模块
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在Python中,一个.py文件就称之为一个模块(Module)。使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)。
举个例子,一个aaaa.py的文件就是一个名字叫aaaa的模块,一个bbb.py的文件就是一个名字叫bbb的模块。
现在,假设我们的aaaa和bbb这两个模块名字与其他模块冲突了,于是我们可以通过包来组织模块,避免冲突。方法是选择一个顶层包名,比如test,按照如下目录存放:

引入了包以后,只要顶层的包名不与别人冲突,那所有模块都不会与别人冲突。现在,aaaa.py模块的名字就变成了test.aaaa,类似的,bbb.py的模块名变成了test.bbb。
请注意,每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录,而不是一个包。__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是test.
匿名函数
关键字lambda表示匿名函数,冒号前面的x表示函数参数。
匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。
用匿名函数有个好处,因为函数没有名字,不必担心函数名冲突。此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数:
>>> f = lambda x: x * x >>> f <function <lambda> at 0x000000000292AF28> >>> f(6) 36 >>>
递归函数
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
def fact(n): if n==1: return 1 return n * fact(n - 1) 上面就是一个递归函数。可以试试: >>> fact(1) 1 >>> fact(5) 120 >>> 如果我们计算fact(5),可以根据函数定义看到计算过程如下: ===> fact(5) ===> 5 * fact(4) ===> 5 * (4 * fact(3)) ===> 5 * (4 * (3 * fact(2))) ===> 5 * (4 * (3 * (2 * fact(1)))) ===> 5 * (4 * (3 * (2 * 1))) ===> 5 * (4 * (3 * 2)) ===> 5 * (4 * 6) ===> 5 * 24 ===> 120
递归函数的优点是定义简单,逻辑清晰。理论上,所有的递归函数都可以写成循环的方式,但循环的逻辑不如递归清晰。
使用递归函数的优点是逻辑简单清晰,缺点是过深的调用会导致栈溢出。
pickle and json序列化
pickle:
把变量从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling。序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。Pickle的问题和所有其他编程语言特有的序列化问题一样,它只能用于Python,只能用Pickle保存那些不重要的数据。
Python提供了pickle模块来实现序列化。
pickle模块提供了四个功能:dumps、dump、loads、load
>>> import pickle
>>> info = {'name':'tom','age':'24','job':'it'}
>>> pickle.dumps(info)
b'x80x03}qx00(Xx04x00x00x00nameqx01Xx03x00x00x00tomqx02Xx03x00x0
0x00ageqx03Xx02x00x00x0024qx04Xx03x00x00x00jobqx05Xx02x00x00x00i
tqx06u.'
>>>
pickle.dumps()方法把任意对象序列化成一个bytes,然后,就可以把这个bytes写入文件。或者用另一个方法pickle.dump()直接把对象序列化后写入一个file-like Object:
>>> f = open('a.txt','wb')
>>> pickle.dump(info,f)
>>> f.close()
查看写入a.txt文件,这些都是Python保存的对象内部信息。
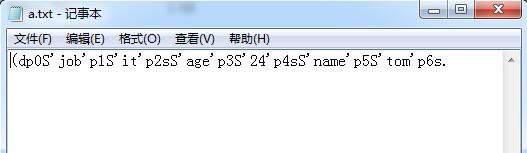
