List
ArrayList
知识点
1、1.7之前默认初始容量是10,1.8开始是0,后面执行 add 方法后才会将内部用于存储数据的数组容量初始化为10,这样可以节省内存空间,防止创建后一直没有使用浪费空间。
2、扩容时机是添加的数据超过当前数组可以存储的容量时,会扩容为原来的1.5倍。
3、ArrayList 内部有两种迭代器,分别是 Itr 和 ListItr,Itr就是我们常用的迭代器,它可以用于遍历 Set 集合和 List 集合,但是功能较少,ListItr 类继承于 Itr ,所以它拥有 Itr 的方法,同时内部也维护其自己的方法,所以它的功能更多,比如添加一个值,修改一个值,同时支持反向遍历。但是它只适用于 List 集合。
4、关于 ArrayList 内部的迭代器,是线程安全的,也就是在使用迭代器遍历时其他线程不能添加、删除这个容器内的值,但是可以修改,也可以通过迭代器的 remove 方法进行删除。不允许调用 ArrayList 方法进行添加删除的原因可以查看相关源代码
5、ArrayList 的输出方法是通过迭代器实现的。
6、数据对象排序紧密,查询效率高删除增加效率慢(相对于中间的元素)。
验证:
4、
@SuppressWarnings("unchecked")
public E next() {
checkForComodification(); // 检查结构是否改变,改变抛出异常
int i = cursor; // 获取当前遍历的索引值
if (i >= size) // 如果超过了数组的容量就抛异常
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1; // 索引加1
return (E) elementData[lastRet = i]; // 返回当前索引对应的值
}
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e; // 可以看到每次添加值都会改变 size
return true;
}
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
*/
private int size;
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // 存储容器数据的数组
可以看到数组没有使用 volatile 修饰,意味着多个线程同时在添加删除值的时候可能会造成数据覆盖而导致结果与预期结果不同(jmm,线程修改的值不会第一时间更新到主内存中),并且可能还会涉及到扩容缩容的情况导致结果更为复杂,同时 size 也没有使用 volatile 修饰,这样多线程下 size 在修改时也可能会导致修改被覆盖,最终可能会导致 size 与容器存储的值数量对不上号,造成数据混乱无法正常输出。而修改则不需要担心,因为 size 在修改时并不会改变, 即使最终的数据不是预期值但是能保证正常的输出。
迭代器的检查原理
关于迭代器的检查原理,可以看一下源码
final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); }
发现这个检查方法就是检查 modCount 与 expectedModCount 是否相等。追踪这两个属性可以发现,modCount 是 ArrayList 类的一个属性,而 expectedModCount 是迭代器的属性,它在迭代器对象初始化时被赋值为 modCount。而在执行添加和删除操作时就会去修改 modCount 属性,并且在每次执行迭代器的 next() 方法以及 ArrayList 内部的迭代方法时都会执行 checkForComodification 方法去检查这两个属性是否相等,如果不等就抛出异常。而在迭代器的 remove 方法中,则是直接将 expectedModCount 又进行一次重置赋值。
public void remove() { if (lastRet < 0) throw new IllegalStateException(); checkForComodification(); try { ArrayList.this.remove(lastRet); cursor = lastRet; lastRet = -1; expectedModCount = modCount; } catch (IndexOutOfBoundsException ex) { throw new ConcurrentModificationException(); } }
所以不会影响后面的遍历。
5、直接输出某个对象实际调用的就是输出它的 toString() 方法,在 ArrayList 类中是没有 toString() 方法的,所以向上查看
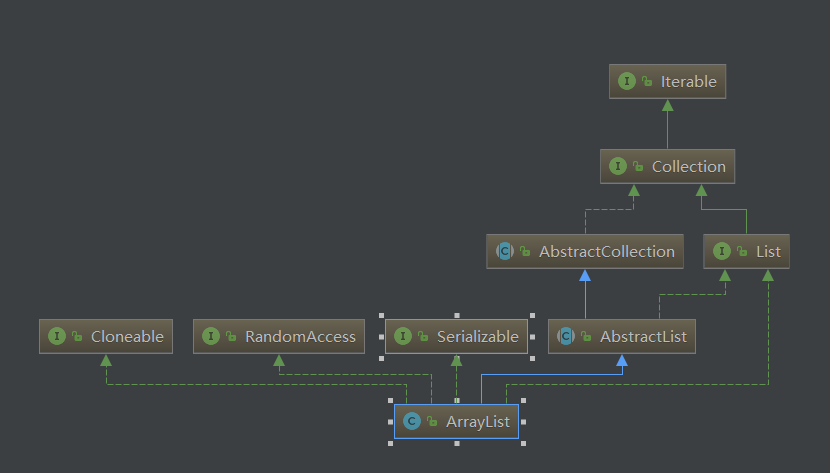
最终在 AbstractCollection 中发现 toString() 的实现。
public String toString() { Iterator<E> it = iterator(); if (! it.hasNext()) return "[]"; StringBuilder sb = new StringBuilder(); sb.append('['); for (;;) { E e = it.next(); sb.append(e == this ? "(this Collection)" : e); if (! it.hasNext()) return sb.append(']').toString(); sb.append(',').append(' '); } }
可以看到就是调用迭代器实现的,这也是为什么下面这段代码输出就会抛出异常,而不输出则不会的原因。
public static void main(String[] args){ ArrayList<Object> list = new ArrayList<>(); for(int i = 1; i <= 30;i++){ new Thread(()->{ list.add(UUID.randomUUID().toString().substring(0,8)); System.out.println(list); }).start(); } }
多线程下的安全问题
从上面的知识点可以看到 ArrayList 是没有任何同步机制的,在多线程下是无法使用的,那么如何在多线程下使用这种结构呢?
