1. mongodb是什么?
NoSQL 非关系型数据库,主要用于数据的海量存储。分为server数据存储端和client数据操作端。
关系型与非关系型数据库的区别?
sql:数据库--表--数据
nosql:数据库---集合--文档
2.mongoddb优势
1. 扩展性
2. 大数据型,高性能
3. 灵活的数据模型
3.启动
1. 本地测试启动:功能受限,验证数据库的完整功能
+ ps aux|grep mongodb
+ ps -- process 进程
+ ps aux 显示所有进程
+ grep --- 文件查询
+ grep "#" /etc/mongodb.conf --- 把文件中所有带被注释的行显示出来
+ grep -v "#" /etc/mongodb.conf --- 把文件中所有有用的行显示出来
sudo service mongodb start
sudo service mongodb stop
2. 生产方式启动:
4.使用
4.1 数据库的操作
查看当前数据库: db 默认为test
查看磁盘上的数据库: show dbs/ show databases
注:db --- > test ---> show dbs ---> local 0.000GB 是因为test数据库不在磁盘上,在内存中。
4.2. 创建数据库
1.use python
2.db.test.insert({"key":"value"})
3.show dbs ---> python
4.3 删除数据库
db.dropDatabase()
4.4 集合的操作
1.选择要使用的数据库 use new
2.db.createCollection("new_col") 如果new这个数据库存在就在里面创建集合,如果数据库不存在,就先创建数据库new,然后在创建集合
默认是无限容量:cap:true
3.show dbs
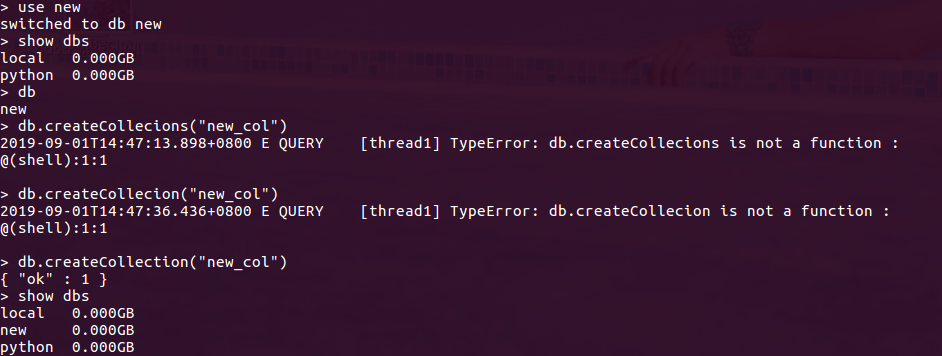
4.db.new_col 查看集合 show.collections 查看指定数据库下的所有集合
5.db.new_col.insert({"a":"1"}) 指定集合插入数据
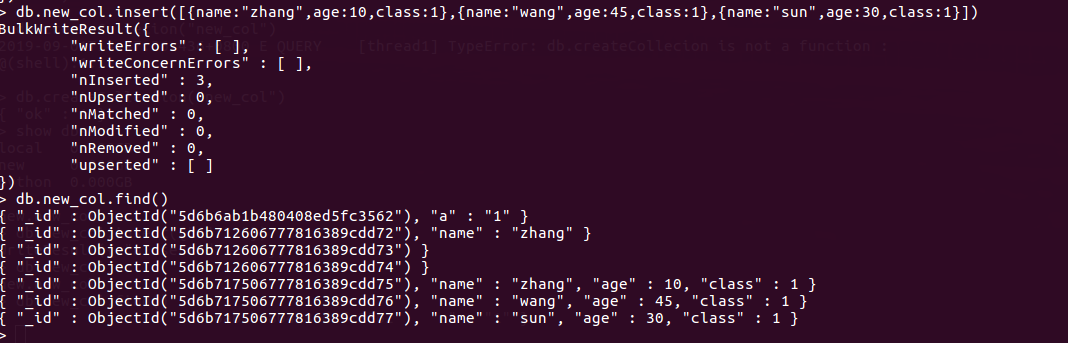
6.db.new_col.find() 查看指定集合的数据

说明:集合会自动插入一条id的字段,是一个十二位的十六进数。
前八位:5d6b6ab1是时间戳
接着六位:b48040 机器码,唯一标记机器
接着四位:8ed5 是进程号
最后六位:是简单的增量值
4.4 数据的增删改查
批量插入数据
[{ } , { } , { }]
db.new_col.insert([{name:"zhang",age:10,class:1},{name:"wang",age:11,class:1},{name:"sun",age:12,class:1}])
修改数据 --- 修改数据的依据是通过 "_id"的值取找,找到了之后,在id后面的字段判断值是否一致,不一致,把新的值覆盖原来的值。
db.new_col.save({"_id" : ObjectId("5d6b717506777816389cdd77"),"name":"mongo","age":100,"class":100})

