Hadoop---HDFS
HDFS 性能详解
HDFS 天生是为大规模数据存储与计算服务的,而对大规模数据的处理目前还有没比较稳妥的解决方案。 HDFS 将将要存储的大文件进行分割,分割到既定的存储块(Block)中进行了存储,并通过本地设定的任务节点进行预处理,从而解决对大文件存储与计算的需求。在实际工作中,除了某些尺寸较大的文件要求进行存储及计算,更多时候是会产生并存储无数的小尺寸文件。而对于小尺寸文件的处理, HDFS 没有要求使用者进行特殊的优化,也就是说可以通过普通的编程与压缩方式进行解决。对于大部分的文件来说,一旦文件生成完毕,更多的是对文件进行读取而非频繁的修改。 HDFS 对于普通文件的读取操作来说,一般情况下主要分成两种。大规模的持续性读取与小型化随机读取。针对这两种读取方式, HFDS 分别采取了不同的对应策略。对于大规模的数据读取, HDFS 采用的是在存储时进行优化,也就是说在文件进入 HDFS 系统时候,就对较大体积的文件存储时就采用集中式存储的方式,使得未来的读取能够在一个文件一个连续的区域进行,从而节省寻址及复制时间。而对于小数据的读取, HDFS更多的做法是在把小规模的随机读取操作合并并对读取顺序进行排序,这样可以在一定程度上实现按序读取,提高读取效率。因此可以说, HDFS 更多是考虑到数据读取的批处理,而不是对单独命令的执行。
架构与基本存储单元
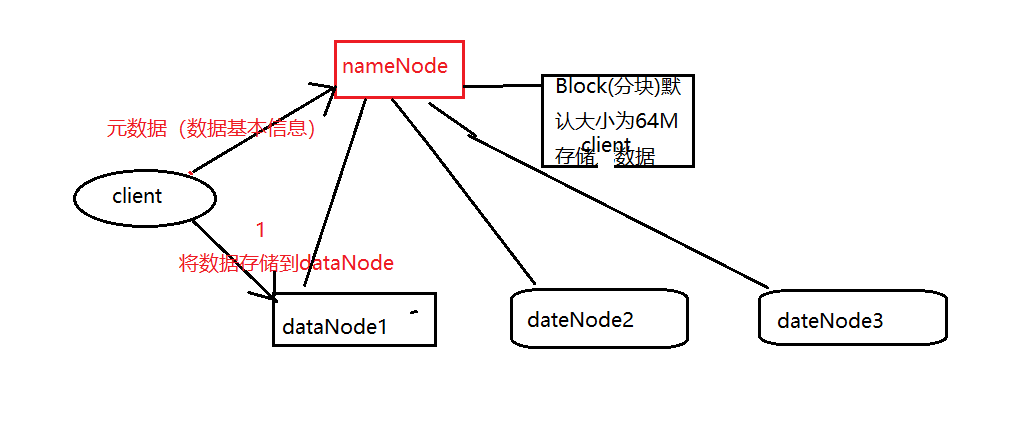
对于 HDFS 架构来说,一个 HDFS 基本集群包括两大部分,即 NameNode 与 DataNode节点,其作用是将管理与工作进行分离。
通常来说,一个集群中会有一个 NameNode 与若干个 DataNode。 NameNode 是一个集群的主服务器,主要是用于对 HDFS 中所有的文件及内容数据进行维护,并不断读取记录集群中 DataNode 主机情况与工作状态,并通过读取与写入镜像日志文件的方式进行存储。而 DataNode 是在 HDFS 集群中担任任务具体执行,是整个集群的工作节点,文件被分成若干个相同大小的数据块,分别存储在若干个 DataNode 上,DataNode 定时定期向集群内 NameNode 发送自己的运行状态与存储内容,并根据 NameNode发送的指令进行工作。

NameNode 负责接受客户端发送过来的信息,然后将文件存储信息位置发送给提交请求的客户端,由客户端直接与 DataNode 进行联系,进行部分文件的运算与操作。对于文件存储来说, HDFS 使用 Block(分块)来对文件的存储进行操作。对于传统磁盘存储来说,磁盘都有默认的存储单元,通常使用的是数据定义中的最小存储单元。 Block 是HDFS 的基本存储单元,默认大小是 64M,这个大小远远大于一般系统文件的默认存储大小。这样做的一个最大好处减少文件寻址时间。除此之外,采用 Block 对文件进行存储,大大提高了文件的灾难生存与恢复能力, HDFS还对已经存储的 Block 进行多副本备份,将每个 Block 至少复制到 3 个相互独立的硬件上。这样做的好处就是确保在发生硬件故障的时候,能够迅速的从其他硬件中读取相应的文件数据。而具体复制到多少个独立硬件上也是可以设置的。
数据存储位置与复制详解
同一节点上的存储数据
同一机架上不同节点上的存储数据
同一数据中心不同机架上的存储数据
不同数据中心的节点
HDFS 数据存放策略就是采用同节点与同机架并行的存储方式。在运行客户端的当前节点上存放第一个副本,第二个副本存放在于第一个副本不同的机架上的节点,第三个副本放置的位置与第二个副本在同一个机架上而非同一个节点。
运行时:

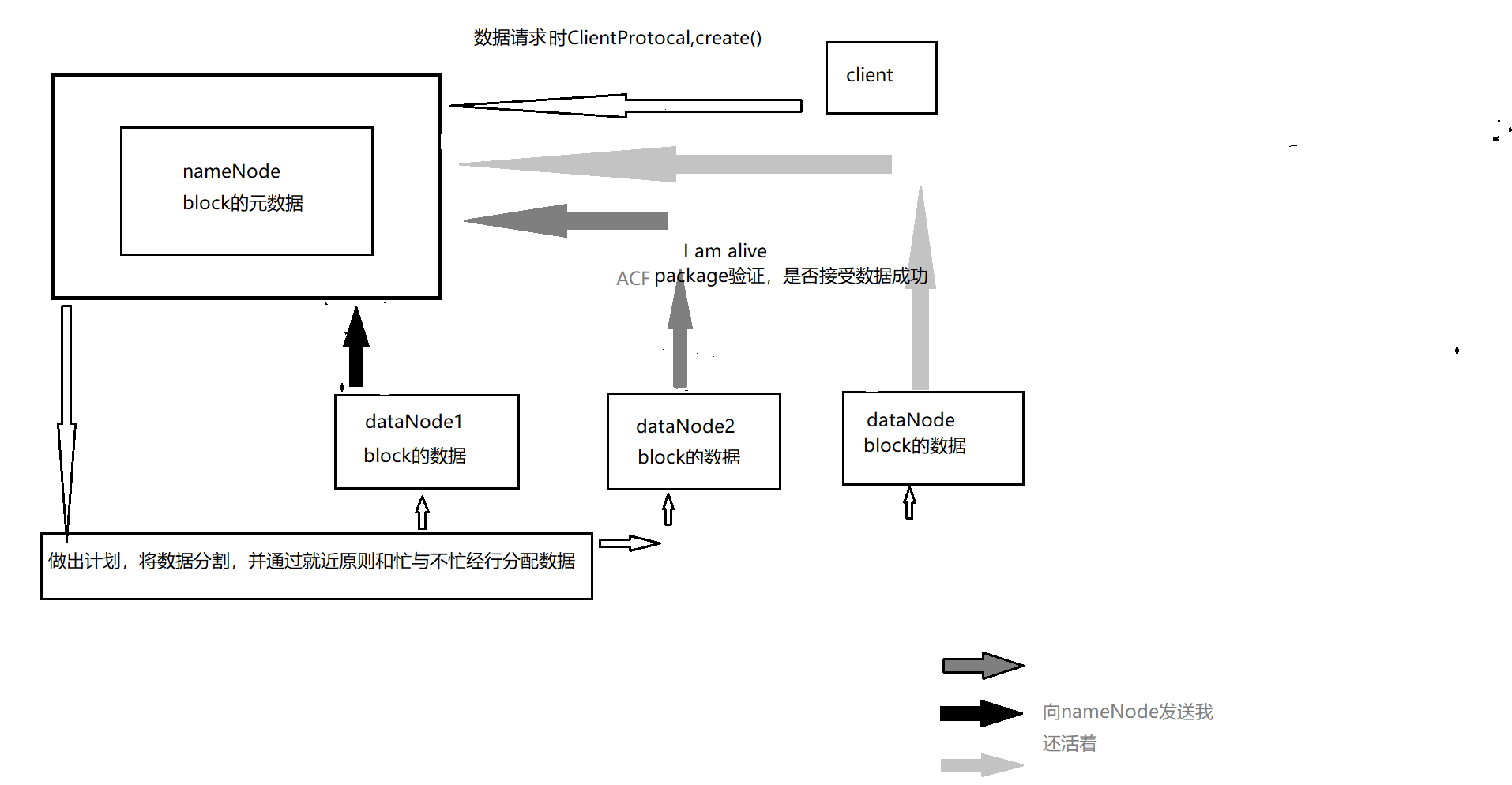
HDFS的读写流程:
读:
1.client客户端调用DistributedFileSystem.create()方法。
2.底层调用ClientProtical.create()方法,并创建文件的操作记录到editlog中,返回一个HDFSDateOutPutStream对象,底层时对DFSOutStream进行包装。
3.nameNode收到数据元(默认为128M),NameNode返回一个LocalBlock对象,建立数据流管道写数据块
4.建立管道后,HDFS客户端可以向管道流内写数据,它将数据切为一个个packet,然后按dataNode就近原则和,忙与不忙进行发送,dataNode。
5.dataNode成功接受后,通过ACK验证后向nameNode汇报,nameNode会更新数据节点的对应关系,以及I am alive
6.完成操作后,客户端关闭输出流
写:
写流程则相反。