1、Vector
vector其实并不陌生,就是简单粗暴的 ArrayList 的多线程实现,在方法上添加 synchronized 来保证方法的同步,缺点是效率底下,所以基本不用。
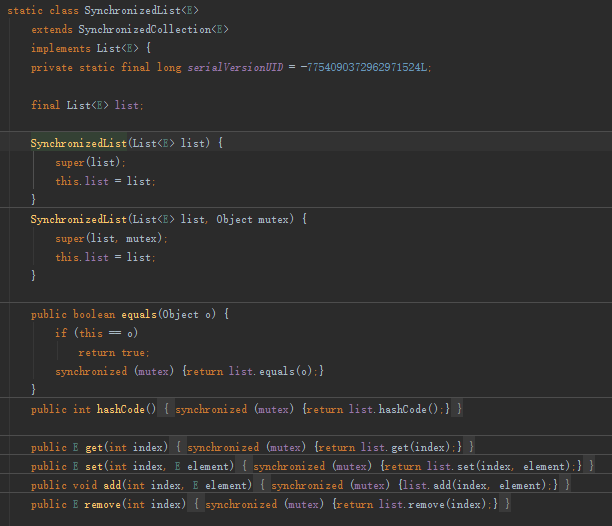
2、Collections工具类实现同步
Collectors 有一个方法 synchronizedList ,其本质也就是使用 synchronized 锁住整个方法
3、CopyOnWriteArrayList
这是一个比较特殊的容器,它在读取操作时不会加锁,在写时会加锁,使用的锁是 Lock 锁。
private transient volatile Object[] array; // 虽然使用 volatile 修饰,但是只是对于这个数组是实时获取到的,数组内的元素还是不能保证可见性 public E get(int index) { return get(getArray(), index); // 读操作没有加锁,比前面两种方式效率高 } public boolean add(E e) { final ReentrantLock lock = this.lock; // 使用 lock 锁 lock.lock(); try { Object[] elements = getArray(); int len = elements.length; Object[] newElements = Arrays.copyOf(elements, len + 1); // 创建新的数组对象 newElements[len] = e; // 添加新值 setArray(newElements); // 替换数组属性的值 return true; } finally { lock.unlock(); } }
特点:读操作没有加锁,写操作加锁,在读多写少的场景效率高,缺点是不能保证数据的实时性。
另一个特点是每次添加数据都会新建一个数组对象,而其他容器是在扩容时才会创建新的数组对象,所以它的内存消耗会比其他容器要高,同时也不存在扩容最大容量的概念。
LinkedList
知识点
双向链表,通过结点形式连接组成,没有容量限制,排列不紧密,查询效率低增删效率高(相对于中间元素)。
多线程下的安全问题
同样是使用 Collections工具类的synchronizedList 方法。由于 LinkedList 使用的并不算多这里就不过多阐述。
Map
HashMap
知识点
1、底层使用数组加链表结构,在1.8开始又引入了红黑树,这是为了防止在链表长度过长时造成链表数据的查询效率降低。兼顾了查询与增删的效率。
2、没有指定容量时数组初始容量是0,第一次 put 后会初始化为16。
3、key 和 value 都可以为 null 值。
4、扩容时机是容器存储的数据量达到 0.75*数组容量 时就会发生扩容,变成原来的2倍,而树化是在链表长度达到 8 且数组容量达到 64 才会发生树化操作,否则如果只是链表长度达到 8 而数组容量没有达到 64 只会扩容为原来的2倍。
5、HashMap 在计算哈希值前会先调用内部的扰动函数处理 hashcode 值,让高位和低位进行运算,这是为了让高位的数也能参与哈希值的计算,减小哈希冲突。
6、key 值最好是一个常量,如果是自定义对象,那么需要重写 hashcode 与 equals 方法。
7、内部维护了多个迭代器,同样是线程安全的。
hashmap 是面试中的重点,开发中使用的频率也是非常高的,所以想了解更多 HashMap 与 线程安全版的 ConcurrentHashMap 可以移步 HashMap 、ConcurrentHashMap知识点全解析 。
多线程下的安全问题
1、Collections 工具类处理
synchronizedMap(Map<K,V>)方法。本质和前面说得 list 处理一样,都是通过 synchronized 锁住方法来调用 HashMap 的方法,效率低下
2、HashTable
使用 synchronized 锁住整个方法。。
3、ConcurrentHashMap
同样是使用 synchronized 锁,锁住的是一部分代码块,并且锁对应的对象是数组中的一列,提高了多线程下的执行效率。
LinkedHashMap
知识点
是 HashMap 的链表形式,弥补了 HashMap 无序性的不足,其实现原理就是内部的结点类除了直接继承 HashMap 的结点类 Node ,其属性拥有自己的before,after属性来表示前一个和后一个结点的值,而从 Node 继承过来的 next 属性还是表示链表的下一个结点值。如果业务需要记录插入数据的顺序可以使用 LinkedHashMap。
static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } }
多线程下的安全问题
Collections处理,同上。
TreeMap
知识点
1、HashMap 内部是使用数组+链表+红黑树,而 TreeMap 底层是使用红黑树来存储的。
2、在 HashMap 中 key 如果是自定义类需要去重写 hashCode 方法与 equals 方法,这是由于在 put 时是根据这两个方法去比较两对键值对的 key 是否相等。而在 TreeMap 中则不需要。
3、TreeMap 因为红黑树结构而是有顺序的,但是是无序集合(插入顺序和遍历顺序不一致)。
排序方式:
1、自然排序,让自定义类实现 Comparable 接口