如果:通过id值找不到,就会将后面的值作为新地值插入,id的值为查找的id的值。
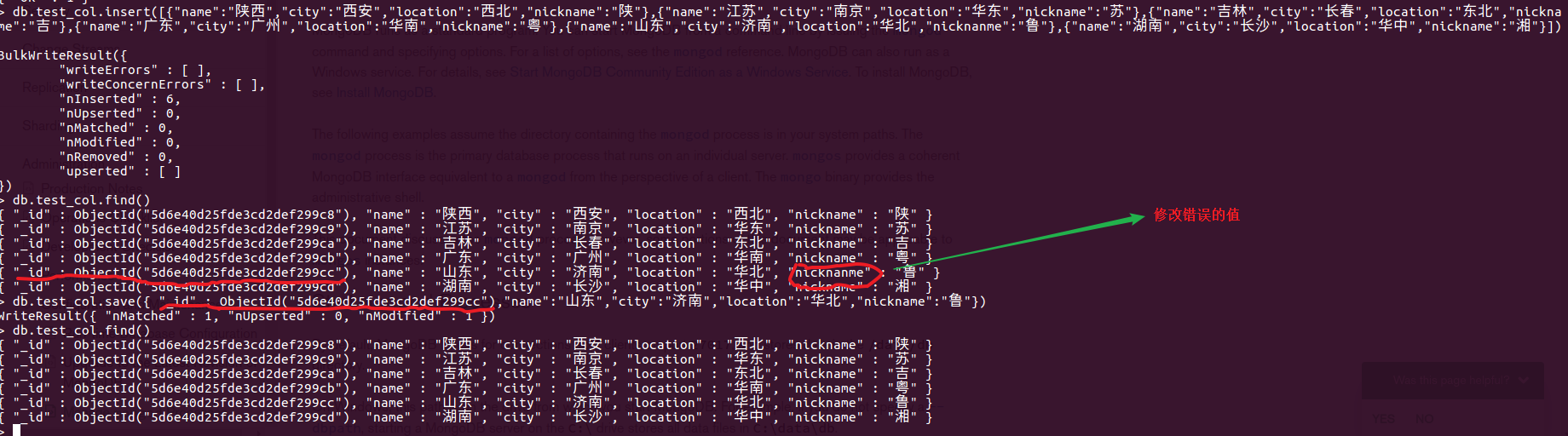
查询数据
一般查询:db.new_col.find()
条件查询:
# 新插入一组数,进行演示。
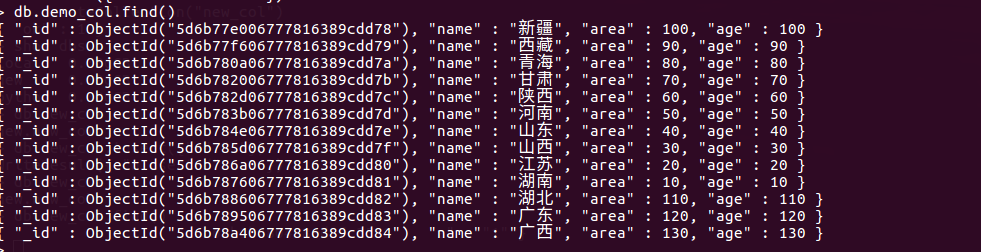
db.demo_col.findOne()

db.demo_col.find().pretty() 展示部分截图
1. 等于查询
db.demo_col.find({age:10})

2. 大于查询
db.demo_col.find({age:{$gt:50}}) $get 大于等于 $lt 小于 $lte小于等于

4. 不等于查询
db.demo_col.find({age:{$ne:50}})
5. and查询
db.demo_col.find({$and:[{area:{$gte:100}},{age:{$ne:110}}]}) 多条件查询 find( $and : [ { 查询条件1 } , { 查询条件2 } ])

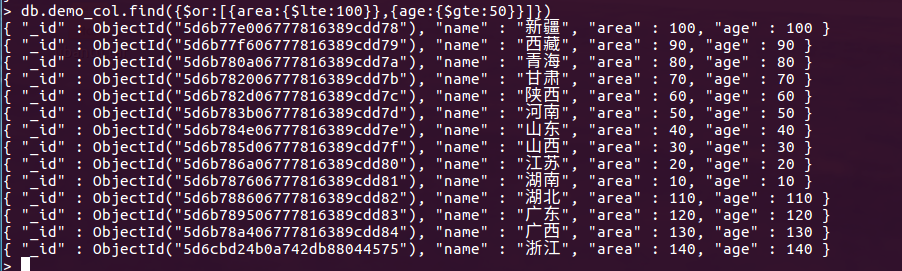
6. or 查询
db.demo_col.find( { $or : [ { area : { $lte: 100} },{ age : { $gte : 50} } ] } ) 多条件查询 find( $ or : [ { 查询条件1 } , { 查询条件2 } ])
7. 范围运算符 in nin
db.demo_col.find({age:{$in:[10,30,50,70,90,110,130]}})

8.模糊正则查询
db.demo_col.find({name:{regex:"^湖"}})

9.复杂查询-自定义查询
db.demo_col.find({$where:function(){return this.age> 100 }})

10 查询结果的操作
limit(5)
db.demo_col.find().limit(5)