当我们要把对象从磁盘读到内存时,可以先把内容读到一个bytes,然后用pickle.loads()方法反序列化出对象,也可以直接用pickle.load()方法从一个file-like Object中直接反序列化出对象。我们打开另一个Python命令行来反序列化刚才保存的对象:
>>> f = open('a.txt','rb')
>>> d = pickle.load(f)
>>> f.close()
>>> d
{'job': 'it', 'age': '24', 'name': 'tom'}
>>>
这个变量和原来的变量是完全不相干的对象,它们只是内容相同而已。
json:
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
Json模块提供了四个功能:dumps、dump、loads、load
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
| JSON类型 | Python类型 |
| {} | dict |
| [] | list |
| "string" | str |
| 1234.56 | int或float |
| true/false | True/False |
| null | None |
把Python对象变成一个JSON:
>>> import json
>>> info = {'name':'tom','age':'24','job':'it'}
>>> json.dumps(info)
'{"job": "it", "age": "24", "name": "tom"}'
>>>
dumps()方法返回一个str,内容就是标准的JSON。类似的,dump()方法可以直接把JSON写入一个file-like Object。
要把JSON反序列化为Python对象,用loads()或者对应的load()方法,前者把JSON的字符串反序列化,后者从file-like Object中读取字符串并反序列化:
>>> json_str = '{"job": "it", "age": "24", "name": "tom"}'
>>> json.loads(json_str)
{u'job': u'it', u'age': u'24', u'name': u'tom'}
re模块
re 模块使 Python 语言拥有全部的正则表达式功能。
正则表达式修饰符 - 可选标志

以下是常用匹配模式(元字符)
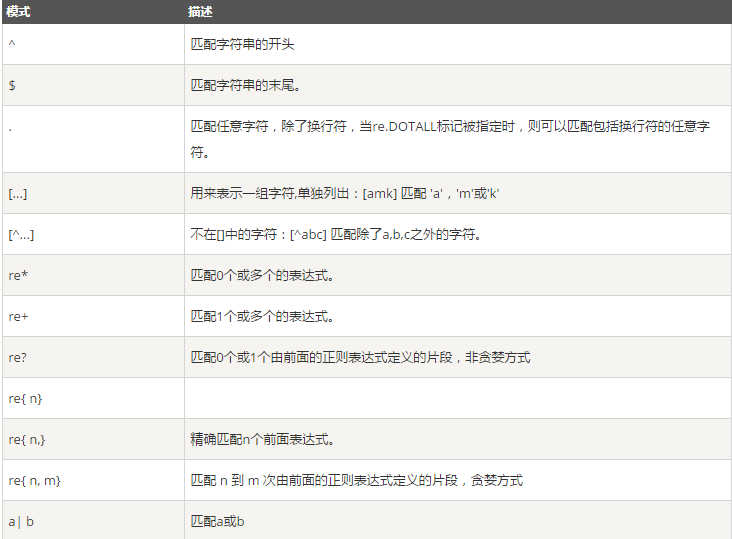
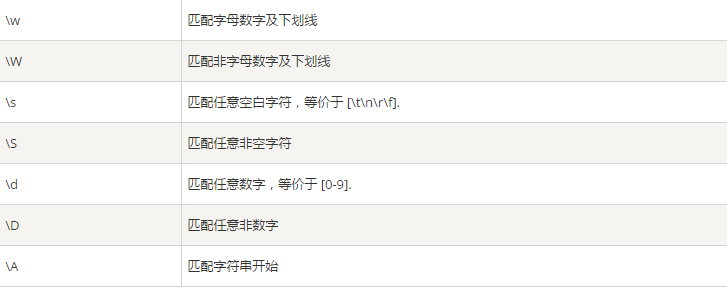
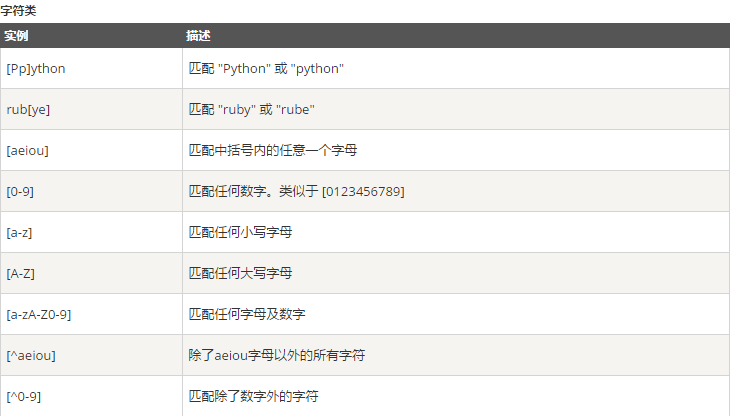
#正则匹配
# w与W
>>> print(re.findall('w','as213df_*|'))
['a', 's', '2', '1', '3', 'd', 'f', '_']
>>> print(re.findall('W','as213df_*|'))
['*', '|']
>>> print(re.findall('awb','a_b a3b aEb a*b'))
['a_b', 'a3b', 'aEb']
>>>
# s与S
>>> print(re.findall('s','a b
c d'))
[' ', '
', ' ']
>>> print(re.findall('S','a b
c d'))
['a', 'b', 'c', 'd']
>>>
#d与D
>>> print(re.findall('d','a123bcdef'))
['1', '2', '3']
>>> print(re.findall('D','a123bcdef'))
['a', 'b', 'c', 'd', 'e', 'f']
>>>
#
与
>>> print(re.findall('
','a123
bcdef'))
['
']
>>> print(re.findall(' ','a123 bc d ef'))
[' ', ' ', ' ']
>>>
# ^h
>>> print(re.findall('^h','hello egon hao123'))
['h']
>>> print(re.findall('^h','ello egon hao123'))
[]
>>>
# $
>>> print(re.findall('3$','e3ll3o e3gon hao123'))
['3']
>>> print(re.findall('3$','e3ll3o e3gon hao123asdf'))
[]
