【计算机网络】-网络层-服务质量
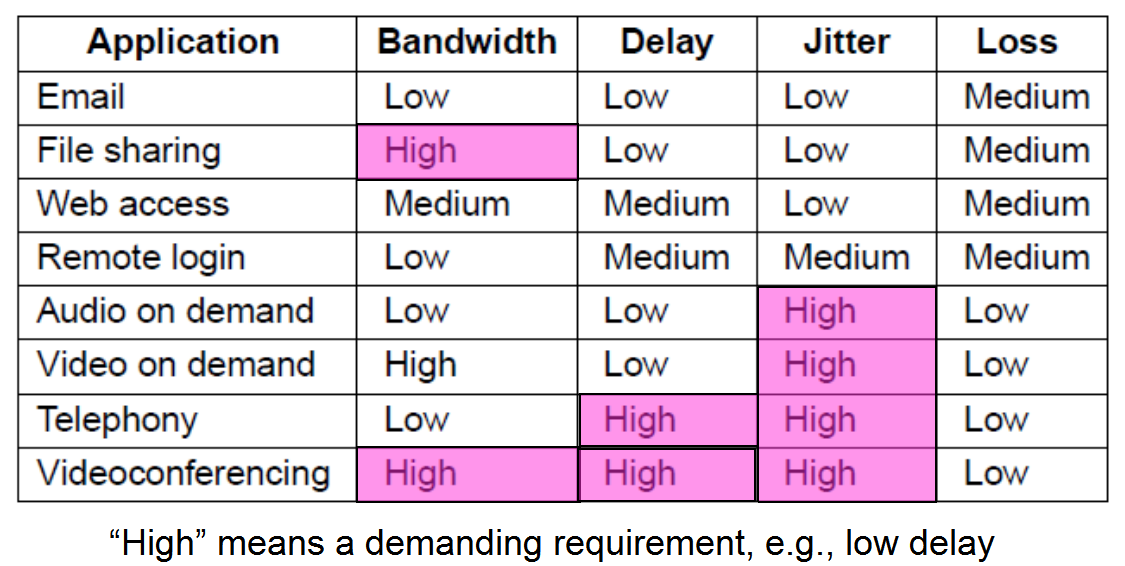
应用需求
流:从一个源到一个目标的数据包流
流的需求特征包括可靠性、延迟、抖动、带宽
这4个特征合起来决定一个流所要求的服务质量(QoS)
不同的应用程序关心不同的属性,我们希望所有应用程序都能获得所需的东西,网络提供具有各种QoS(服务质量)的服务以满足应用需求
流量整型
流量整型是指调节进入网络的数据流的平均速率和突发性所采用的技术。
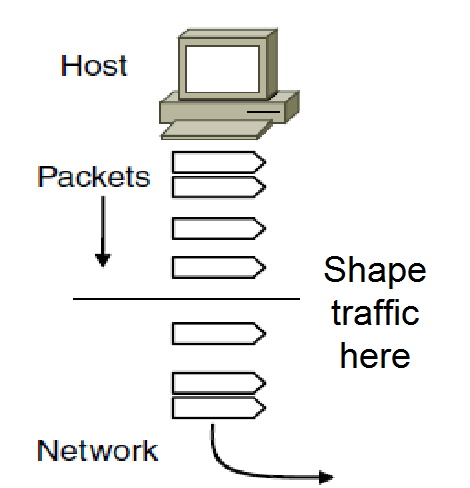
流量整形技术可以减少拥塞,也有助于运营商兑现它的承诺
流量监管:
对一个业务流进行监视
漏桶算法(The Leaky Bucket Algorithm)
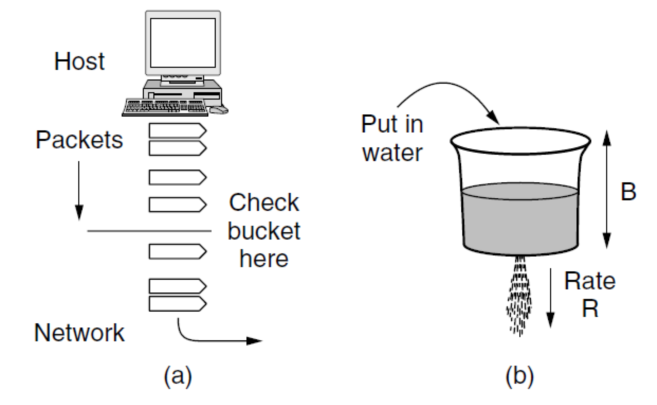
算法思想:
如果在一台主机上,队列中的数据包数目达到了最大值,这时又有一个或多个进程要发送数据包,则该数据包被丢弃
主机每过一个时钟滴答才允许把一个数据包放到网络上
将用户发出的不平滑的数据数据包流转变成网络中平滑的数据包流
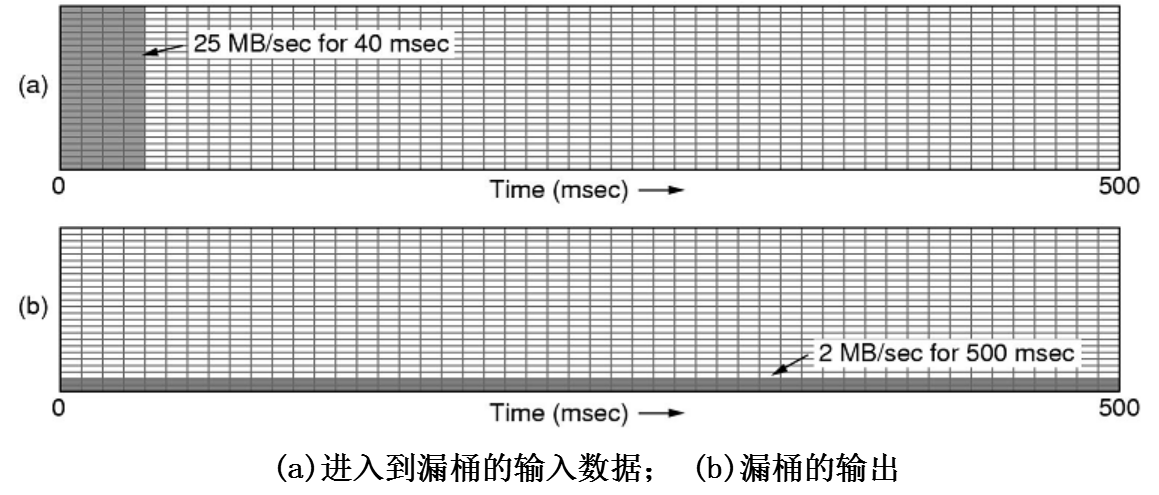
例子:
一台计算机能以25MB/s的速率生成数据,且网络也能以该速率运行。但路由器仅能在很短的时间内以该速率工作,其他时间的最佳工作速率不超过2MB/s。现设数据以突发式输入,每次1MB(时间为40ms)的突发数据。
为了将平均速率降到2MB/s,用一个恒定速率ρ=2MB/s,容积为1MB的漏桶。这意味着每次输入高达1MB的数据也不会丢失,而且这些突发数据在500ms(=1/2s))内被传出去,而不管它们进来时多快
漏桶算法适用于