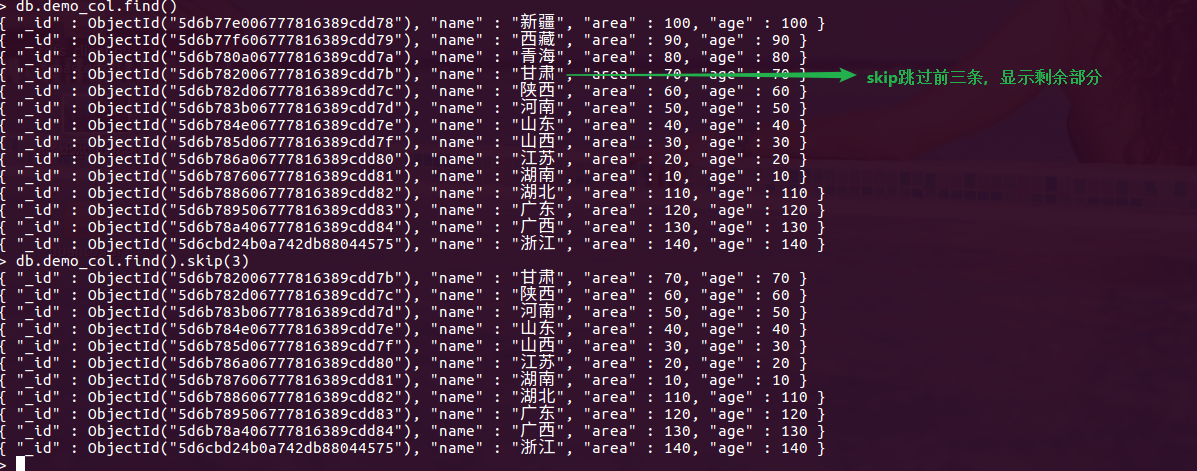
skip(3)
db.demo_col.find().skip(3)
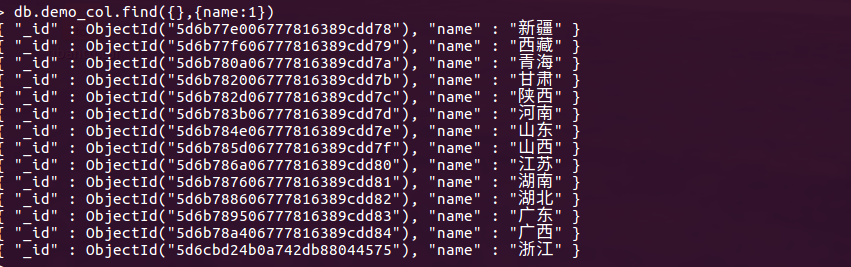
投影操作
显示指定的字段的查询结果,类似于mysql中的显示部分字段的查询结果
select * from demo_table;
select name,age from demo_table;
db.demo_col.find({},{name:1}) 显示一个字段 db.demo_col.find({},{name:1,age:1}) 显示多个字段
# 1 代表显示 0 代表不显示 字段设置不能0,1共存,但是_id:0,name:1 id为0可以和其他字段的1共存
排序操作
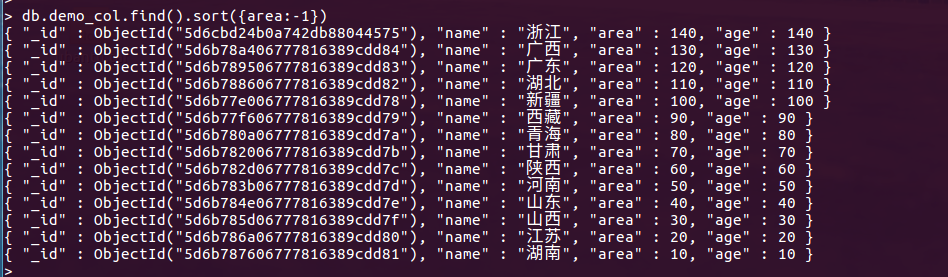
db.demo_col.find().sort({area:-1})
1代表升序,-1代表降序
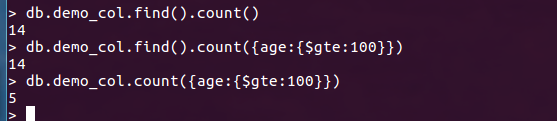
统计操作
db.demo_col.find().count()
db.demo_col.count({age:{$gte:100}})
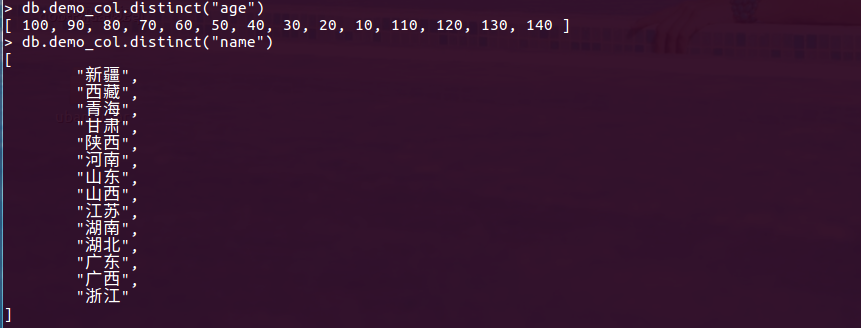
去重操作
db.demo_col.distinct("age")
更新操作
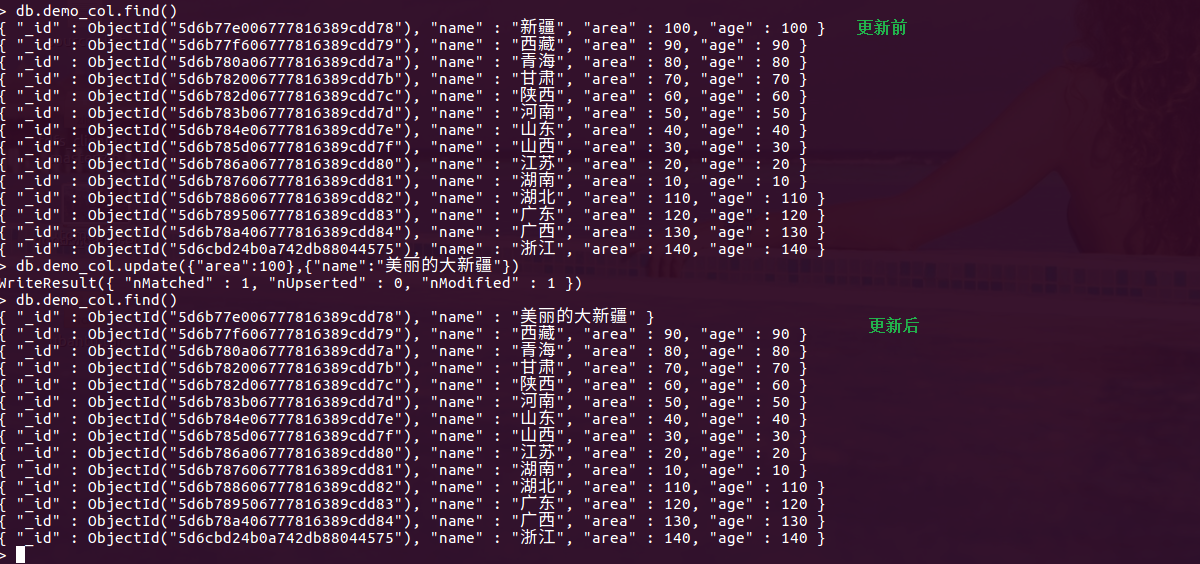
全文档覆盖更新
db.demo_col.updata({查询条件},{更新条件})
db.demo_col.update({"area":100},{"name":"美丽的大新疆"}) 更新后只保留原来数据的_id 和 name字段,其他字段都会变没有 -----覆盖更新
db.test_col.update({"name":"陕西"},{$set:{"city":"长安"}}) ---- 不覆盖更新