class Student implements Comparable<Student>{ int id; int age; int length; public Student(int id, int age, int length) { super(); this.id = id; this.age = age; this.length = length; } public int getId() { return id; } public void setId(int id) { this.id = id; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public int getLength() { return length; } public void setLength(int length) { this.length = length; } @Override public String toString() { return "Student [id=" + id + ", age=" + age + ", length=" + length + "]"; } @Override public int compareTo(Student o) { // 优先按年龄从小到大排序,如果年龄相等就按id从小到大排序 if(this.age>o.age) { return 1; } else if(this.age<o.age){ return -1; } else if(this.id>o.id) { return 1; } else{ return 0; } } }
2、定制排序,自定义类实现 Comparator 接口,完成解耦,推荐。
class MyComparatorSmallToBig implements Comparator<Student> { @Override public int compare(Student o1, Student o2) { // TODO Auto-generated method stub return o2.getAge()-o1.getAge();//从小到大排序 } }
多线程下的安全问题
Collections处理,同上。
Set
HashSet
知识点
1、底层是通过 HashMap 的 key 实现的,所以元素不会重复。
2、迭代器使用的也是 HashMap 的 keyIterator 。会检查其他线程会不会删除和添加操作。
多线程下的安全问题
1、Collections工具类
syschronizedSet(Set<T>)方法。
2、CopyOnWriteArraySet
底层使用的是 CopyOnWriteArrayList,在添加时会加锁判断是否有重复值。
private final CopyOnWriteArrayList<E> al; public boolean add(E e) { return al.addIfAbsent(e); } public boolean addIfAbsent(E e) { Object[] snapshot = getArray(); return indexOf(e, snapshot, 0, snapshot.length) >= 0 ? false : addIfAbsent(e, snapshot); } private boolean addIfAbsent(E e, Object[] snapshot) { final ReentrantLock lock = this.lock; lock.lock(); // 加锁,保证线程安全 try { Object[] current = getArray(); int len = current.length; if (snapshot != current) { // Optimize for lost race to another addXXX operation int common = Math.min(snapshot.length, len); for (int i = 0; i < common; i++) // 遍历判断是否有重复值 if (current[i] != snapshot[i] && eq(e, current[i])) return false; if (indexOf(e, current, common, len) >= 0) return false; } Object[] newElements = Arrays.copyOf(current, len + 1); newElements[len] = e; setArray(newElements); return true; } finally { lock.unlock(); } }
TreeSet
知识点
1、与 HashSet 与HashMap 的关系一样, TreeSet 也是通过 TreeMap 的 key 集合实现的。所以结构也是红黑树
2、排序方式也和 TreeMap 一样。
多线程下的安全问题
Collections处理,同上。
LinkedHashSet
知识点
使用LinkedHashMap 的 key 集合。所以也是Set容器中唯一 一个有序集合。使用的before,after属性来表示前一个和后一个结点的值。
多线程下的安全问题
Collections处理,同上。
最后:上面提到的 ArrayList、LinkedList、HashMap、HashSet、TreeMap、TreeSet 的 toString 方法都是通过迭代器实现的,这意味着在其他线程添加、删除操作时直接输出这些容器对象是会抛出异常的。