一、数字
整型(int): 年级、班级、手机号、QQ号、身份证号、等级
如: level=10
浮点型(float): 薪资、身高、温度、体重、价格
如:height=1.81
salary=2.3
二、字符串
字符串(str):包括单引号、双引号和三引号。有一串字符组成
用途:(描述性的数据)姓名、性别、地址、学历、密码(sdf1233)
取值:首先要明确,字符串整体就是一个值只不过有特殊之处(python没有字符类型组成,想取出字符串的字符,也可以按照下标的方式获得)
name:取得是字符串整体的那一个值
name[1]:取得是第二位置的字符
字符串拼接:
>>> msg1='hello'
>>> msg2=' world'
>>>
>>> msg1 + msg2
'hello world'
>>> res=msg1 + msg2
>>> print(res)
hello world
>>> msg1*3
'hellohellohello'
三、列表
(1)列表list:包含在[]内,用逗号分割开
用途(存多个值,可以修改):爱好,装备,女朋友们
hobby=['play','eat','sleep']
(2) 方法:
hobby.append
hobby.remove
(3)操作:
<1> 查看:
>>> girls=['alex','wsb',['egon','ysb']]
>>> girls[2]
['egon', 'ysb']
>>> girls[2][0]
<2> 增加:
girls.append(元素)
<3>删除:
girls.remove(元素)
del girls[元素的索引]
<4> 修改:
girls[0]='alexSB'
四:字典
(1) 字典dict:定义在{},逗号分割,每一个元素的形式都是key:value
student_info="""
name:alex
sex:None
age:81
hobby:zsb00 zsb1 zsb2 zsb3
"""
#name sex age hobby
student_info=['alex',None,81,['zsb0','zsb1','zsb2','zsb30']]
student_info[3][2]
(2)用途:存多个值,这一点与列表相同,值可以是任意数据类型
(3)特征:每一个值都一个唯一个对应关系,即key,强调一点,key必须是
(4)不可变类型:字符串,数字
student_info={
'age':81,
'name':'alex',
'sex':None,
'hobbies':['zsb0','zsb1','zsb2','zsb30']
}
(5)操作:
<1>查看
>>> student_info={
... 'age':81,
... 'name':'alex',
... 'sex':None,
... 'hobbies':['zsb0','zsb1','zsb2','zsb30']
... }
>>>
>>> student_info['age']
81
>>> student_info['hobbies']
['zsb0', 'zsb1', 'zsb2', 'zsb30']
>>> student_info['hobbies'][2]
'zsb2'
<2>增加
student_info['stu_id']=123456
<3>删除
del student_info['stu_id']
<4>修改
student_info['name']='alexSB'
五:布尔
(1) 布尔:True False
(2)用途:用来判断
>>> pinfo={'name':'oldboymei','age':53,'sex':'female'}
>>>
>>>
>>> pinfo['age'] > 50
True
>>> pinfo['sex'] == 'female'
True
# 写代码,有如下变量,请按照要求实现每个功能 (共6分,每小题各0.5分) name = " aleX" # 1) 移除 name 变量对应的值两边的空格,并输出处理结果 # 2) 判断 name 变量对应的值是否以 "al" 开头,并输出结果 # 3) 判断 name 变量对应的值是否以 "X" 结尾,并输出结果 # 4) 将 name 变量对应的值中的 “l” 替换为 “p”,并输出结果 # 5) 将 name 变量对应的值根据 “l” 分割,并输出结果。 # 6) 将 name 变量对应的值变大写,并输出结果 # 7) 将 name 变量对应的值变小写,并输出结果 # 8) 请输出 name 变量对应的值的第 2 个字符? # 9) 请输出 name 变量对应的值的前 3 个字符? # 10) 请输出 name 变量对应的值的后 2 个字符? # 11) 请输出 name 变量对应的值中 “e” 所在索引位置? # 12) 获取子序列,去掉最后一个字符。如: oldboy 则获取 oldbo。


# 写代码,有如下变量,请按照要求实现每个功能 (共6分,每小题各0.5分) name = " aleX" # 1) 移除 name 变量对应的值两边的空格,并输出处理结果 name = ' aleX' a=name.strip() print(a) # 2) 判断 name 变量对应的值是否以 "al" 开头,并输出结果 name=' aleX' if name.startswith(name): print(name) else: print('no') # 3) 判断 name 变量对应的值是否以 "X" 结尾,并输出结果 name=' aleX' if name.endswith(name): print(name) else: print('no') # 4) 将 name 变量对应的值中的 “l” 替换为 “p”,并输出结果 name=' aleX' print(name.replace('l','p')) # 5) 将 name 变量对应的值根据 “l” 分割,并输出结果。 