可用于固定数据包长的协议,如ATM
可用于可变数据包长的协议,如IP,但要使用字节计数
漏桶算法缺点
无论负载突发性如何,漏桶算法强迫输出按平均速率进行,不灵活
令牌桶算法(Token Bucket Algorithm)
当大的通信量到来时,输出也能加速,最大到桶的大小n
基本思想
漏桶存放令牌,每T秒产生一个令牌,令牌累积到超过漏桶上界n时就不再增加
数据包传输之前必须获得一个令牌,传输之后删除该令牌
在桶满时,会丢失令牌,但绝不丢弃数据包
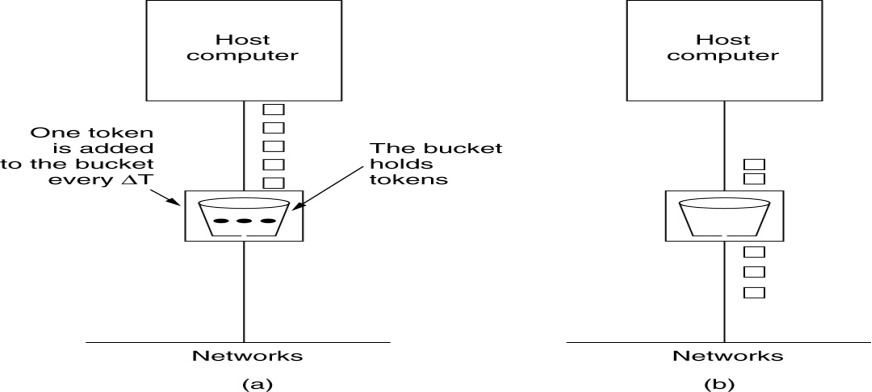
(a)桶内有3个令牌,同时有5个待传数据包 ; (b)3数据包传送出去后
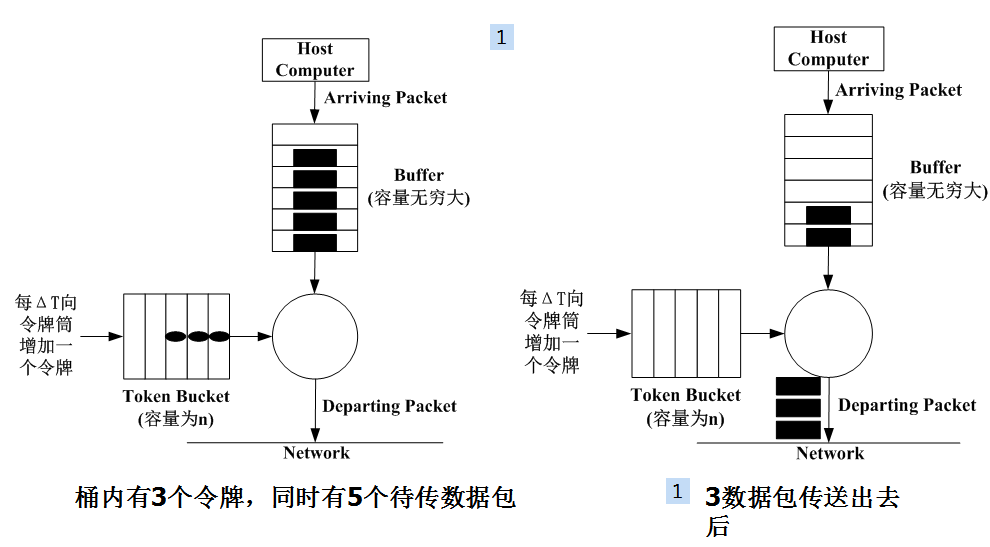
基本令牌桶算法
- 用一个令牌可以发送一个数据包
- 有一个令牌计数器
加:每△t,加1,当令牌桶满时,不再加
减:每发送一个数据包,减1,计数器为0时,不能发送数据
字节计数方式
- 用一个令牌可以发送k个字节
- 令牌计数器
加:每△t, 加k(字节),令牌桶满时不再加
减:每发送一个数据包,减其字节长度,为0时不再发送数据
包调度
在同一个流的数据包之间以及在竞争流之间分配路由器资源的算法叫做数据包调度算法。
为不同流可以预约的潜在资源有三种分别是:
1.带宽
2.缓冲区
3.CPU周期
先来先服务算法(FIFO)
每个路由器把需要转发的包排入相应的输出线路的队列,知道他们可以发送,并且发送的顺序与到达队列的顺序相同,这种算法就叫做先来先服务算法。
尾丢包:
FIFO路由器在队列满了的时候通常会丢弃新到的数据包,由于新到的数据包会排在队列末尾,这种行为成为尾丢包。