db.test_col.update({},{$set:{"nation":"中国"}},{multi:true}) 全部追加
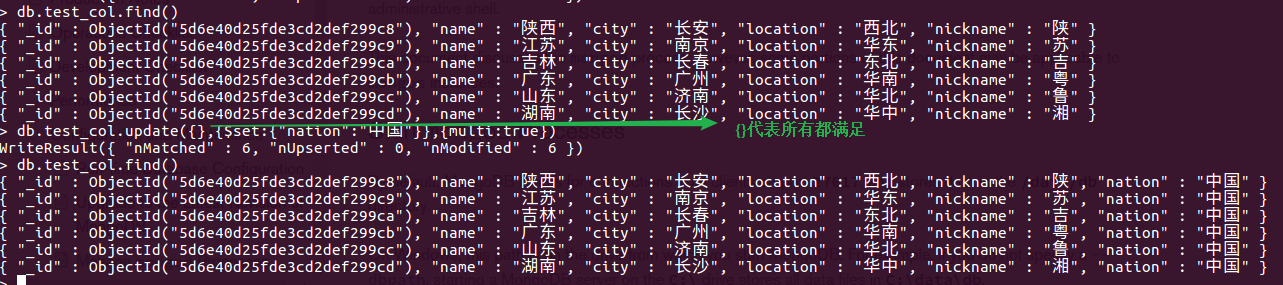
db.test_col.update({"name":"福建"},{$set:{"city":"福州","location":"华东","nickname":"闽","nation":"中国"}},{upsert:true})找到就更新,找不到就添加

但是:这个nation和nickname的位置,看着好难受
删除数据
db.test_col.remove({"name":"福建"},{justOne:true})

mongodb 的聚合操作
聚合是基于数据处理的聚合管道,每个文档通过一个由多阶段组成的管道,可以对每个阶段的管道进行分组,过滤等功能,然后精活一系列的处理,输出相应的结果。第一个管道产生的结果,会变成第二个管道的输入值,加入第一个管道进行了投影,那么第二个管道只能拿到部分数据。