>>>
# .
>>> print(re.findall('a.c','abc a1c a*c a|c abd aed ac'))
['abc', 'a1c', 'a*c', 'a|c']
>>>
#让点能够匹配到换行符
>>> print(re.findall('a.c','abc a1c a*c a|c abd aed a
c',re.S))
['abc', 'a1c', 'a*c', 'a|c', 'a
c']
>>>
# []
>>> print(re.findall('a[1,2
]c','a2c a,c abc a1c a*c a|c abd aed a
c'))
['a2c', 'a,c', 'a1c', 'a
c']
>>> print(re.findall('a[0-9]c','a2c a,c abc a1c a*c a|c abd aed a
c'))
['a2c', 'a1c']
>>> print(re.findall('a[0-9a-zA-Z*-]c','a1c abc a*c a-c aEc'))
['a1c', 'abc', 'a*c', 'a-c', 'aEc']
>>> print(re.findall('a[^0-9]c','a1c abc a*c a-c aEc'))
['abc', 'a*c', 'a-c', 'aEc']
#* + ? {n,m} #重复
#ab* a ab abbbbbbbbbbbbbbbbbbbbbbbbbbb
>>> print(re.findall('ab*','a'))
['a']
>>> print(re.findall('ab*','abbbbbb'))
['abbbbbb']
>>> print(re.findall('ab*','bbbbbb'))
[]
>>>
>>> print(re.findall('ab+','a'))
[]
>>> print(re.findall('ab+','abbbbbb'))
['abbbbbb']
>>> print(re.findall('ab+','bbbbbb'))
[]
>>>
#ab[123] ab1 ab2 ab3
>>> print(re.findall('ab[123]','abbbbb123'))
[]
>>> print(re.findall('ab[123]','ab1 ab2 ab3 abc1'))
['ab1', 'ab2', 'ab3']
>>>
#ab[123] ab1+ ab2+ ab3+
>>> print(re.findall('ab[123]+','ab11111111 ab2 ab3 abc1'))
['ab11111111', 'ab2', 'ab3']
>>>
#ab[123] ab[123][123][123]
>>> print(re.findall('ab[123]+','ab1 ab2 ab3 ab4 ab122'))
['ab1', 'ab2', 'ab3', 'ab122']
>>>
#abbb
>>> print(re.findall('ab{3}','ab1 abbbbbbbb2 abbbbb3 ab4 ab122'))
['abbb', 'abbb']
>>> print(re.findall('ab{3,4}','ab1 abbb123 abbbb123 abbbbbt'))
['abbb', 'abbbb', 'abbbb']
>>> print(re.findall('ab{3,}','ab1 abbb123 abbbb123 abbbbbt'))
['abbb', 'abbbb', 'abbbbb']
>>> print(re.findall('ab{0,}','a123123123 ab1 abbb123 abbbb123 abbbbbt'))
['a', 'ab', 'abbb', 'abbbb', 'abbbbb']
>>> print(re.findall('ab{1,}','a123123123 ab1 abbb123 abbbb123 abbbbbt'))
['ab', 'abbb', 'abbbb', 'abbbbb']
>>>