缺点:容易实现,但是无法提供良好的服务,因为存在多个流的时候,一个流可能会影响到其他流量的性能,比如大的突发流量包,会吃掉路由器大部分的容量,导致饿死其他流量
公平队列算法(Fair Queueing)

针对每一条输出线路,路由器为每一流设置单独的队列,当线路空闲的时候,路由器循环扫描每个队列,然后从下一个队列中取出第一个数据包进行发送,通过这种方式,如果某条输出线路被N个主机竞争,则没发送n个数据包中每个主机获得一次发送数据包的机会。
特点:所有的流量以同样的速率发送数据包,即使源端发送更多的数据包也不会提高这个速率
缺点:它给大数据包的主机比给小数据包的主机提供了更多的带宽。
加权公平队列(Weighted Fair Queueing)
对公平队列法的改进,把原来数据包接数据包的循环方式改成了字节接字节的循环方式。这里的诀窍是计算一个虚拟时间,这个时间指的是每个数据包发送完毕所需要的轮数,每一轮循环从所有的数据待发送的队列中排空一个字节,然后按照数据包结束时间顺序排队,并按照这个顺序真正发送数据包。
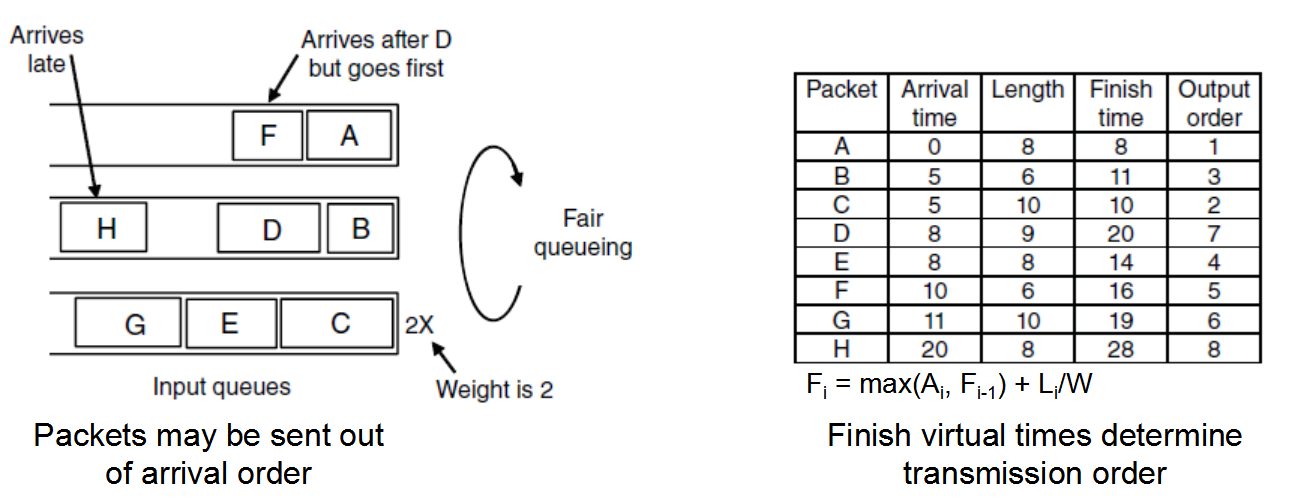
例子:分别给出了三个流数据包的到达时间和完成时间,如果一个数据包的长度为L,它的完成时间恰好是启动之后的第L轮循环,启动时间要么是前一个数据包的完成时间,要么是数据包的到达时间。
按照表中内容,考察最上面两个队列的前两个数据包,数据包的到达顺序是A、B、D和F,数据包A在第0轮到达,长度为8个字节,因此它完成的时间是在第8轮,同样的数据包B的完成时间是11轮,当B还在被发送的时候,数据包D到达,因此它完成时间要从B结束时开始算9字节循环,最终完成的时间位20。类似的还有F完成时间为16.