name=' aleX' print(name.split('l')) # 6) 将 name 变量对应的值变大写,并输出结果 name=' aleX' print(name.upper()) # 7) 将 name 变量对应的值变小写,并输出结果 name=' aleX' print(name.lower()) # 8) 请输出 name 变量对应的值的第 2 个字符? name=' aleX' print(name[1]) # 9) 请输出 name 变量对应的值的前 3 个字符? name=' aleX' print(name[:3]) # 10) 请输出 name 变量对应的值的后 2 个字符? name=' aleX' print(name[-2:]) # 11) 请输出 name 变量对应的值中 “e” 所在索引位置? name=' aleX' print(name.index('e')) # 12) 获取子序列,去掉最后一个字符。如: oldboy 则获取 oldbo。 name=' aleX' a=name[:-1] print(a)
1. 有列表data=['alex',49,[1900,3,18]],分别取出列表中的名字,年龄,出生的年,月,日赋值给不同的变量 2. 用列表模拟队列 3. 用列表模拟堆栈 4. 有如下列表,请按照年龄排序(涉及到匿名函数) l=[ {'name':'alex','age':84}, {'name':'oldboy','age':73}, {'name':'egon','age':18}, ] 答案: l.sort(key=lambda item:item['age']) print(l)
#简单购物车,要求如下: 实现打印商品详细信息,用户输入商品名和购买个数,则将商品名,价格,购买个数加入购物列表,如果输入为空或其他非法输入则要求用户重新输入 msg_dic={ 'apple':10, 'tesla':100000, 'mac':3000, 'lenovo':30000, 'chicken':10, }
msg_dic={ 'apple':10, 'tesla':100000, 'mac':3000, 'lenovo':30000, 'chicken':10, } goods_l=[] while True: for key,item in msg_dic.items(): print('name:{name} price:{price}'.format(price=item,name=key)) choice=input('商品>>: ').strip() if not choice or choice not in msg_dic:continue count=input('购买个数>>: ').strip() if not count.isdigit():continue goods_l.append((choice,msg_dic[choice],count)) print(goods_l)
练习:
1 有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中 即: {'k1': 大于66的所有值, 'k2': 小于66的所有值}
a={'k1':[],'k2':[]}
c=[11,22,33,44,55,66,77,88,99,90]
for i in c:
if i>66:
a['k1'].append(i)
else:
a['k2'].append(i)
print(a)
2 统计s='hello alex alex say hello sb sb'中每个单词的个数 结果如:{'hello': 2, 'alex': 2, 'say': 1, 'sb': 2}
s='hello alex alex say hello sb sb' l=s.split() dic={} for item in l: if item in dic: dic[item]+=1 else: dic[item]=1 print(dic)
一.关系运算 有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合 pythons={'alex','egon','yuanhao','wupeiqi','gangdan','biubiu'} linuxs={'wupeiqi','oldboy','gangdan'} 1. 求出即报名python又报名linux课程的学员名字集合 2. 求出所有报名的学生名字集合 3. 求出只报名python课程的学员名字 4. 求出没有同时这两门课程的学员名字集合