db.集合名称.aggregate({管道:{表达式}})
管道命令之$group:是聚合命令中使用最多的一个命令,用来将集合中的文档进行分组,可用于统计结果。
db.test_col.aggregate({$group:{_id:"$nation"}})
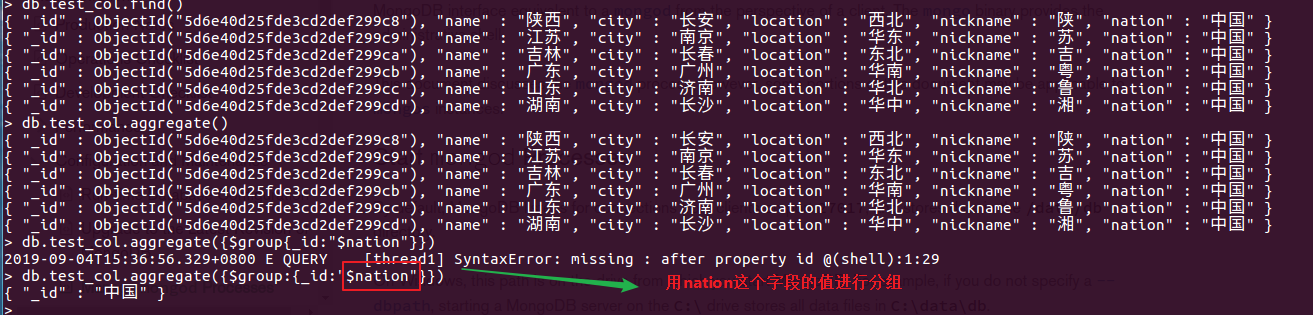
db.test_col.aggregate({$group:{_id:"$nation",counter:{$sum:1}}})

新建一组集合数据,用来练习group
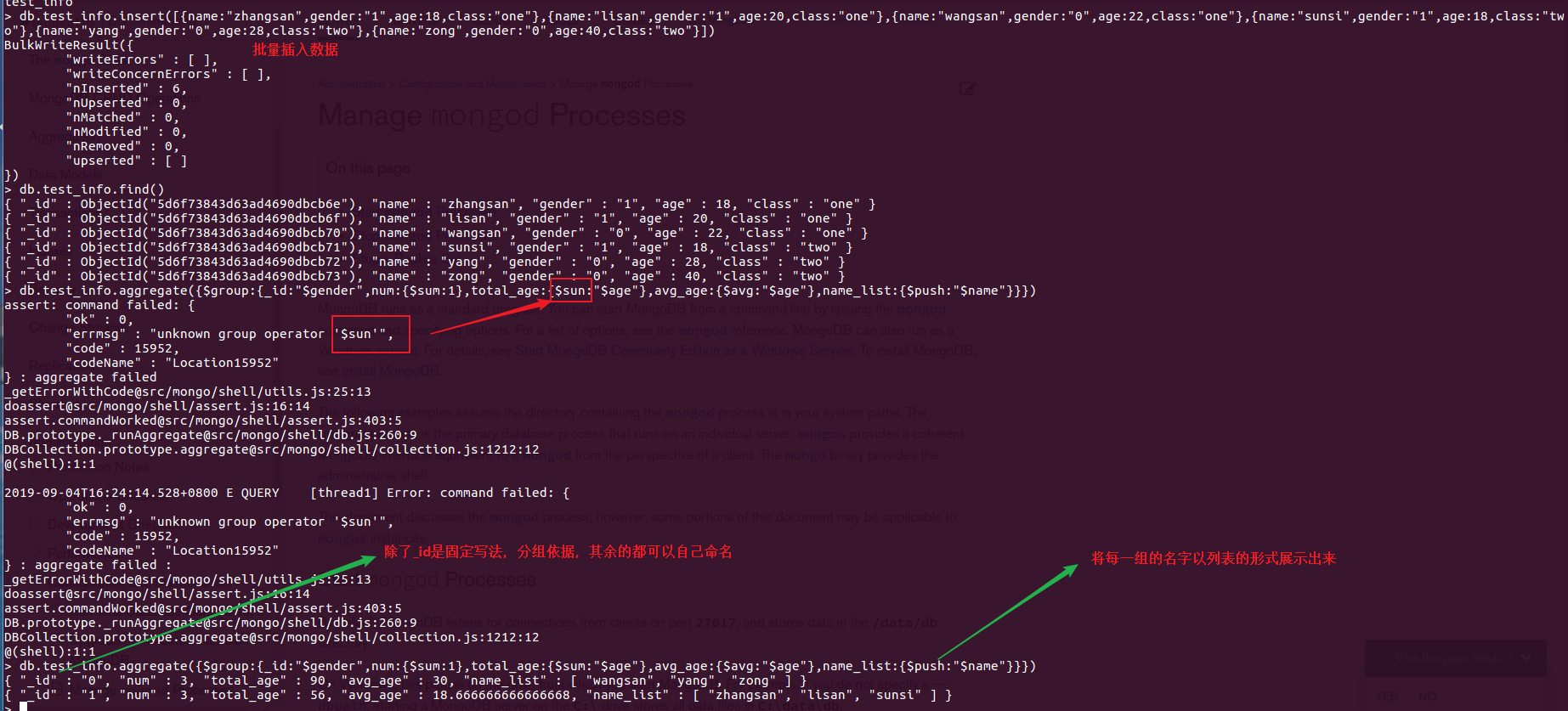
管道命令之$match:用于数据过滤
db.test_info.aggregate({$match:{class:"two"}})

