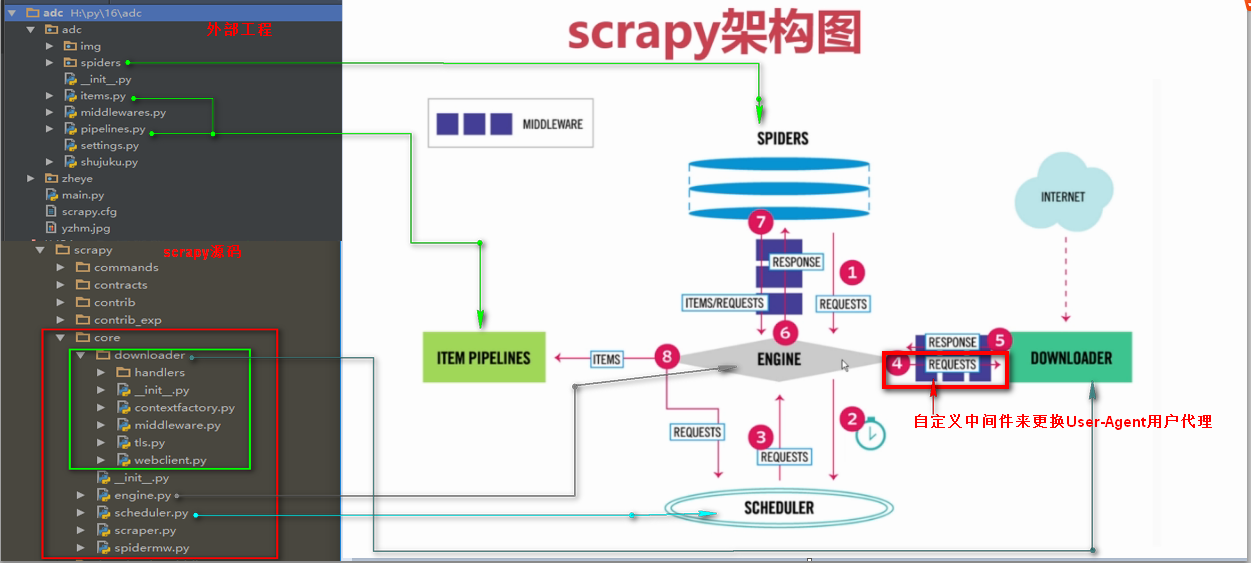
downloadmiddleware介绍
中间件是一个框架,可以连接到请求/响应处理中。这是一种很轻的、低层次的系统,可以改变Scrapy的请求和回应。也就是在Requests请求和Response响应之间的中间件,可以全局的修改Requests请求和Response响应
UserAgentMiddleware()方法,默认中间件
源码里downloadmiddleware里的useragent.py下的UserAgentMiddleware()方法,默认中间件
我们可以从源码看到当Requests请求时默认的User-Agent是Scrapy,这个很容易被网站识别而拦截爬虫

我们可以修改默认中间件UserAgentMiddleware()来随机更换Requests请求头信息的User-Agent浏览器用户代理
第一步、在settings.py配置文件,开启中间件注册DOWNLOADER_MIDDLEWARES={ }
将默认的将默认的UserAgentMiddleware设置为None,或者设置成最大就最后执行,这样我们自定义的中间件修改默认的user_agent就会先执行
settings.py配置文件

# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = { #开启注册中间件
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, #将默认的UserAgentMiddleware设置为None
}
第二步、安装浏览器用户代理模块fake-useragent 0.1.7
fake-useragent 是一个专门用于爬虫伪装浏览器User-Agent请求头的模块。此模块在线维护了各个浏览器的各种版本库,提供我们使用
在线各种浏览器信息:http://fake-useragent.herokuapp.com/browsers/0.1.7 0.1.7版本,fake-useragent会随机到这里调用浏览器代理
首先安装这个模块
pip install fake-useragent
使用说明:
#!/usr/bin/env python # -*- coding:utf8 -*- from fake_useragent import UserAgent #导入浏览器代理模块 ua = UserAgent() #实例化浏览器代理类 ua.ie #随机获取IE类型的代理 # Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US); ua.msie #随机获取msie类型的代理,下面的相同 # Mozilla/5.0 (compatible; MSIE 10.0; Macintosh; Intel Mac OS X 10_7_3; Trident/6.0)' ua['Internet Explorer'] # Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; GTB7.4; InfoPath.2; SV1; .NET CLR 3.3.69573; WOW64; en-US) ua.opera # Opera/9.80 (X11; Linux i686; U; ru) Presto/2.8.131 Version/11.11 ua.chrome # Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2' ua.google # Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4) AppleWebKit/537.13 (KHTML, like Gecko) Chrome/24.0.1290.1 Safari/537.13 ua['google chrome'] # Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11 