# 有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合 pythons={'alex','egon','yuanhao','wupeiqi','gangdan','biubiu'} linuxs={'wupeiqi','oldboy','gangdan'} # 求出即报名python又报名linux课程的学员名字集合 print(pythons & linuxs) # 求出所有报名的学生名字集合 print(pythons | linuxs) # 求出只报名python课程的学员名字 print(pythons - linuxs) # 求出没有同时这两门课程的学员名字集合 print(pythons ^ linuxs)
二.去重 1. 有列表l=['a','b',1,'a','a'],列表元素均为可hash类型,去重,得到新列表,且新列表无需保持列表原来的顺序 2.在上题的基础上,保存列表原来的顺序 3.去除文件中重复的行,肯定要保持文件内容的顺序不变 4.有如下列表,列表元素为不可hash类型,去重,得到新列表,且新列表一定要保持列表原来的顺序 l=[ {'name':'egon','age':18,'sex':'male'}, {'name':'alex','age':73,'sex':'male'}, {'name':'egon','age':20,'sex':'female'}, {'name':'egon','age':18,'sex':'male'}, {'name':'egon','age':18,'sex':'male'}, ]
#去重,无需保持原来的顺序 l=['a','b',1,'a','a'] print(set(l)) #去重,并保持原来的顺序 #方法一:不用集合 l=[1,'a','b',1,'a'] l1=[] for i in l: if i not in l1: l1.append(i) print(l1) #方法二:借助集合 l1=[] s=set() for i in l: if i not in s: s.add(i) l1.append(i) print(l1) #同上方法二,去除文件中重复的行 import os with open('db.txt','r',encoding='utf-8') as read_f, open('.db.txt.swap','w',encoding='utf-8') as write_f: s=set() for line in read_f: if line not in s: s.add(line) write_f.write(line) os.remove('db.txt') os.rename('.db.txt.swap','db.txt') #列表中元素为可变类型时,去重,并且保持原来顺序 l=[ {'name':'egon','age':18,'sex':'male'}, {'name':'alex','age':73,'sex':'male'}, {'name':'egon','age':20,'sex':'female'}, {'name':'egon','age':18,'sex':'male'}, {'name':'egon','age':18,'sex':'male'}, ] # print(set(l)) #报错:unhashable type: 'dict' s=set() l1=[] for item in l: val=(item['name'],item['age'],item['sex']) if val not in s: s.add(val) l1.append(item) print(l1) #定义函数,既可以针对可以hash类型又可以针对不可hash类型 def func(items,key=None): s=set() for item in items: val=item if key is None else key(item) if val not in s: s.add(val) yield item print(list(func(l,key=lambda dic:(dic['name'],dic['age'],dic['sex']))))
#作业一: 三级菜单 #要求: 打印省、市、县三级菜单 可返回上一级 可随时退出程序
menu = { '北京':{ '海淀':{ '五道口':{ 'soho':{}, '网易':{}, 'google':{} }, '中关村':{ '爱奇艺':{}, '汽车之家':{}, 'youku':{}, }, '上地':{ '百度':{}, }, }, '昌平':{ '沙河':{ '老男孩':{}, '北航':{}, }, '天通苑':{}, '回龙观':{}, }, '朝阳':{}, '东城':{}, }, '上海':{ '闵行':{ "人民广场":{ '炸鸡店':{} } }, '闸北':{ '火车战':{ '携程':{} } }, '浦东':{}, }, '山东':{}, } exit_flag = False current_layer = menu layers = [menu] while not exit_flag: for k in current_layer: print(k) choice = input(">>:").strip() if choice == "b": current_layer = layers[-1] #print("change to laster", current_layer) layers.pop() elif choice not in current_layer:continue else: layers.append(current_layer) current_layer = current_layer[choice] 三年菜单文艺青年版
6、成员运算:

7.身份运算

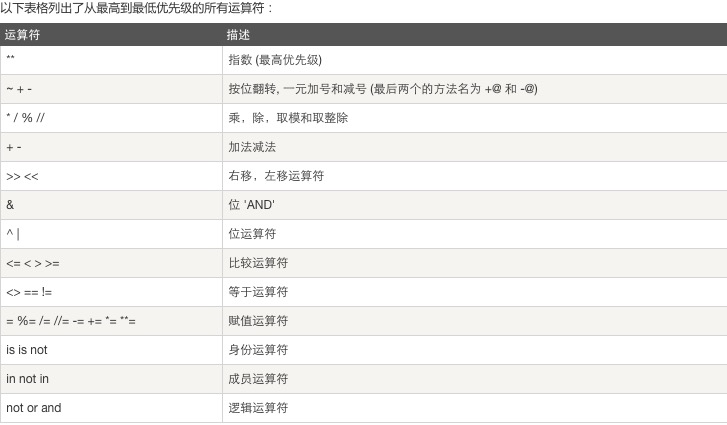
8.运算符优先级:自上而下,优先级从高到低