db.test_info.aggregate({$match:{class:"one"}},{$group:{_id:"$gender",name_list:{$push:"$name"}}})

db.test_info.aggregate({$match:{name:/z/}}) 模糊匹配高级搜索

# TODO
mongodb 索引
不创建索引,就会遍历每个数据,进行比较,若刚好要查的数据位于最会一个,则查询速度最慢。
索引:升序创建,降序创建
索引加快搜索速度的原理:二分查找结合二叉树
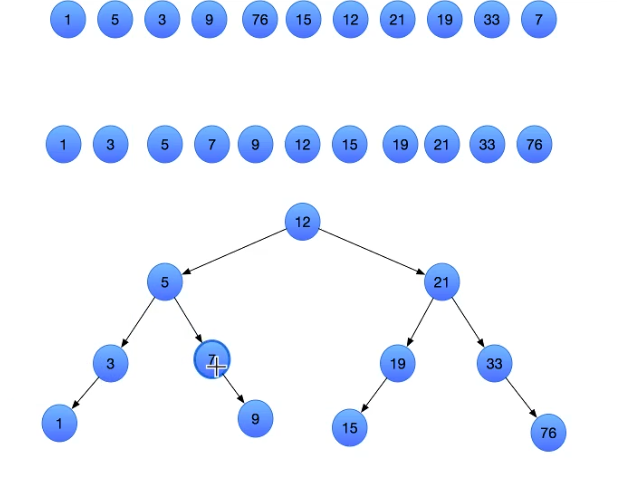
查找7,排序前,需要11次比较。
排序后,将数据按照二叉树的方式进行存储,查找7,需要3次比较。
mongodb创建索引的目的:1. 加快数据查询速度,2.进行数据去重(唯一索引进行去重)
db.集合名.ensureIndex({属性:1}) , 1升序,-1降序
插入10万条数据:for(i=0;i<100000;i++){db.num.insert({name:"name"+i,num:i})}

