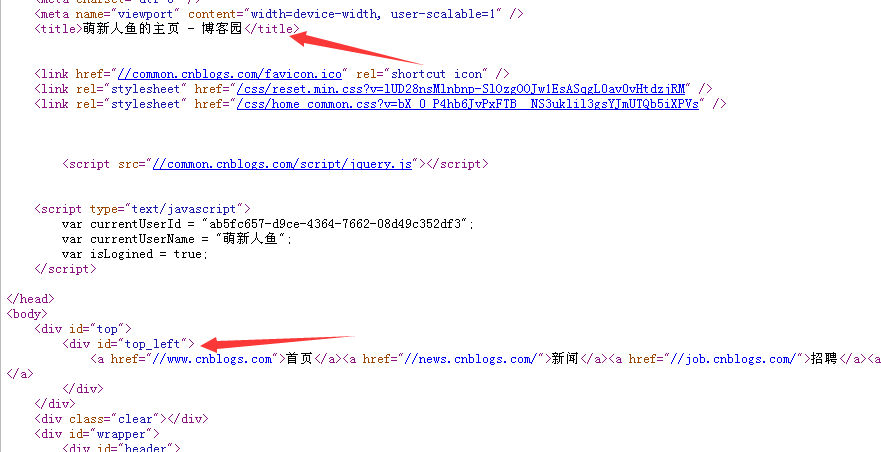
element=doc.getElementById("top_left"); // 获取id=top_left的DOM元素
String menu=element.text(); // 返回元素的文本
System.out.println("导航:"+menu);
}
}
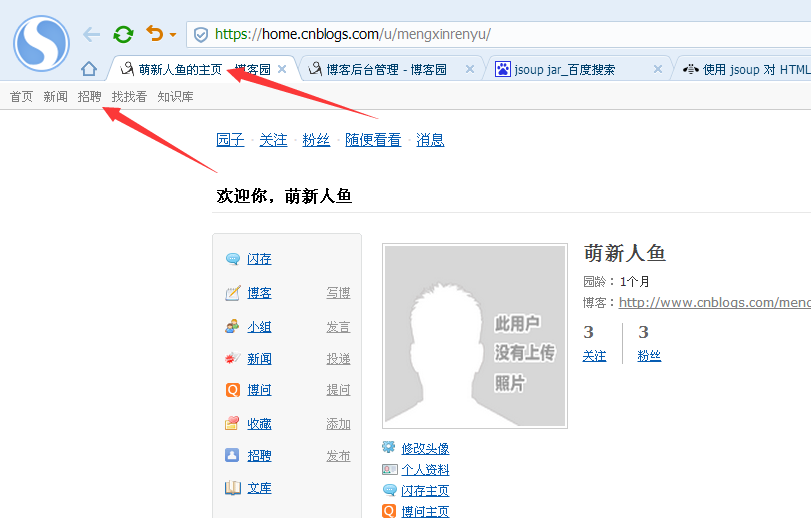
由于网页我是登陆以后的,所以会出现以下错误
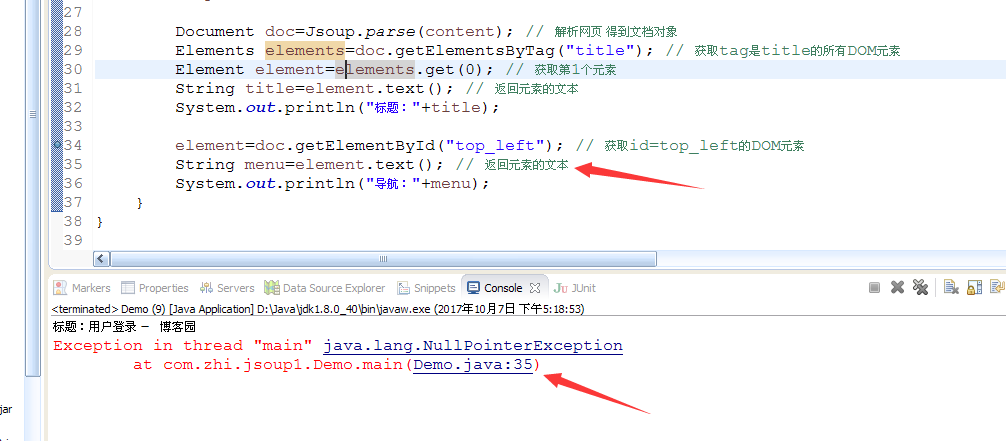
因为请求的是某个登陆账户下的网页,所以网页会提示登录。从没没有相应id的元素,返回NPE。
我们换一个新闻页面试一下

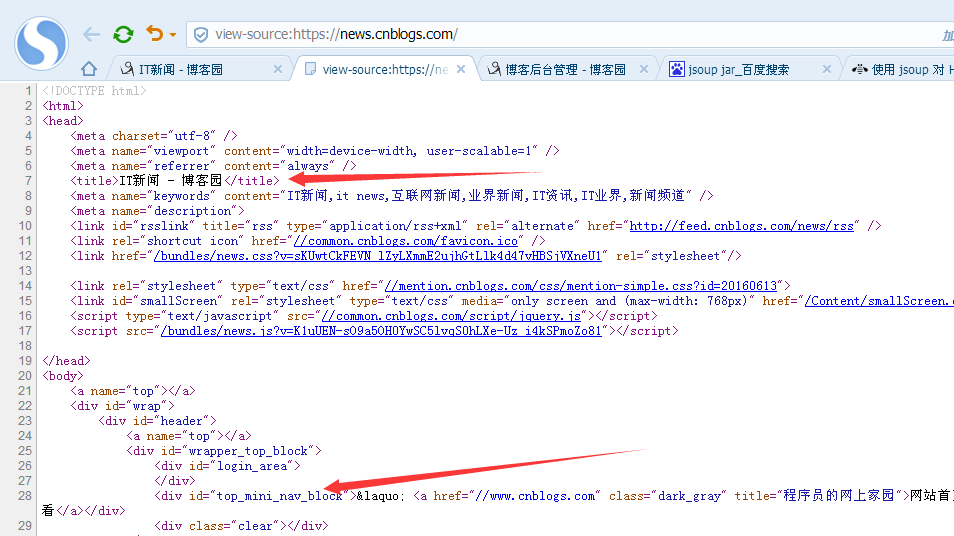
代码示例:
public class Demo {
public static void main(String[] args) throws Exception {
CloseableHttpClient httpClient=HttpClients.createDefault(); //1、创建实例
HttpGet httpGet=new HttpGet("https://news.cnblogs.com/"); //2、创建实例
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0");