ua.firefox # Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:16.0.1) Gecko/20121011 Firefox/16.0.1 ua.ff # Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:15.0) Gecko/20100101 Firefox/15.0.1 ua.safari # Mozilla/5.0 (iPad; CPU OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5355d Safari/8536.25 # and the best one, random via real world browser usage statistic ua.random #随机获取各种浏览器类型的代理,
更多使用 https://pypi.python.org/pypi/fake-useragent/0.1.7
第三步、自定义中间件来全局随机更换Requests请求头信息的User-Agent浏览器用户代理
在middlewares.py文件里,自定义中间件
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
from fake_useragent import UserAgent #导入浏览器用户代理模块
class RequestsUserAgentmiddware(object): #自定义浏览器代理中间件
#随机更换Requests请求头信息的User-Agent浏览器用户代理
def __init__(self,crawler):
super(RequestsUserAgentmiddware, self).__init__() #获取上一级父类基类的,__init__方法里的对象封装值
self.ua = UserAgent() #实例化浏览器用户代理模块类
self.ua_type = crawler.settings.get('RANDOM_UA_TYPE','random') #获取settings.py配置文件里的RANDOM_UA_TYPE配置的浏览器类型,如果没有,默认random,随机获取各种浏览器类型
@classmethod #函数上面用上装饰符@classmethod,函数里有一个必写形式参数cls用来接收当前类名称
def from_crawler(cls, crawler): #重载from_crawler方法
return cls(crawler) #将crawler爬虫返回给类
def process_request(self, request, spider): #重载process_request方法
def get_ua(): #自定义函数,返回浏览器代理对象里指定类型的浏览器信息
return getattr(self.ua, self.ua_type)
request.headers.setdefault('User-Agent', get_ua()) #将浏览器代理信息添加到Requests请求
第四步、将我们自定义的中间件注册到settings.py配置文件,的DOWNLOADER_MIDDLEWARES里
注意一点要把默认的UserAgentMiddleware中间件设置为None,使其我们自定义的中间件生效
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = { #开启注册中间件
'adc.middlewares.RequestsUserAgentmiddware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, #将默认的UserAgentMiddleware设置为None
}
我们可以打断点调试一下,看看是否生效
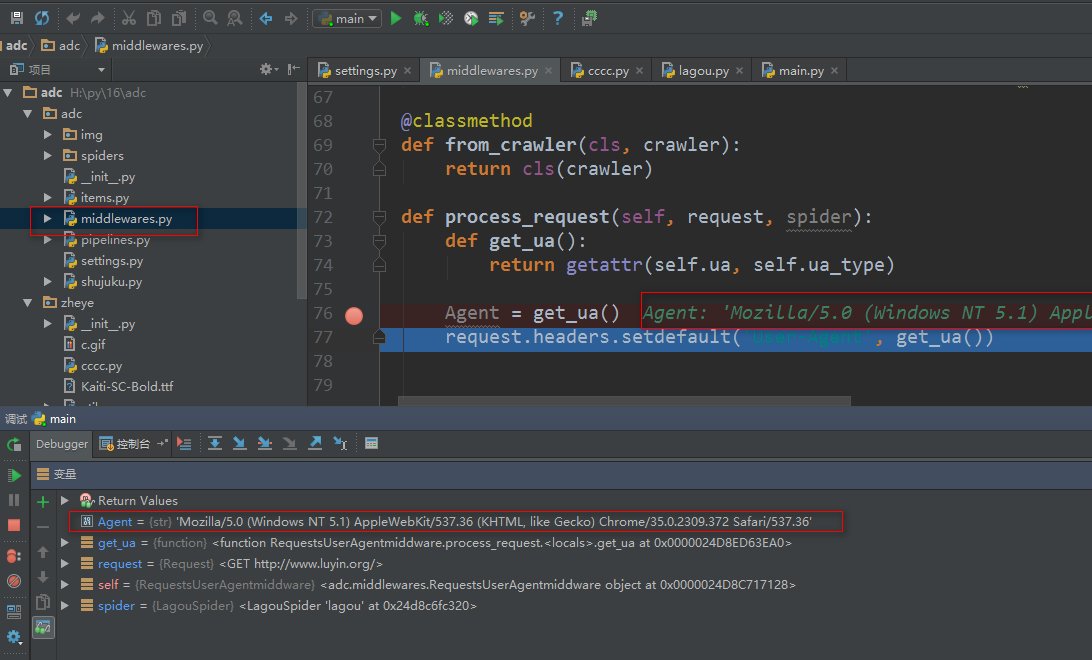
原理说明图