如果没有新的数据包到达,则相对的发送顺序为A、B、F、D,尽管F在D之后到达,有可能在最上面的那个流到达另外一个很小的数据包,它的完成时间在D之前,如果D的传输尚未开始的,那么该小数据包可能会跳跃到D的前面。公平队列不能抢占当前正在传输的数据包,因为数据包发送是整体行为,因为公平队列只是理想字节接字节方案的近似法,但是这是一个很好的近似,任何时候数据包都保持其理想的传输方案。
缺点:它给所有主机相同的优先级,在许多情况下,比如视频服务器比文件服务器也是可取的,要做到这点很容易,只有每轮循环时候给视频服务器两个或者两个以上的字节,这种修改后的算法是加权平均队列。每一轮的字节数是一个流的权重W,完成时间公式Fi=max(Ai,Fi-1)+Li/W,Ai是到达时间,Fi为完成时间,Li是数据包i的长度
- 插入有序队列时间复杂度O(logN)
- 改进赤字循环算法O(1)
其他调度算法
-
优先级调度:高优先级的包优于低优先级的包发送
缺点:高优先级的突发数据包饿死低优先级的包 -
WFQ也给高优先级更高的权重,但是低优先级的包也有机会法,不至于饿死
-
数据包携带时间戳调度法
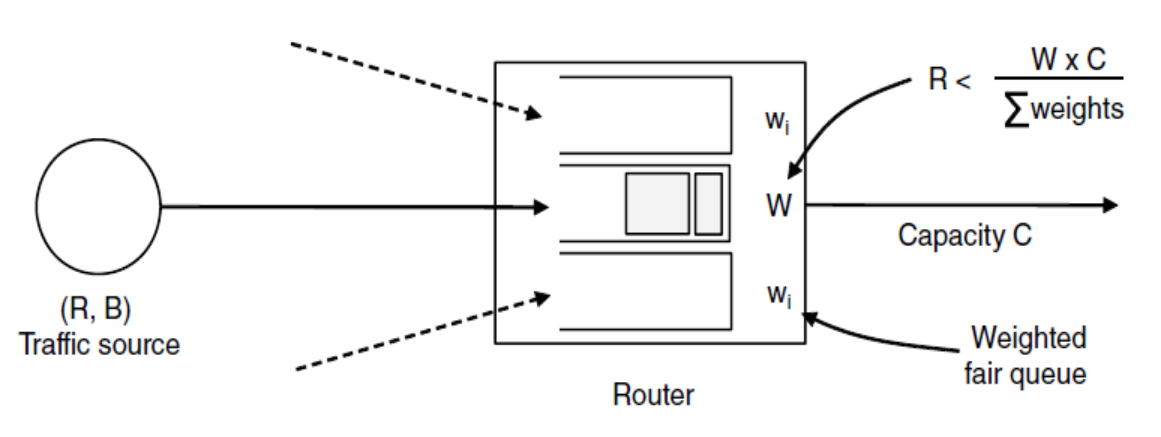
准入控制(了解概念)
准入控制采用流量规范,并决定网络是否可以承载它,设置数据包调度以满足QoS

- 保证带宽B和延迟D
- 将流量源调整为(R,B)令牌桶
- 使用所有重量> R /容量的重量运行WFQ
- 保留所有流量模式和所有拓扑
综合服务
综合服务主要针对单播或者组播应用,它IETF设计流式多媒体的体系结构设计工作的通用名称。
RSVP协议
资源预留协议,发送之前先让路由器预留一下资源
主要功能:预留资源
- 允许多个发送方给多个接收组传送数据
- 允许接受方自由切换频道
- 消除拥塞的同时优化带宽