CloseableHttpResponse httpResponse=httpClient.execute(httpGet); //3、执行
HttpEntity entity=httpResponse.getEntity(); //4、获取实体
String content=EntityUtils.toString(entity, "utf-8"); //5、获取网页内容
httpResponse.close();
httpClient.close();
Document doc=Jsoup.parse(content); // 解析网页 得到文档对象
Elements elements=doc.getElementsByTag("title"); // 获取tag是title的所有DOM元素
Element element=elements.get(0); // 获取第1个元素
String title=element.text(); // 返回元素的文本
System.out.println("标题:"+title);
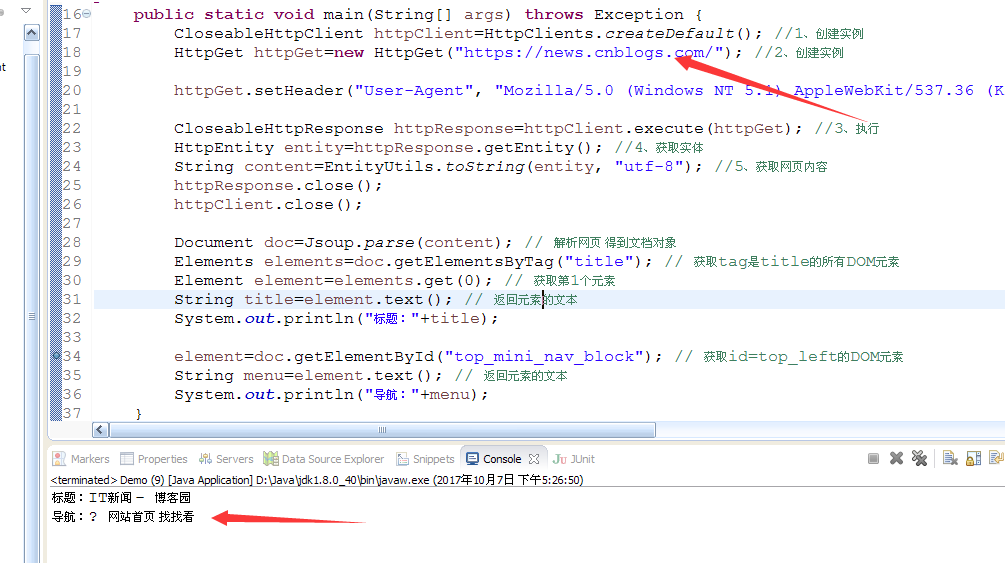
element=doc.getElementById("top_mini_nav_block"); // 获取id=top_left的DOM元素
String menu=element.text(); // 返回元素的文本
System.out.println("导航:"+menu);
}
}
运行如图: