hive的排序,分組练习
数据:
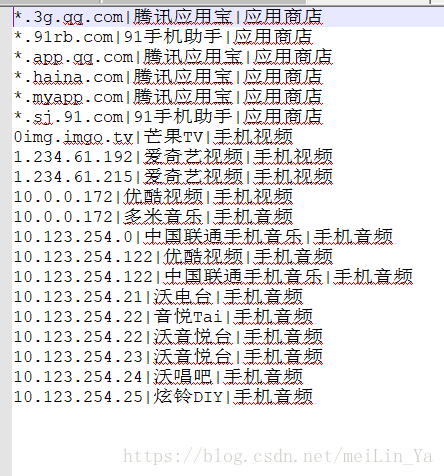
添加表和插入数据(数据在Linux本地中)
create table if not exists tab1(
IP string,
SOURCE string,
TYPE string
)
row format delimited fields terminated by '|'
stored as textfile;
load data local inpath '/home/data/data1.txt' into table tab1;
1.问题:(top10)按照来源排序,访问量高的排最上面
select source,count(*) num
from tab1
group by source
order by num desc;select 查询在order by 前

2.问题:(推荐系统)给一个用户ip地址,得到用户经常访问的应用类型后,推荐用户同种类型的其他应用

数据二:
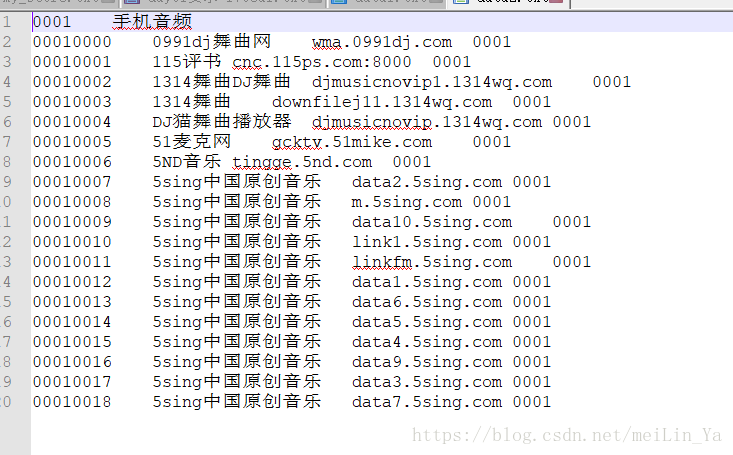
建表,填数据:
create table if not exists tab2(
id string,
name string,
url string,
pid string
)
row format delimited fields terminated by ' '
stored as textfile;
load data local inpath '/home/data/data2.txt' into table tab2;
1.问题:(数据清洗)合并name与url,格式为 NAME:name|URL:url
select concat('NAME:',name,'|','URL:',url)
from tab2
where name is not null and url is not null;
数据三:
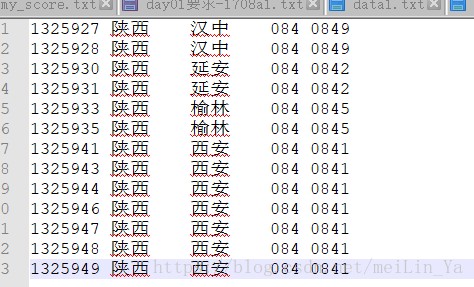
表的建立和数据插入
create table if not exists tab4(
no string,
province string,
city string,
pid string,
cid string
)
row format delimited fields terminated by ' '
stored as textfile;
load data local inpath '/home/data/data4.txt' into table tab4;1.问题:从源数据中筛出pid与省份、cid与城市,并且创建新表保存 去重 distinct
这里使用加行键的方法,实行唯一标识。
select pid,province
from tab4
group by pid,province
limit 1
select t1.cid,t1.city,t1.rank
from(
select cid,city,row_number() over (partition by cid order city) rank
from tab4
group by cid,city) t1
where t1.rank=1;

数据四:
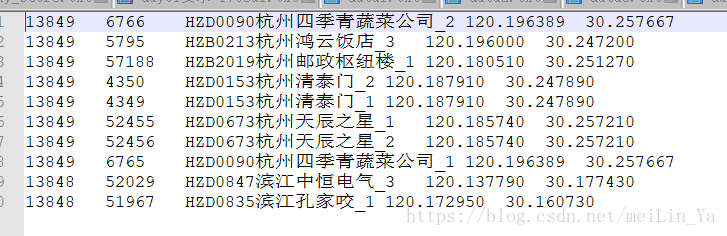
新建表以及添加数据
create table if not exists tab5(
lac string,
cellid string,
cell_name string,
longitude string,
latitude string
)
row format delimited fields terminated by ' '
stored as textfile;
load data local inpath '/home/data/data5.txt' into table tab5;1.问题:从cell_name列中截取需要的部分,例如 HZD0090,截取D0090杭州四季青蔬菜公司,截取D0090

数据五:

建表+添加数据
create table if not exists tab6(
id string,
service string
)
row format delimited fields terminated by ' '
stored as textfile;
load data local inpath '/home/data/data6.txt' into table tab6;问题:去除所有父类服务,只要子类服务(id 是字符串类型)
select * from tab6 where id>100
数据六:

添加数据:
create table if not exists tab7(
id string,
type string,
sagem string
)
row format delimited fields terminated by ' '
stored as textfile;
load data local inpath '/home/data/data7.txt' into table tab7;
问题:按照设备类型,统计出现的频率
select type,count(*)
from tab7
group by type;
数据七:

问题:去重后存入到新表中
select col,row_number() over (partition by col order by col) rank
from tab10
group by col;