接收方将请求发送回发送方,一路上的每个路由器都保留资源,路由器合并多个相同流的请求,设置了整个路径,或未进行保留。
区分服务
- 客户购买他们想要的东西
- 快速班优先于普通班
- 流量减少,但应用程序质量更高
DiffServ的实现
- 客户在包装上标记所需的类别
- ISP调整流量以确保标记被支付
- 路由器使用WFQ提供不同的服务级别
基于流的算法的缺点:
- 他们都需要为每个流进行预先设置,当存在数千或者数百万个流的时候,不能很好扩展使用
- 路由器为每个流维护一个内部状态容易导致路由器崩溃
- 为了修改数据流需要修改路由器代码量很大,涉及复杂路由器与路由器之间消息的交换
为了解决这些问题设计了区分服务:
区分服务可以由一组服务器来进行提供,路由器构成了一个管理域(比如一家电话公司),管理规范定义了一组服务类别,每个服务类别对应特定的转发规则。
客户订购了区分服务,那么进入该管理域的数据包就会被标上属于哪类服务。
单跳行为:对应数据包在每个路由器得到的待遇,而不是在整个网络中保证的待遇。具有单跳行为的数据包比其他数据包获得更好的待遇。
加速转发
服务分两类:加速和常规的,大量的通信流量属于常规流量,小部分需要加速转发。加速类别的数据包可以直接通过网络,就好像不存在其他数据包一样,会提高服务质量,数据包会被分类成常规的和普通的,在发送主机上进行分类,被标记上需要加速的包会得到优惠待遇。

确保转发
定义4种优先级别,三种丢包概率
- 将数据包分为4个优先级别
- 确定丢包类别
- 数据包有网络内部的路由器处理,路由器上的数据包调度器区分不同类别的数据包。一般选择针对4个优先级采用加权公平队列,给予较高的类别以较高的权重。这种方式高优先级的数据包获得大量的带宽,但是低优先级的数据包也不会完全饿死。