db.test_num.find({num:99999}).explain("executionStats") 查看语句的详细执行信息
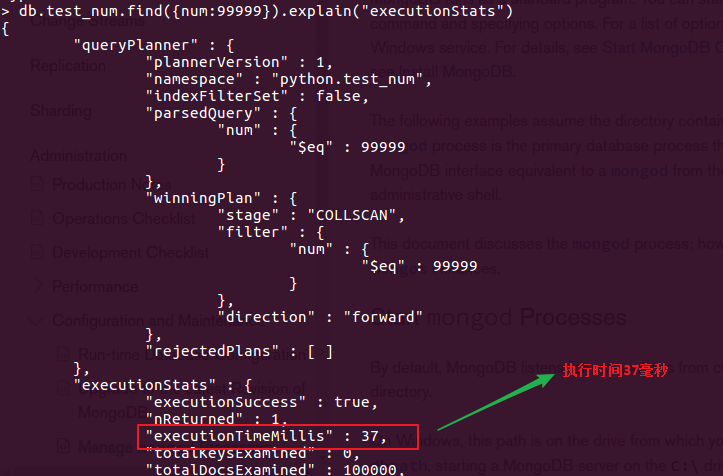
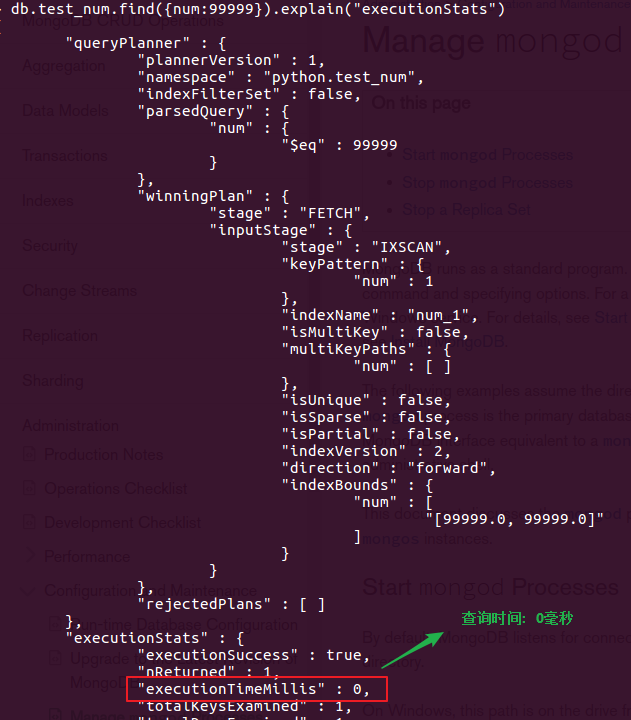
db.test_num.ensureIndex({num:1}) 创建索引
db.test_num.find({num:99999}).explain("executionStats")
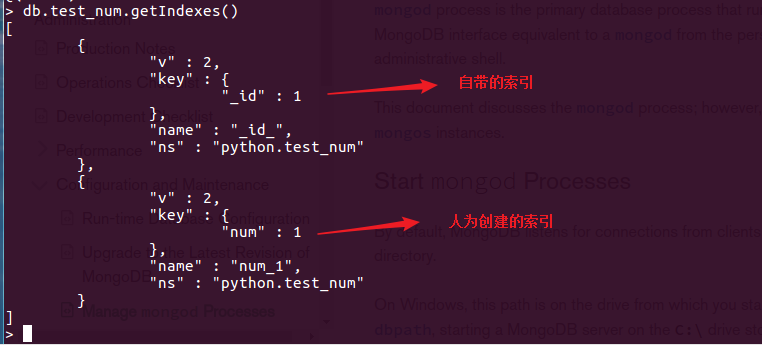
查询索引 db.test_num.getIndexes()
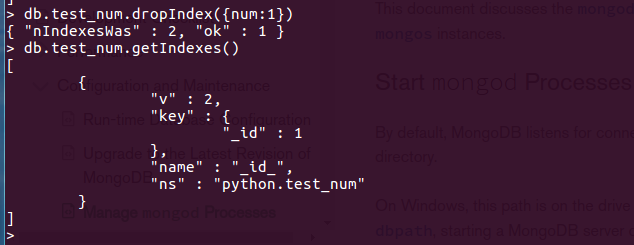
删除索引:db.test_num.dropIndex({num:1})
创建唯一索引,用来去重
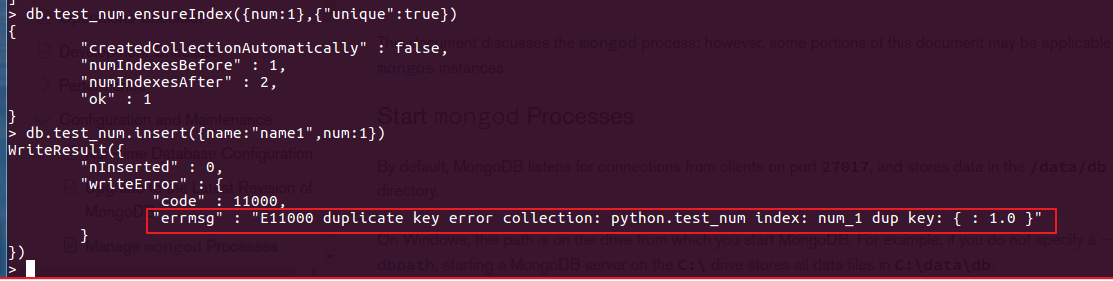
db.test_num.ensureIndex({num:1},{"unique":true})
索引注意事项:
1.查询操作非常频繁才使用索引。
2. 升序降序不影响查询速度。
3.数据量大,读写非常频繁,创建索引影响写入速度。
要是写入也频繁,查询也频繁,可以使用读写分离,主负责写,一个负责写,不设置索引,定时同步到另一个mingodb,另一个进行读,设置索引。
# TODO 权限
二 python使用mongodb
# 配置mongodb from pymongo import MongoClient my_collection = MongoClient(host="127.0.0.1",port=27017) db = my_collection[database][collection]
(一)mongodb取数据的问题
# 从mongodb中直接取数据,因为objectid是一个objects类型,直接取值,然后jsonify给前端,报错 TypeError: Object of type ObjectId is not JSON serializable # 解决办法 from flask import Flask, jsonify from pymongo import MongoClient from bson import json_util app = Flask(__name__) client = MongoClient(host="127.0.0.1",port=27017) collection = client["pzgl_manage"]["pgxx"] @app.route("/") def index(): collection.insert_one({"name":"zhang","age":10}) ret = collection.find_one({"name":"zhang"}) return json_util.dumps(ret) if __name__ == '__main__': app.run(debug=True) # 前端显示 # {"_id": {"$oid": "5dd28b5d01a5afc41caa0c84"}, "name": "zhang", "age": 10} # 从mongodb中取一组值,取出来的是一个游标对象,必须循环后,才能获得每一个值,怎么将这一组值一次return给前端。 # 解决办法一:人为的构造字典,值为列表,列表里面包含每一个查询结果 from flask import Flask, jsonify from pymongo import MongoClient from bson import json_util app = Flask(__name__) client = MongoClient(host="127.0.0.1",port=27017) collection = client["pzgl_manage"]["pzxx"] @app.route("/") def index(): ret = collection.find() ret_li = list() for r in ret: ret_li.append(r) ret_dict = {"ret_li":ret_li} return json_util.dumps(ret_dict) if __name__ == '__main__': app.run(debug=True) # 前端显示 {"ret_li": [{"_id": {"$oid": "5dd24fd26567f28b57b1b8c3"}, "sheep_number": "1", "equipement_number": "88888888", "s_detail": [{"p_time": "2019-01-01", "p_type": "\u672c\u4ea4", "s_time": "2019-01-02", "o_number": 1}, {"p_time": "2020-01-01", "p_type": "\u672c\u4ea4", "s_time": "2020-01-02", "o_number": 2}]}, {"_id": {"$oid": "5dd252096567f28b57b1b90c"}, "sheep_number": "2", "equipement_number": "88888888", "s_detail": [{"p_time": "2019-01-02", "p_type": "\u51bb\u7cbe", "d_type": "\u5c71\u7f8a", "d_count": 100, "d_number": 20191118}, {"p_time": "2020-01-02", "p_type": "\u51bb\u7cbe", "d_type": "\u5c71\u7f8a", "d_count": 100, "d_number": 20200102}]}, {"_id": {"$oid": "5dd253506567f28b57b1b944"}, "sheep_number": "3", "equipement_number": "88888888", "s_detail": [{"p_time": "2019-01-03", "s_time": "2019-01-04", "p_pyte": "\u51bb\u7cbe", "d_type": "\u5976\u725b", "d_count": 100, "d_num": 20190103, "e_sex": "\u6027\u63a7"}, {"p_time": "2020-01-03", "s_time": "2020-01-04", "p_pyte": "\u51bb\u7cbe", "d_type": "\u5976\u725b", "d_count": 100, "d_num": 20200103, "e_sex": "\u666e\u901a"}]}]} # 问题来了,前端对于汉字的解析不是很好,怎么解决这个问题,通过下面的json的例子,可以解决 return json.dumps(json.loads(json_util.dumps(ret_dict)),ensure_ascii=False) # 前端显示 {"ret_li": [{"_id": {"$oid": "5dd24fd26567f28b57b1b8c3"}, "sheep_number": "1", "equipement_number": "88888888", "s_detail": [{"p_time": "2019-01-01", "p_type": "本交", "s_time": "2019-01-02", "o_number": 1}, {"p_time": "2020-01-01", "p_type": "本交", "s_time": "2020-01-02", "o_number": 2}]}, {"_id": {"$oid": "5dd252096567f28b57b1b90c"}, "sheep_number": "2", "equipement_number": "88888888", "s_detail": [{"p_time": "2019-01-02", "p_type": "冻精", "d_type": "山羊", "d_count": 100, "d_number": 20191118}, {"p_time": "2020-01-02", "p_type": "冻精", "d_type": "山羊", "d_count": 100, "d_number": 20200102}]}, {"_id": {"$oid": "5dd253506567f28b57b1b944"}, "sheep_number": "3", "equipement_number": "88888888", "s_detail": [{"p_time": "2019-01-03", "s_time": "2019-01-04", "p_pyte": "冻精", "d_type": "奶牛", "d_count": 100, "d_num": 20190103, "e_sex": "性控"}, {"p_time": "2020-01-03", "s_time": "2020-01-04", "p_pyte": "冻精", "d_type": "奶牛", "d_count": 100, "d_num": 20200103, "e_sex": "普通"}]}]} # 解决办法二:不人为构造列表,直接用json进行转换 @app.route("/") def index(): ret = collection.find() return json.dumps(json.loads(json_util.dumps(ret)),ensure_ascii=False) # 这样直接给前端范围一个列表 # 前端显示 [{"_id": {"$oid": "5dd24fd26567f28b57b1b8c3"}, "sheep_number": "1", "equipement_number": "88888888", "s_detail": [{"p_time": "2019-01-01", "p_type": "本交", "s_time": "2019-01-02", "o_number": 1}, {"p_time": "2020-01-01", "p_type": "本交", "s_time": "2020-01-02", "o_number": 2}]}, {"_id": {"$oid": "5dd252096567f28b57b1b90c"}, "sheep_number": "2", "equipement_number": "88888888", "s_detail": [{"p_time": "2019-01-02", "p_type": "冻精", "d_type": "山羊", "d_count": 100, "d_number": 20191118}, {"p_time": "2020-01-02", "p_type": "冻精", "d_type": "山羊", "d_count": 100, "d_number": 20200102}]}, {"_id": {"$oid": "5dd253506567f28b57b1b944"}, "sheep_number": "3", "equipement_number": "88888888", "s_detail": [{"p_time": "2019-01-03", "s_time": "2019-01-04", "p_pyte": "冻精", "d_type": "奶牛", "d_count": 100, "d_num": 20190103, "e_sex": "性控"}, {"p_time": "2020-01-03", "s_time": "2020-01-04", "p_pyte": "冻精", "d_type": "奶牛", "d_count": 100, "d_num": 20200103, "e_sex": "普通"}]}]
(二)取出的数据有中文,前端无法显示问题
# 解决办法:ensure_ascii:False @app.route("/") def index(): ret = {"name":"张"} return json.dumps(ret,ensure_ascii=False) if __name__ == '__main__': app.run(debug=True)
(三) 增删改查
# 查询单条数据 query = {"sheep_number":"1"} db.find_one(query) # 查询带有过滤条件 加入要过滤id,其他字段都保留则,设置查询条件为 query = {"sheep_number":"1"} limit = {"_id":0} # 将不需要显示的字段以键值对的形式设置,值为0 db.find_one(query,limit) # 查询所有数据 db.find(query) # 增加一条数据 query = {"sheep_number":"1"} insert_info = {"a":1,"b":2} 先查询到数据,在给指定的字段增加信息 db.update(query,{"$addToSet":{"指定的字段名称":insert_info}}) # 修改一条数据 query = {"sheep_number":"1"} alter_info = {"sheep_number":"100"} db.update_one(query,{"$set":alter_info}) # 删除一条数据 query = {"sheep_number":"1"} db.delete_one(query)